绪论
目前打算学习一下计算机组成原理的相关内容,本专栏主要放一些学习过程中觉得重要的或者一些需要记忆的知识点。对于冯诺依曼结构的工作原理等知识这里不再赘述。
计算机系统的性能评价
计算机性能评价指标主要包括非时间指标和时间指标。
非时间指标主要有:机器字长、总线宽度、主存容量和存储带宽。
(1)机器字长
机器字长指机器一次能处理的二进制位数。
其主要由加法器和寄存器的位数决定;一般与内部寄存器的位数相等(字长);
字长越长,表示的数据范围越大,精确度越高;目前常见的有32位和64位字长。
(2)总线宽度
总线宽度指数据总线一次能并行传送的最大信息的位数。一般指运算器与存储器之间的数据总线位数。
某些计算机内部和外部总线宽度不一致:例如8088、80386SX外部总线宽度为8位,内部总线宽度为16位(目的是为了更好的兼容)。
(3)主存容量和存储带宽
主存容量:是指一台计算机主存所包含的存储单元总数。
存储带宽:指单位时间内与主存交换的二进制信息量,常用单位B/s(字节/秒)。
影响存储带宽的指标包括数据位宽和数据传输速率。
时间指标包括:主频f/时钟周期T,外频、倍频、CPI、MIPS、CPU时间等。
(1)主频f/时钟周期T,外频、倍频
主频f指CPU内核工作的时钟频率,即CPU内数字脉冲信号振荡的速率,与CPU实际的运算能力之间不是唯一的、直接关系。
时钟周期T是主频f的倒数,也称节拍器,是计算机中最基本、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
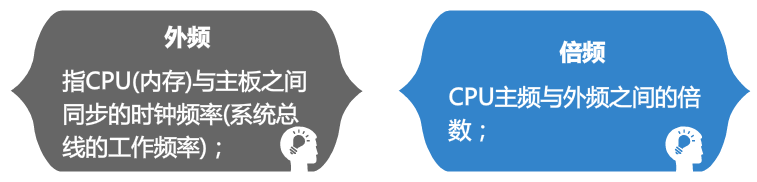
其中:主频=外频×倍频。
例如:Pentium 4 2.4G CPU主频-> 2400M=133M(外频)×18(倍频); 如何超频?
(2)CPI(Clock cycles Per Instruction)
CPI指执行一条指令(平均)需要的时钟周期数(即T周期的个数)
CPI=程序中所有指令的时钟周期数之和/程序指令总数=sigma(程序中各类指令的CPI×程序中该类指令的比例)
IPC(Instruction per Clock):每个时钟周期内执行的指令条数(并行)
实际上频率和IPC在真正影响CPU性能。
准确的CPU性能判断标准应该是:CPU性能=IPC×频率(MHz时钟速度)
(3)MIPS(Million Instructions Per Second)
MIPS指每秒钟CPU能执行的指令总条数(单位:百万条/秒)

(4)CPU时间
CPU时间指执行一段程序所需的时间(CPU时间+I/O时间+存储访问时间+各类排队时延等)。
CPU时间=程序中所有指令的时钟周期数之和×T=程序中所有指令的时钟周期数之和/f
计算方法主要有以下两种:

