HBase
Hbase的引言
什么是HBase
hbase是Apache 组织开源的顶级项目 distributed, scalable, big data store 产品
hbase是基于Hadoop的一个NoSQL产品 Column类型的NoSQL
hbase是Google BigTable的开源实现, 爬虫爬取的网页
hbase运行亿级数据查询时,效率可达到秒级,毫秒级 在线处理 实时的处理
NoSQL特点
1. 部分NoSQL In-Memory 内存型 (Redis)
2. Schema-Less NoSchema 弱格式 无格式
3. 杜绝表连接
4. 弱化事务,没有事务 (Redis有事务,MongoDB(4.x 没事务 4.x后有事务)
5. 搭建集群方便
NoSQL分类
1. key value 类型 redis
2. document 类型 mongodb
3. column 类型 HBase Cassandra
4. 图 类型 neo4j (金融 知识图谱)
Hbase存储的逻辑结构
mysql
t_user

HBase
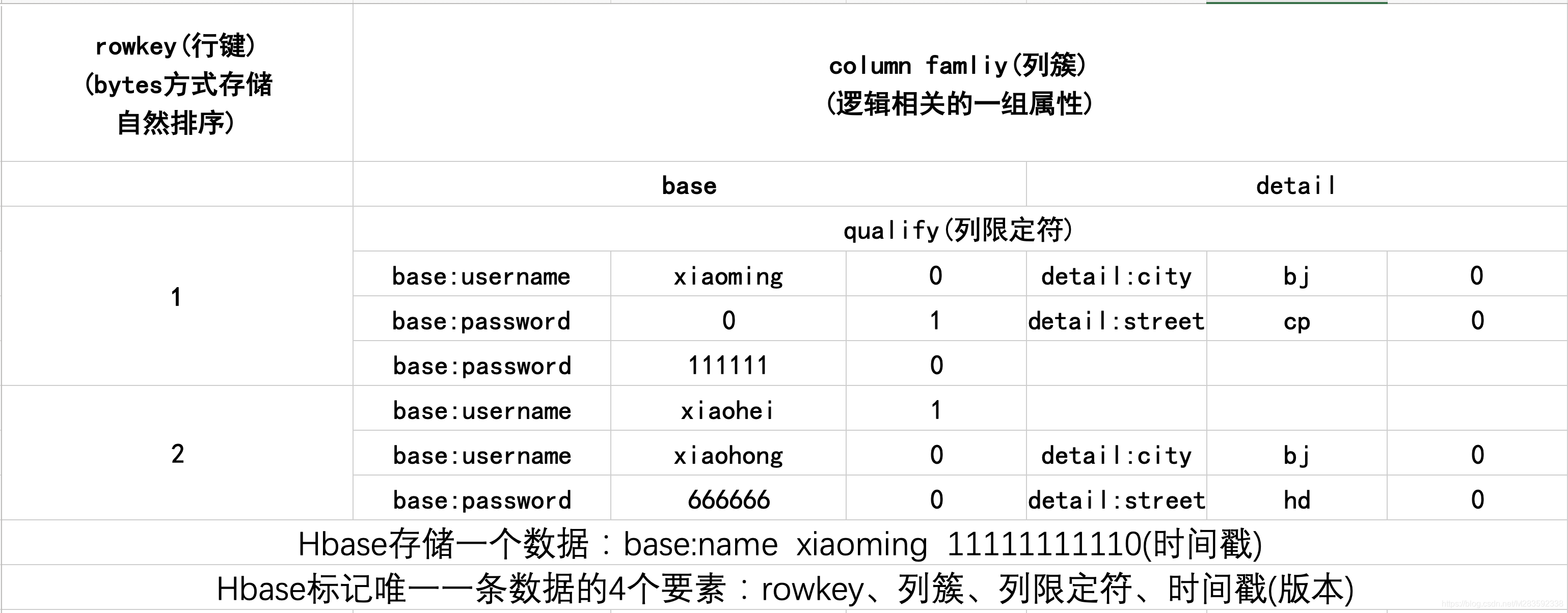
多版本的好处:修改速度快,直接新增一条新数据,给旧数据标记墓碑
Hbase伪分布式环境的搭建
Hmaster、 Hregionserver
1. linux服务器 ip 主机名 主机映射 防火墙 selinux ssh免密 jdk
2. hadoop安装
2.1 解压缩
2.2 6个配置文件
2.3 格式化
2.4 启动进程
3. 安装zookeeper
3.1 解压缩
3.2 配置conf/zoo.cfg
3.3 创建临时目录 data ---> myid文件(集群)
3.4 启动服务
4. hbase的安装
4.1 解压缩hbase
4.2 hdfs上创建 /hbase文件夹
hbase_home/data/tmp文件夹
4.3 修改hbase相关的配置文件
env.sh
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.7.0_71
hbase-site.xml
<property >
<name>hbase.tmp.dir</name>
<value>/opt/install/hbase-0.98.6-hadoop2/data/tmp</value>
</property>
<property >
<name>hbase.rootdir</name>
<value>hdfs://CentOSA:8020/hbase</value>
</property>
<property >
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>CentOSA</value>
</property>
4.4 修改
regionservers文件
CentOSA
4.5 替换hbase相关hadoop的jar
4.6 启动hbase
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
4.7 网络访问
http://CentOS:60010
bin/hbase shell
Hbase的shell命令
1. help 帮助命令
help '命令名字'
2. hbase中数据库的概念
namespace
2.1 显示所有的数据库
list_namespace
默认 default
hbase
2.2 显示当前数据库中所有的表
list_namespace_tables 'hbase'
2.3 创建一个数据库
create_namespace 'test'
