相信大家看了博主上一篇博客《什么是MapReduce
》后,对MapReduce的概念有了更深的认知!本篇博客,博主给大家带来的是MapReduce的一个简单的实战项目——统计输出给定的文本文档每一个单词出现的总次数。
在进行之前我们先看一下我们的数据源:

1. 创建Maven工程
下面的跟之前使用API一样,我们同样需要在IDEA中使用JAVA代码来书写MapReduce。这时候我们需要新建一个一个Maven工程
- 1. 创建项目
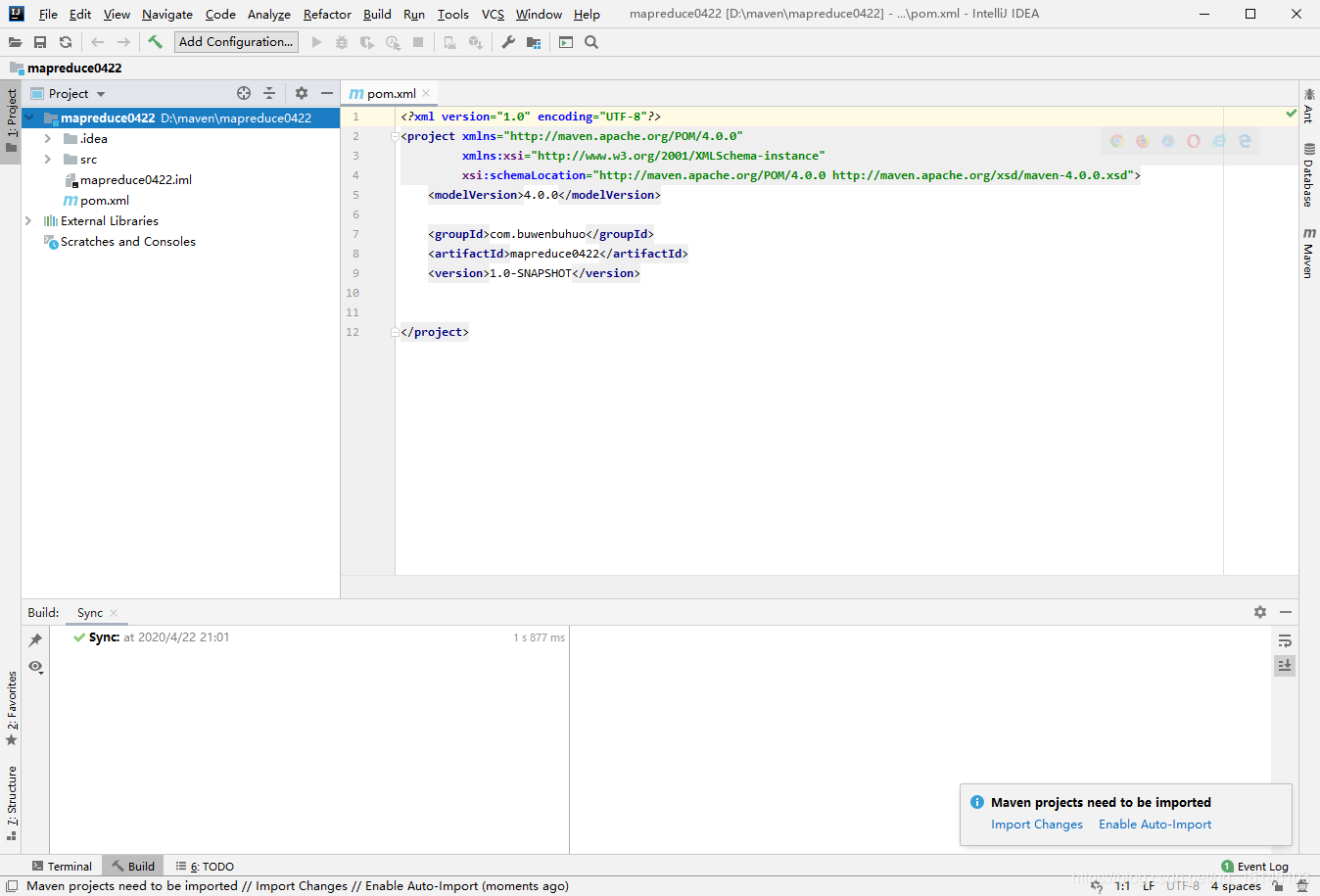
- 2. 在pom.xml文件中添加如下依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>D:/java/jdk-1.8.0/lib/tools.jar</systemPath>
</dependency>
</dependencies>
- 3. 在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2. 编写程序
2.1 编写Mapper类
package com.buwenbuhuo.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author 卜温不火
* @create 2020-04-22 21:24
* com.buwenbuhuo.wordcount - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
2.2 编写Reducer类
package com.buwenbuhuo.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author 卜温不火
* @create 2020-04-22 21:24
* com.buwenbuhuo.wordcount - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
2.3 编写Driver驱动类
package com.buwenbuhuo.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author 卜温不火
* @create 2020-04-22 21:24
* com.buwenbuhuo.wordcount - the name of the target package where the new class or interface will be created.
