数据操纵语言(DML)
1、列的查询
基本SELECT语句:SELECT <列名>,... ... FROM <表名>; 查询某列数据;当要查询所有列时,用 * 代表全部列。
设定别名(可以是中文,需要双引号""):
SELECT <列名> AS <别名>,
... ...
FROM <表名>
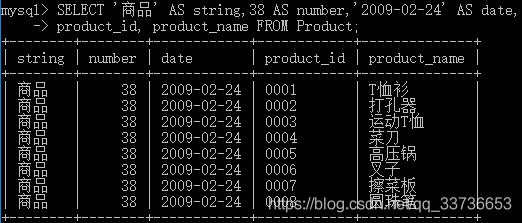
书写常数:
SELECT <字符串常数> AS <列名>,
<数字常数> AS <列名>,
<日期常数> AS <列名>
FROM <表名>
如下图 string、number、date:
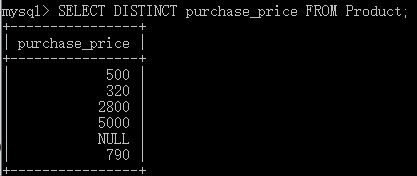
去除重复行:在 SELECT 中使用 DISTINCT 实现。
SELECT DISTINCT <列1>,
<列2>,
... ...
FROM <表名>
注意:NULL也会作为一类数据,会合并该列其它 NULL 的数据。
WHERE语句:通过WHERE 子句来指定查询数据的条件。执行顺序:先通过 WHERE 子句查询出符合指定条件的记录,再选取出 SELECT 语句指定的列。
SELECT <列名>,... ...
FROM <表名>
WHERE (条件表达式);
注释:单行注释 -- 、多行注释 /* */ .
1.1 运算符
+、-、*、/ 称为算术运算符。
SELECT <列名>,... ... , <运算操作> FROM <表名>
1、可以用括号提升运算表达式的优先级;
2、所有包含 NULL 的计算,结果肯定是 NULL。
-
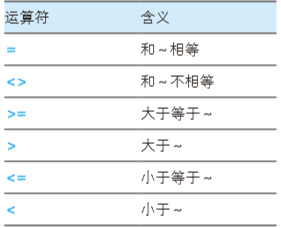
比较运算符
注意:- 对字符串使用比较运算符时的注意事项: 比较的是字典排序顺序。
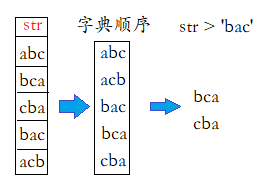
- 不能对NULL使用比较运算符
- 对字符串使用比较运算符时的注意事项: 比较的是字典排序顺序。
-
逻辑运算符
NOT:对条件取反。
AND:“并且”的意思。在其两侧的查询条件都成立时,整个查询条件才成立。
OR:“或者”的意思。在其两侧的查询条件任意一个成立时,整个查询条件就成立。
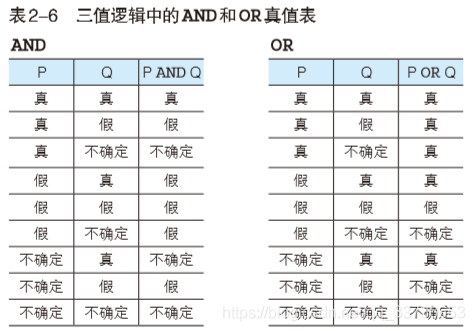
MYSQL使用的是——三值逻辑
TRUE、FALSE、UNKNOWN(不确定)
2、聚合与排序
2.1 聚合函数
常用的5个函数:

- 通常,聚合函数会对
NULL以外的对象进行汇总。 COUNT( * )会得到包含 NULL 的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数。MAX/MIN函数几乎适用于所有数据类型的列。SUM/AVG函数只适用于数值类型的列。- 在聚合函数的参数中使用
DISTINCT,可以去掉重复数据。
2.2 分组
- 聚合键中包含NULL时,在结果中会以“不确定”行(空行)的形式表现出来。
- 使用聚合函数和GROUP BY子句时需要注意以下4点:
① 只能写在SELECT子句之中
② GROUP BY子句中不能使用SELECT子句中列的别名
③ GROUP BY子句的聚合结果是无序的
④ WHERE子句中不能使用聚合函数
常见问题
- 使用
GROUP BY子句时,SELECT子句中不能出现聚合键之外的列名。 - 在
GROUP BY子句中不能使用SELECT子句中定义的别名。 GROUP BY子句显示的结果是无序的。- 只有
SELECT子句和HAVING子句(以及ORDER BY子句)中能够使用聚合函数。
2.3 为聚合结果指定条件
HAVING:对聚合函数结果指定条件。构成要素:常数,聚合函数,GROUP BY 子句中指定列名(聚合键)。
SELECT <列名1>, ... ...
FROM <TABLE>
GROUP BY <列名1>, ... ...
HAVING <分组结果对应的条件>
例子:可以在 HAVING 后使用SELECT 中的别名。