2.4 描述数据库
describe_namespace 'test'
2.5 修改数据库
alter_namespace
2.6 删除数据库
drop_namespace 'test'
3. 创建hbase中的表【重点】
3.1 基本的建表方式 【默认default库中】
create 't1','cf1'
3.2 创建多个列簇【默认default库中】
create 't1','cf1','cf2'
3.3 指定表所属的数据库
create 'test:t1','cf1'
3.4 详细描述列簇的相关属性
create 'test:t2',{NAME=>'cf1',VERSIONS=>2},{NAME=>'cf2'}
4. 描述表
describe 'test:t1'
5. 修改表
alter 'test:t2',{NAME=>'cf2',VERSIONS=>2}
6. 删除表
disable 'test:t2'
drop 'test:t2'
7. 失效 生效表相关命令
enable disable
enable_all disable_all
is_enable is_disable
8. 判断表是否存在
exists
9. 表的查找命令
list 'namespace:t.*'
10. 插入数据
put 't1',’rowkey‘,'family:qualify','value'
put 'namespace:t1',’rowkey‘,'family:qualify','value'
11. 删除数据
delete 'namespace:t1' ,'rowkey','family:qualify','timestamp'
12. 全表扫描
scan '表名'
scan 'namespace:tb1', {STARTROW => '20170521_10001',STOPROW => '20170521_10003'}
scan 'test:user',{STARTROW=>'001',STOPROW=>'004'}
不包括stoprow的值
13. 某条数据的查询
get 'test:user','001'
get 'test:user','001','base:name'
HBase 集群搭建
1.时间同步集群
CentOS 作为时间同步服务器 主节点
1. yum install ntp 三台机器
2. service ntpd start 三台机器
chkconfig ntpd on
3. 服务器节点 主节点
ntpdate -u 202.112.10.36
vi /etc/ntp.conf
restrict 192.168.111.0 mask 255.255.255.0 nomodify notrap
# 中国这边最活跃的时间服务器 : http://www.pool.ntp.org/zone/cn
server 210.72.145.44 perfer # 中国国家受时中心
server 202.112.10.36 # 1.cn.pool.ntp.org
server 59.124.196.83 # 0.asia.pool.ntp.org
# 允许上层时间服务器主动修改本机时间
restrict 210.72.145.44 nomodify notrap noquery
restrict 202.112.10.36 nomodify notrap noquery
restrict 59.124.196.83 nomodify notrap noquery
# 外部时间服务器不可用时,以本地时间作为时间服务
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
