Pytorch官方实现
首先由引入相关的库
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url定义了一个可以从外部引用的字符串列表:
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]It is a list of strings defining what symbols in a module will be exported when
from <module> import *is used on the module.它是一个字符串列表,定义在模块上使用from<module>import*时将导出模块中的哪些符号。
model_urls这个字典是预训练模型的下载地址:
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}定义VGG类(继承nn.Module类):
class VGG(nn.Module):
定义__init__,初始化feature,num_classes, init_weights变量:
def __init__(self, features, num_classes=1000, init_weights=True):"__init__" is a reserved method in python classes. It is known as a constructor in object-oriented concepts. This method called when an object is created from the class and it allows the class to initialize the attributes of a class.
“初始化”是python类中的一个保留方法。它在面向对象的概念中被称为构造器。当从类创建对象时调用此方法,它允许类初始化类的属性。
self
self represents the instance of the class. By using the “self” keyword we can access the attributes and methods of the class in python. It binds the attributes with the given arguments.
The reason you need to use self. is because Python does not use the @ syntax to refer to instance attributes. Python decided to do methods in a way that makes the instance to which the method belongs be passed automatically, but not received automatically: the first parameter of methods is the instance the method is called on.
self表示类的实例。通过使用“self”关键字,我们可以在python中访问类的属性和方法。它用给定的参数绑定属性。
你需要利用自我的原因。因为Python不使用@语法来引用实例属性。Python决定以一种方式来执行方法,这种方式使该方法所属的实例自动传递,而不是自动接收:方法的第一个参数是调用该方法的实例
使用super() 这里解释有一点复杂:
super(VGG, self).__init__()super() lets you avoid referring to the base class explicitly, which can be nice. But the main advantage comes with multiple inheritances, where all sorts of fun stuff can happen.
super()允许您避免显式地引用基类,这很好。但它的主要优势在于多重继承,在这里可以发生各种有趣的事情。
It's rather hand-wavey and doesn't tell us much, but the point of super is not to avoid writing the parent class. The point is to ensure that the next method in line in the method resolution order (MRO) is called. This becomes important in multiple inheritances.
这是一个很难理解的问题,但是super并不是为了避免编写父类。关键是确保调用方法解析顺序(MRO)中的下一个方法。这在多重继承中变得很重要。
一些参数的定义:
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()AdaptiveAvgPool2d:自适应平均池化。
What happens is that the pooling stencil size (aka kernel size) is determined to be
(input_size+target_size-1) // target_size, i.e. rounded up. With this Then the positions of where to apply the stencil are computed as rounded equidistant points between 0 and input_size - stencil_size.
Let’s have a 1d example:
Say you have an input size of 14 and a target size of 4. Then the stencil size is 4.
The four equidistant points would be 0, 3.3333, 6.6666, 10 and get rounded to 0, 3, 7, 10. And so the four items would be the mean of the slices 0:4, 3:7, 7:11, 10:14 (in Python manner, so including lower bound, excluding upper bound). You see that the first two and last two slices overlap by one. Something like - occasional overlaps of 1 - this will generally be the case when the input size is not divisible by the target size.简而言之就是,为了适应输入和输出的大小,自动调整池化模板的大小。
定义分类器:
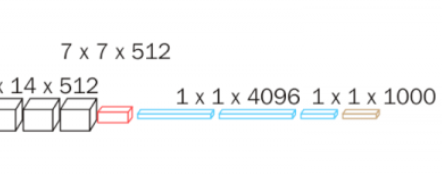
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes), # 这里的num_classes = 1000
)是否需要权重初始化:
if init_weights:
self._initialize_weights()前向传播:
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x解释:
def forward(self, *input):
r"""Defines the computation performed at every call. Should be overridden by all subclasses.
.. note::
Although the recipe for forward pass needs to be defined within
this function, one should call the :class:`Module` instance afterwards
instead of this since the former takes care of running the
registered hooks while the latter silently ignores them.
"""
raise NotImplementedError
torch.flatten:
#展平一个连续范围的维度,输出类型为Tensor
torch.flatten(input, start_dim=0, end_dim=-1) → Tensor
# Parameters:input (Tensor) – 输入为Tensor
#start_dim (int) – 展平的开始维度
#end_dim (int) – 展平的最后维度
#example
#一个3x2x2的三维张量
>>> t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[9, 10],
[11, 12]]])
#当开始维度为0,最后维度为-1,展开为一维
>>> torch.flatten(t)
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
#当开始维度为0,最后维度为-1,展开为3x4,也就是说第一维度不变,后面的压缩
>>> torch.flatten(t, start_dim=1)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
>>> torch.flatten(t, start_dim=1).size()
torch.Size([3, 4])
#下面的和上面进行对比应该就能看出是,当锁定最后的维度的时候
#前面的就会合并
>>> torch.flatten(t, start_dim=0, end_dim=1)
tensor([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12]])
>>> torch.flatten(t, start_dim=0, end_dim=1).size()
torch.Size([6, 2])
定义权重初始化函数:
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)关于isinstance():
isinstance(object, classinfo)object- object to be checkedclassinfo- class, type, or tuple of classes and typesThe
isinstance()returns:Trueif the object is an instance or subclass of a class, or any element of the tupleFalseotherwise
nn.init.kaiming_normal_:
Fills the input `Tensor` with values according to the method described in `Delving deep into rectifiers: Surpassing human- level performance on ImageNet classification` - He, K. et al. (2015), using a normal distribution.
The resulting tensor will have values sampled from
where
Also known as He initialization.
论文链接:
代码实现:
def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
with torch.no_grad():
return tensor.normal_(0, std)nn.init.constant_:
def constant_(tensor, val):
# type: (Tensor, float) -> Tensor
r"""Fills the input Tensor with the value :math:`\text{val}`.
Args:
tensor: an n-dimensional `torch.Tensor`
val: the value to fill the tensor with
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.constant_(w, 0.3)
"""
return _no_grad_fill_(tensor, val)nn.init.constant_(m.bias, 0) # 将偏置置零nn.init.normal_:正态分布
def normal_(tensor, mean=0., std=1.):
# type: (Tensor, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from the normal
distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.normal_(w)
"""
return _no_grad_normal_(tensor, mean, std)定义层生成函数:
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}定义模型生成函数:
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model**kwargs 和 *args :
*argsand**kwargsallow you to pass multiple arguments or keyword arguments to a function.*args和**kwargs允许向函数传递多个参数或关键字参数。
vgg11,vgg11_bn,vgg13...
格式都类似,这里只举出一个例子,其他的在vgg.py里都有
def vgg11(pretrained=False, progress=True, **kwargs):
r"""VGG 11-layer model (configuration "A") from
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)