* mapreduce0422 - the name of the current project.
*/
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WcDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
2.4 运行
- 1.但是如果现在直接运行得话,会出现如下错误:

- 2.这是因为缺少了原始文件和要输出的目录,这是我们可以通过下列方法进行解决

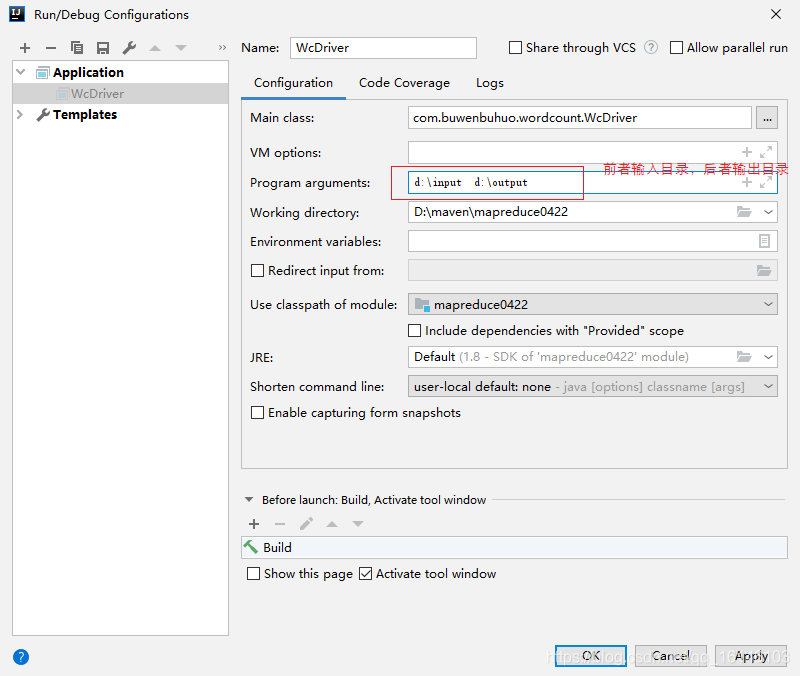
- 3. 再次运行
成功的截图
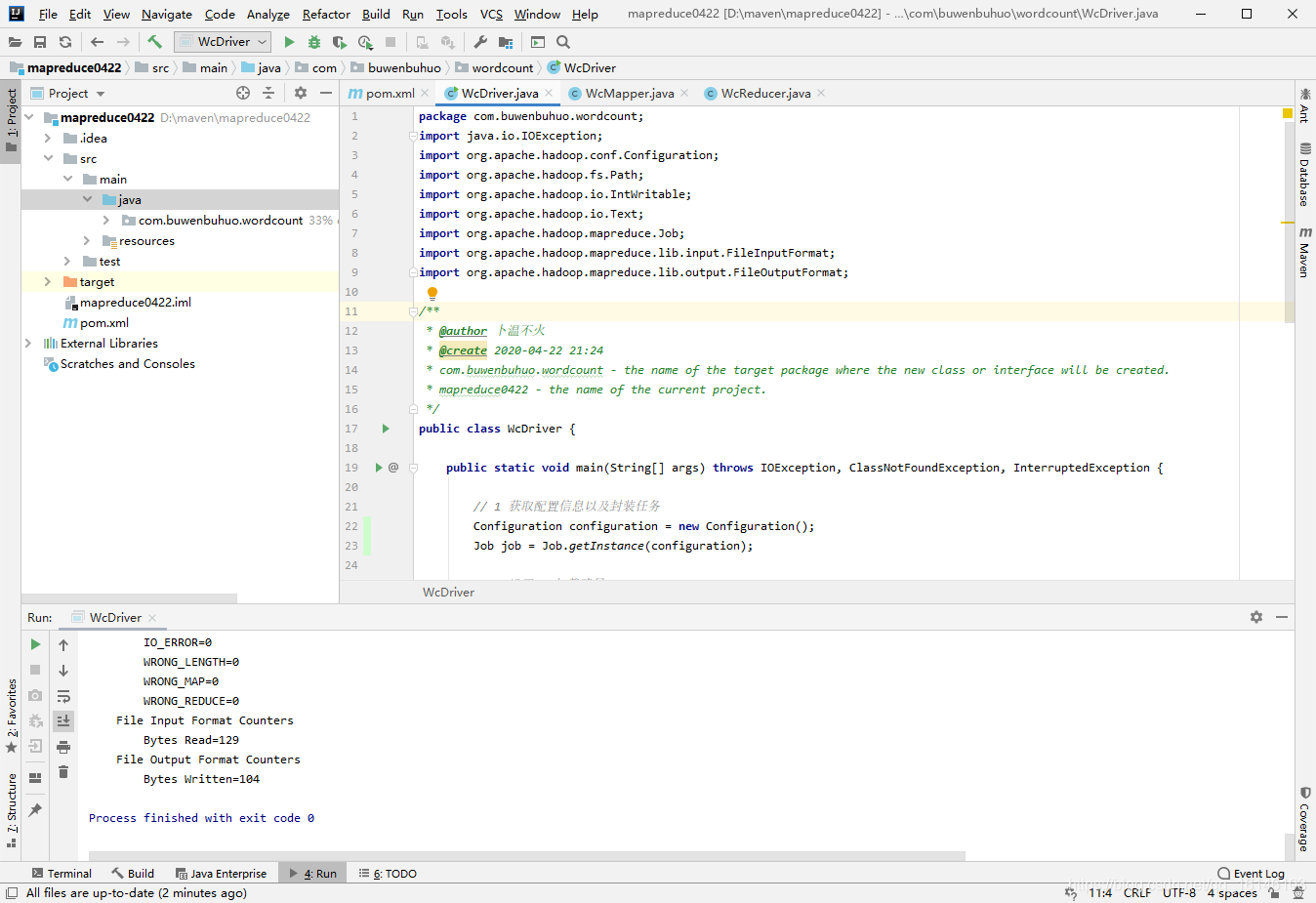
- 4. 下面我们来看下运行的结果
打开进入并用Notepad++ 打开文件查看内容!发现统计的结果已经呈现在里面了!说明我们的程序运行成功了!

过程梳理:
每读取一行数据,MapReduce就会调用一次map方法,在map方法中我们把每行数据用空格" "分隔成一个数组,遍历数组,把数组中的每一个元素作为key,1作为value作为map的输出传递给reduce。reduce把收集到的数据根据key值进行分区,把每个分区的内容进行单独计算,并把结果输出。
本次的分享就到这里了,受益的小伙伴们不要忘了点赞加关注呀,下一期博主将为大家继续带来MapReduce中如何打包jar包,并在集群上运行的博文,敬请期待。