注意
- WHERE 子句 = 指定行所对应的条件
- HAVING 子句 = 指定组所对应的条件
- 在 WHERE 子句和HAVING 子句中都可以使用的条件,最好写在WHERE子句中。(因为可以减少排序行数和创建索引,以提高性能。)
2.4 排序
数据库查询结果的排列顺序是随机的。如需对查询结果进行排序,使用下述关键字:ORDER BY:对列进行排序(默认是升序ASC ),如需降序排序用关键字DESC。
- 在
ORDER BY子句中可以使用SELECT子句中定义的别名。 ORDER BY子句中可以使用SELECT中的列,也可以使用存在于表中、但并不包含在 SELECT 子句之中的列。- 在
ORDER BY子句中可以使用SELECT子句中未使用的列和聚合函数。 - 在
ORDER BY子句中不要使用列编号。
查询语句的书写排序:
查询语句的执行顺序:
3、数据的更新
3.1 插入语句
INSERT INTO <表名> (列1, 列2, 列3, ……)
VALUES (值1, 值2, 值3, ……);
其中 (列1, 列2, 列3, ……)称为列清单,(值1, 值2, 值3, ……)称为值清单。插入数据时,两个的列数要保持一致,否则会报错。
- 原则上,执行一次INSERT语句应插入一行数据。

插入语句中省略列名
对表进行全列 INSERT 时,可以省略表名后的列清单。这时 VALUES 子句的值会默认按照从左到右的顺序赋给每一列。
插入默认值
- 显式方法:用
DEFAULT代替值; - 隐式方法:在列清单和值清单中省略该列;
省略INSERT语句中的列名,就会自动设定为该列的默认值(没有默认值时会设定 为NULL)。
从其他表中复制数据
插入查询得到的数据:
INSERT INTO <表1> (<列1><列2>, ... ...)
SELECT <列1>,<列2>, ... ...
FROM <表2>
INSERT语句的SELECT语句中,可以使用WHERE子句或者GROUP BY子句等任何SQL语法(但使用ORDER BY子句并不会产生任何效果)。
3.2 删除数据
①DROP TABLE 语句可以将表完全删除 ;
②DELETE 语句会留下表(容器),而删除表中的全部数据。
语法一:DELETE FROM <表名> 和 DELETE FROM <表名> WHERE
- DELETE语句的删除对象并不是表或者列,而是记录(行)。
- 可以通过
WHERE子句指定对象条件来删除部分数据。 - 与
SELECT语句不同的是,DELETE语句中不能使用GROUP BY、HAVING和ORDER BY三类子句.
语法二: TRUNCATE <表名>
- 只能删除表中全部数据,不能使用
WHERE。 - 可以缩短执行时间。
3.3 更新数据
UPDATE <表名>
SET <列名> = <表达式>;
将列中的所有值更新为新的值。——也会将列中 NULL 值更新为新值。
指定条件的 UPDATE 语句:
UPDATE <表名>
SET <列名> = <表达式>
WHERE <条件>;
使用UPDATE 语句可以将值清空为 NULL(但只限于未设置NOT NULL约束的列)。
多列更新
# 方式一
UPDATE <表名>
SET <列名1> = <值1> ,
<列名2> = <值2>
... ...
WHERE <条件>;
# 方式二
UPDATE <表名>
SET (<列名1>, <列名2>, ...) = (<值1> , <值2>,...)
WHERE <条件>;
- 需要注意的是第一种方法——使用逗号将列进行分隔排列,这一方法在所有的DBMS 中都可以使用。但是第二种方法——将列清单化(元组),这一方法在某些 DBMS中是无法使用的。
4、复杂查询
4.1 视图
表中存储的是实际数据,而视图中保存的是从表中取出数据所使用的SELECT语句。
优点:
- 视图无需保存数据,可以节省存储设备的容量。
- 可以将频繁使用的
SELECT语句保存成视图,就不用每次都重新书写SELECT语句。
创建视图:
# SELECT 中列与视图列要一一对应
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
AS
<SELECT 语句>
注意:可以使用多重视图,但应该避免在视图的基础上创建视图。
限制:
- 定义视图时不能使用ORDER BY 子句。(PostgreSQL例外)
- 如果定义视图的 SELECT 语句能够满足某些条件,那这个视图就可以被更新。具有代表性的条件有:
- ① SELECT 子句中未使用 DISTINCT
- ② FROM 子句中只有一张表
- ③ 未使用 GROUP BY 子句
- ④ 未使用 HAVING 子句。
(视图和表需要同时进行更新,因此通过汇总得到的视图无法进行更新。)
删除视图:
DROP VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
4.2 子查询
子查询是一次性视图(SELECT语句)。与视图不同,子查询在`SELECT`语句执行完毕之后会消失。
使用方法 :将用来定义视图的 SELECT语句直接用于 FROM 子句当中。SELECT 的嵌套结构(先内再外)。
可以使用嵌套结构添加子查询层数。(但是,随着子查询嵌套层数的增加,SQL 语句会变得越来越难读懂, 性能会越来越差。)
4.2.1 标量子查询
标量子查询就是返回单一值的子查询。
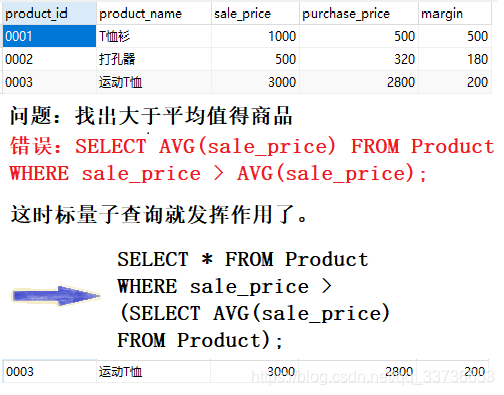
使用地方: 能够使用常数或者列名的 地方,无论是 SELECT 子句、GROUP BY 子句、HAVING 子句,还是 ORDER BY 子句,几乎所有的地方都可以使用。
注意事项
- 该标量子查询绝对不能返回多行结果。
4.2.2 关联子查询
在细分的组内进行比较时,需要使用关联子查询。
- 关联子查询会在细分的组内进行比较时使用。
- 关联子查询和
GROUP BY子句一样,也可以对表中的数据进行切分。 - 关联子查询的结合条件如果未出现在子查询之中就会发生错误。