service ntpd restart
4. client端
vi /etc/ntp.conf
server 192.168.111.41 #这里指的是ntp服务的ip 192.168.206.130
restrict 192.168.111.41 nomodify notrap noquery
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
5. 三台机器 service ntpd restart
6. 从节点同步主节点时间 ntpdate -u 192.168.184.16
adjust time server 192.168.19.10 offset -0.017552 sec
5. date命令查看处理结果
2.Hadoop集群搭建
HDFS集群
YARN集群
3. Zookeeper集群
1. 解压缩
2. 创建数据文件夹
zookeeper_home/data
3. 修改配置文件
conf/zoo.cfg
dataDir
server.0
4. 在data文件夹中创建 myid文件 0 1 2
5. 启动服务
4. HBase集群
1. 准备:hbase_home data/tmp logs目录中的内容清空
hdfs 上面 hbase目录清空
2. 修改hbase_home/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71
export HBASE_MANAGES_ZK=false
3. hbase-site.xml
<property >
<name>hbase.tmp.dir</name>
<value>/opt/install/hbase-0.98.6-hadoop2/data/tmp</value>
</property>
<property >
<name>hbase.rootdir</name>
<value>hdfs://CentOSA:8020/hbase</value>
</property>
<property >
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>CentOSA,CentOSB,CentOSC</value>
</property>
4. regionservers
CentOSA
CentOSB
CentOSC
5. 启动hbase
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
HBase JAVA API
# java访问HBase的核心API
Configruation HBase相关的配置
Htable HBase中的表
Put 插入数据
Get 查询数据
Scan 扫描数据
BytesUtil 字节处理
Maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.6-hadoop2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>0.98.6-hadoop2</version>
</dependency>
方法
| 对象 | 作用 | 基本用法 |
|---|---|---|
| Configruation | Hbase相关的配置文件 | conf.set(“key”,“value”); |
| HTable | Hbase中的表 | 表相关的操作都是HTable完成 |
| Put | HBase中插入数据 | Put put = new Put(rowkey) put.add HTable.put(put) |