时间指标的应用思考

**
计算机性能测试
测试原理:计算机系统中配置了大量的传感器和寄存器,系统运行的相关参数保存在对应的寄存器中;测试程序通过读取相应寄存器的值得到系统运行的状况;之后通过图形/数据方式显示获取的状态数值。
常见的测试工具
CPU测试工具:CPUMark、SysID、Hot CPU Tester
显卡测试工具:3DMark、N-Bench2、FurMark
硬盘测试工具:Hard Disk Speed、Disk Benchmark、IOmeter、HDD Temperature Pro
内存测试工具:CTSPD、Memory Speed、Memory Transfer Timing Utility
其他综合测试工具:鲁大师
Amdahl定律
Gene Amdahl,计算领域的早期先锋之一,对提升系统某一部分性能所带来的的效果做出了简单却有见地的观察,这个观察称为Amdahl定律。该定律的主要思想是,当我们对系统的某一部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。
若系统执行某应用程序需要时间为Told,假设系统某部分所需执行时间与该时间的比例为α,而该部分性能提升比例为k。即该部分初始所需时间为αTold,现在所需时间为(αTold)/k。因此,总的执行时间应为:
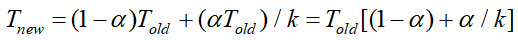
由此,可以计算加速比S=Told/Tnew为
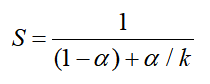
举个例子,考虑这样一种情况,系统的某个部分初始耗时比例为60%(α=0.6),其加速比例因子为3(k=3)。则我们可以获得的加速比为1/[0.4+0.6/3]=1.67倍。虽然我们对系统的一个主要部分做出了重大改进,但是获得的系统加速比却明显小于这部分的加速比。这就是Amdahl定律的主要观点:要想显著加速整个系统,必须提升全系统中相当大的部分的速度。
并发和并行
这一部分我将只记下基本概念,对于更深的知识之后会专门写博客。
线程级并发
构建在进程这个抽象之上,我们能够设计出同时有多个程序执行的系统,这就导致了并发,使用线程,我们甚至能够在一个进程中执行多个控制流。很早以前,计算机系统就开始有了对并行执行的支持。传统意义上,这种并发执行只是模拟出来的,是通过使一台计算机在它正在执行的进程间快速切换来实现的。这种并发形式允许多个用户同时与系统交互,例如多人想要从一个Web服务器获取页面。它还允许一个用户同时从事多个任务,例如在一个窗口中开启Web浏览器,在另一个窗口中运行字处理器,同时又播放音乐。在以前,即使处理器必须在多个任务间切换,大多数实际的计算也都是由一个处理器来完成的。这种配置称为单处理器系统。
当构建一个由单操作系统内核控制的多处理器组成的系统时,我们就得到了一个多处理器系统。随着多核处理器和超线程的出现,这种系统才变得常见。(下边几个图出自《深入理解计算机系统》)
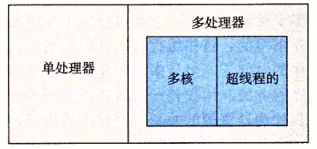
多核处理器是将多个CPU(称为“核”)集成到一个集成电路芯片上,下图描述的是一个典型多核处理器的组织结构,其中微处理器芯片有4个CPU核,每个核都有自己的L1和L2高速缓存,其中的L1高速缓存分为两部分–一个保存最近取到的指令,另一个存放数据。这些核共享更高层次的高速缓存,以及到主存的接口。

超线程,有时称为同时多线程,是一项允许一个CPU执行多个控制流的技术。它涉及CPU某些硬件有多个备份,比如程序计数器和寄存器文件,而其他的硬件部分只有一份,比如执行浮点算术运算的单元。常规的处理器需要大约20000个时钟周期做不同线程间的转换,而超线程的处理器可以在单个周期的基础上决定要执行哪一个线程。这使得CPU能够更好地利用它的处理资源。比如,假设一个线程必须等到某些数据被装在到高速缓存中,那CPU就可以继续去执行另一个线程。举例来说,Intel Core i7处理器可以让每个核执行两个线程,所以一个4核的系统实际上可以并行地执行8个线程。
之后会专门开篇记录并发学习过程中的重要知识。
指令级并行
在较低的抽象层次上,现代处理器可以同时执行多条指令的属性称为指令级并行。早期的微处理器,如1978年的Intel 8086,需要多个(通常为3到10个)时钟周期来执行一条指令。最近的处理器可以保持每个时钟周期2~4条指令的执行速率。但其实每条指令从开始到街上需要长得多的时间,大约20个或者更多的周期,但是处理器使用了分厂多的聪明技巧来同时执行多达100条指令(流水线)。如果处理器可以达到比一个周期一条指令更快的执行速率,就称之为超标量处理器。大多数现代处理器都支持超标量操作。
单指令、多数据并行
在最低层次上,许多现代处理器拥有特殊的硬件,允许一条指令产生多个可以并行指向的操作,这种方式称之为单指令、多数据,即SIMD并行。例如,较新几代的Intel和AMD处理器都具有并行地对8对单精度浮点型做加法的指令。
提供这些SIMD指令多是为了提高处理影像、声音和视频数据应用的执行速度。
计算机系统中抽象的重要性
抽象的使用是计算机科学中最为重要的概念之一。例如,为一组函数规定一个简单的应用程序接口(API)就是一个很好的编程习惯,程序员无需了解它的内部的工作便可以使用这些代码。
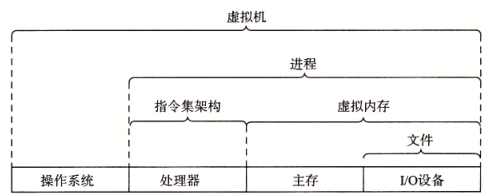
如上图所示,在处理器里,指令集架构提供了对实际处理器硬件的抽象。使用这个抽象,机器代码程序表现得就好像运行在一个一次只执行一条指令的处理器上。底层的硬件远比抽象描述的要复杂精细,它并行地执行多条指令,但又总是与那个简单有序的模型保持一致。只要执行模型一样,不同的处理器实现也能执行同样的机器代码,而又提供不同的开销和性能。
