欢迎关注,敬请点赞!
生态化反——hadhoop生态圈
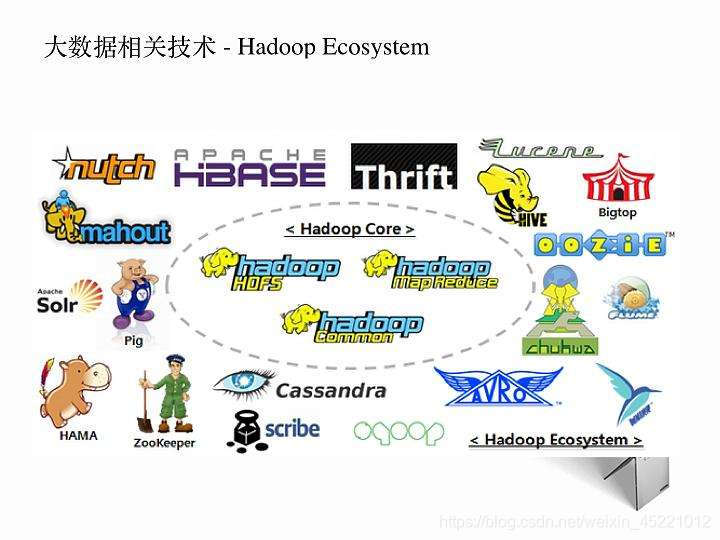
hadhoop动物园
返回顶部
apache开源的分布式计算框架(一系列产品)。
- HDFS(hadhoop distribute file system),很平滑,不够就加普通PC,冗余备份,(参考raid0 1 2 3 4 5) ,pd.read_hdf(),pandas也可以读
- MapReduce(YARN2.0),分布式计算框架,求和、字频;不能分布计算,序列式(圆周率、斐波那契数列);将不能分布式改成分布式。
- HIVE(模仿SQL,进行SQL查询的工具)
- HBase(NoSQL数据库)
- ZooKeeper
- Kafka(类似消息队列)
- lucene(全文检索)
- mahout(java实现的类似于sklearn的机器学习库)
spark
不包含HDFS文件系统,像pandas自己不带数据库,支持含hadhoop等各种文件系统。
- RDD
- spark-streaming(消息队列)
- 日志系统
现在来看,【贾跃亭的思路还是不错的,才气过剩,人品不足】。
欢迎关注,敬请点赞!
返回顶部