5、函数、谓词、CASE表达式
5.1 函数
新数据类型:NUMERIC (全体位数,小数位)
算术函数
ABS(数值):绝对值MOD(被除数,除数):求余数ROUND (对象数,小数保留位数):保留小数位
字符串函数
- 拼接函数: MYSQL:
CONCAT ( )、 SQL Server:+、 其它:|| LENGTH (字符串):字符串长度LOWER (字符串):英文大写转小写UPPER (字符串):英文小写转大写REPLACE (字符串对象,替换前字符,替换字符):替换字符中某字符(三者中有一NULL就无法替换)。SUBSTRING (对象字符串 FROM 截取的起始位置 FOR 截取的字符数):截取字符串
日期函数
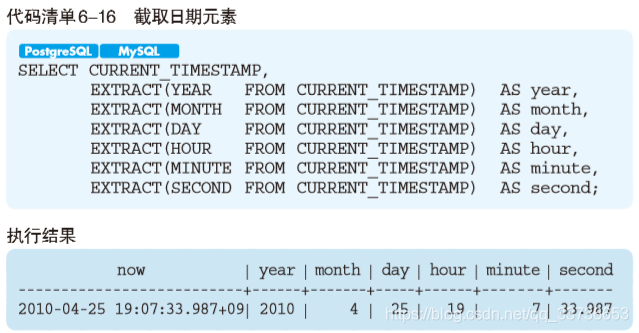
CURRENT_DATE:获取当前日期(无时间)[SQL Server]CURRENT_TIME:获取当前时间 [SQL Server]CURRENT_TIMESTAMP:获取当前日期和时间EXTRACT(日期元素 FROM 日期):截取日期元素,即年、月、时、分(返回数值类型)[SQL Server]
转换函数
CAST(转换前的值 AS 想要转换的数据类型):转换某个值的数据类型COALESCE(数据1,数据 2,数据 3……):将 NULL 转换成其它值
谓词:*谓词是需要满足返回值是真值的函数。
LIKE:字符串的部分一致查询(%(n个任意字符)、( _ 任意一个字符));BETWEEN:范围查询(包含临界值)IS NULL、IS NOT NULL:判断是否为NULLIN 、 NOT IN:简化多个 OR 的谓词- 在使用 IN 和NOT IN 时是无法选取出 NULL 数据。
- 能够将表和视图作为 IN 的参数。
- 可以使用子查询作为参数
EXISTS 、NOT EXISTS:判断是否存在满足某种条件的记录- 通常指定关联子查询作为EXIST的参数;
- 作为EXIST参数的子查询中经常会使用
SELECT *;

5.2 CASE表达式
(条件)分支函数。可以分为简单CASE表达式和搜索CASE表达式(包含了简单表达式的所有功能)。
搜索表达式:
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
... ...
ELSE <表达式>
END
可以使用 CASE 表示式实现行列转换:

简单表达式:简化书写,对CASE表达式求值,再对该值进行筛选
CASE <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
... ...
ELSE <表达式>
END
5.3 集合运算
集合运算,是对满足同一规则的记录进行的加减等四则运算。
5.3.1 表的加减法(增减行数)
UNION(并集) :进行记录加法运算的集合运算符。UNION 后面添加 ALL 选项,可以包含重复行的集合运算。
UNION 等集合运算符通常都会除去重复的记录。
注意事项
- 作为运算对象的记录的列数必须相同
- 作为运算对象的记录中列的类型必须一致
- 可以使用任何SELECT语句,但ORDER BY子句只能在最后使用一次
INTERSECT(交集) :选取两个记录集合中公共部分。[ MYSQL ]
EXCEPT(差集) :进行减法运算的集合运算符。[ MYSQL ]