| Delete | HBase中的删除操作 | Delete delete = new Delete(rowkey) HTable.delete(delete) |
| Get | HBase查询单条数据 | Get get = net Get(rowkey) HTable.get(get) —> Result |
| Result | 单行数据 | Result – Cells — Cell — cloneFamily cloneQualify cloneValue |
| Scan | 表的扫描 | ResultScanner —> Result |
HBase中的过滤器
-
行键相关的过滤器
1.比较行键值的大小 Filter filter1 = new RowFilter(CompareFilter.CompareOp.GREATER, new BinaryComparator(Bytes.toBytes("0003"))); scan.setFilter(filter1); 2. 比较行键按照特定的规则设计 Filter filter1 = new PrefixFilter(Bytes.toBytes("000")); scan.setFilter(filter1); -
列簇相关的筛选
1. 只要base列簇相关的数据 Filter filter1 = new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("base"))); scan.setFilter(filter1); -
限定符相关筛选
Filter filter1 = new QualifierFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("age"))); scan.setFilter(filter1); -
值的筛选
Filter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator("1") ); scan.setFilter(filter); -
列簇中的数据进行筛选
SingleColumnValueFilter filter = new SingleColumnValueFilter( Bytes.toBytes("base"), Bytes.toBytes("sex"), CompareFilter.CompareOp.EQUAL, new SubstringComparator("male")); filter.setFilterIfMissing(true); //filter.setFilterIfMissing(false); //符合要求的数据 password=123456 //column 中不包含password限定符 查询出来 scan.setFilter(filter); //同时要排除password 限定符 SingleColumnValueExcludeFilter filter = new SingleColumnValueExcludeFilter( Bytes.toBytes("base"), Bytes.toBytes("password"), CompareFilter.CompareOp.NOT_EQUAL, new SubstringComparator("66666")); filter.setFilterIfMissing(true); //filter.setFilterIfMissing(false); //符合要求的数据 password=123456 //column 中不包含password限定符 查询出来 scan.setFilter(filter); -
FilterList
设置多个过滤器 同时生效 FilterList filterList = new FilterList(); Filter filter1 = new PrefixFilter(Bytes.toBytes("000")); SingleColumnValueFilter filter2 = new SingleColumnValueFilter( Bytes.toBytes("base"), Bytes.toBytes("password"), CompareFilter.CompareOp.EQUAL, new SubstringComparator("123456")); filter2.setFilterIfMissing(true); filterList.addFilter(filter1); filterList.addFilter(filter2); scan.setFilter(filterList);
HBase中列簇相关的属性
1. 创建HBase表
create 'table_name',{NAME=>'',VERSIONS=>''}
2. Hbase列簇的常见属性
# 列簇的名字
NAME='xxxxx'
# 列簇对应限定符 能存几个版本的数据
VERSIONS => '1'
# TTL Time To Live
指定的是cell中的数据,存储在HBase中的存活时间 'FOREVER'
TTL => 100
# 指定HBase上存储的数据 是否 启动压缩
COMPRESSION => 'NONE'
COMPRESSION => 'snappy'
# 列簇中的数据,存储在内存中,提高查询效率 (默认关闭)
IN_MEMORY => 'false’
# 缓存 列簇部分数据,从而提高查询效率
BLOCKCACHE => 'true'
# Block是列簇中存储数据的最小单位
BLOCKSIZE => '65536'
调整大 顺序查询 需求高
调整小 随机查询 需求高
# 提高查询效率
BLOOMFILTER 布隆过滤
HBase 体系结构
1.RegionServer
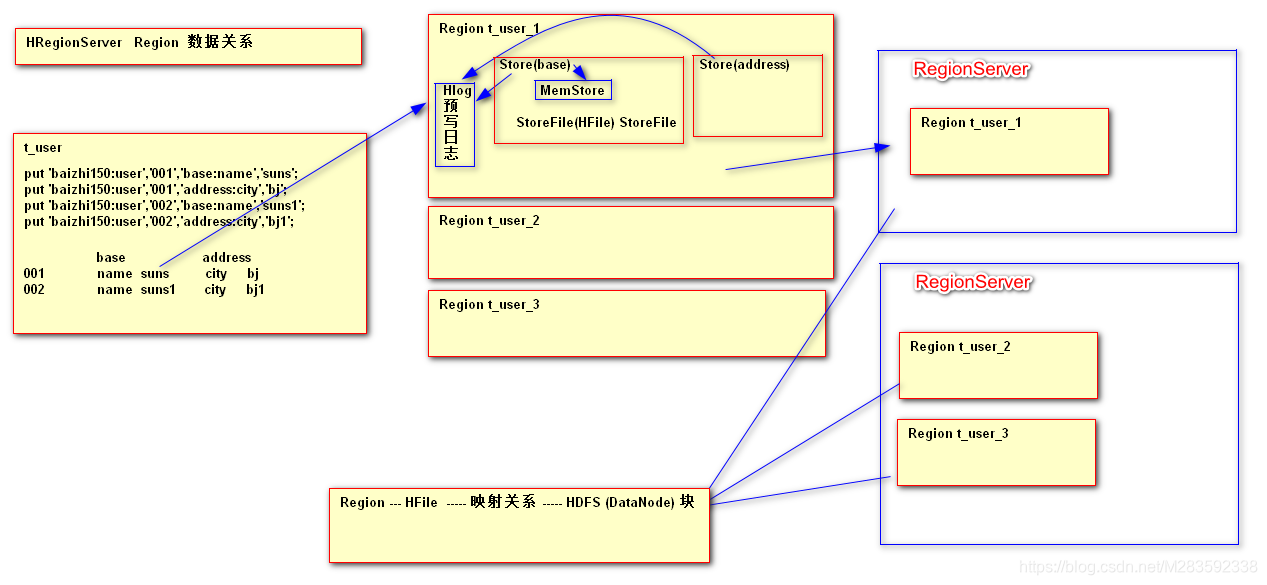
2. HMaster作用
1. HRegionServer 集群是否健康
2. Region---RegionServer分配
3. 新Region加入后,负载均衡
3. Zookeeper作用 【重点】
1. 管理HMaster的高可用
2. 存储了HBase中非常重要的信息 meta信息
rowkey 范围 ---- region ---- RegionServer(健康)
4. HBase compact 和 split
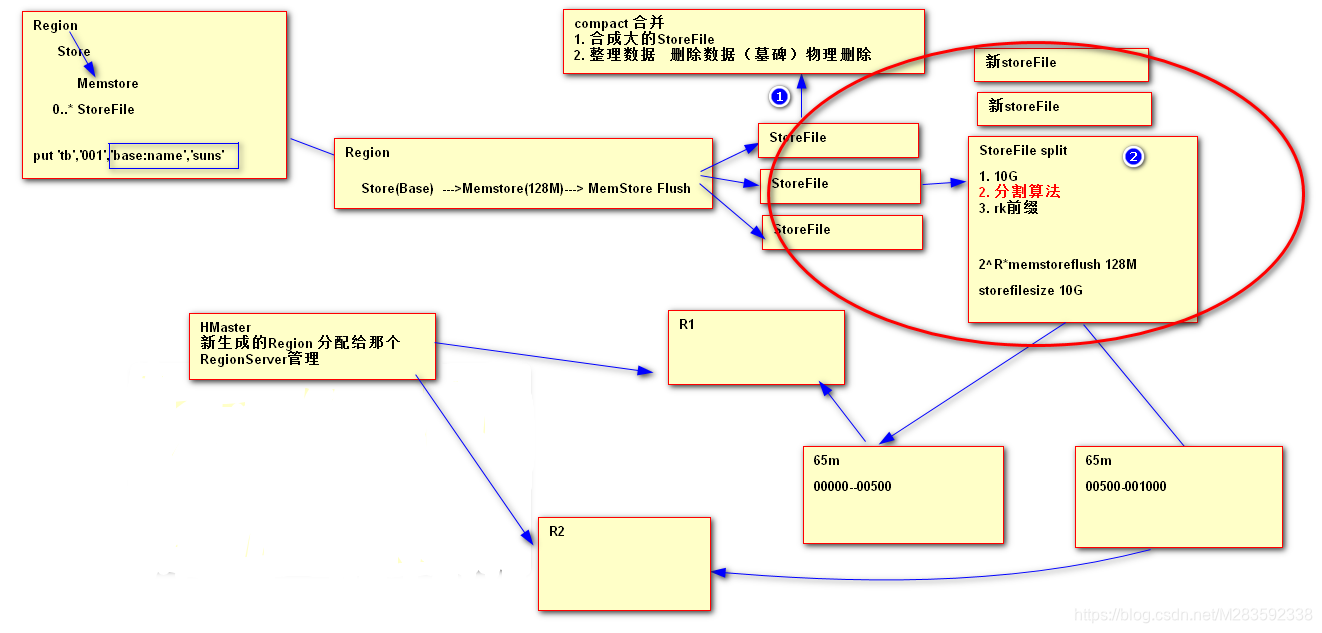
RowKey设计
1. HBase相关的查询操作,95%上都是对RowKey查询。
2. 设计过程
2.1 复合
2.2 查询内容作为rowkey组成
3. rowkey 64K 10--100字节唯一
4. rowkey结合自己的实际需求
4.1 区域查询多,建议 rowkey 连续
4.4 区域查询少,散列 hash ---> 加密、UUID
System.out.println(UUID.randomUUID().toString());
String rowkey = "xx_male_001";
String result = DigestUtils.md5Hex(rowkey);
System.out.println(result);
