目录
需求:
统计每个手机号的上行流量总和,下行流量总和,上行总流量之和,下行总流量之和
分析:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入
1.创建maven项目导入pom.xml
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>2.自定义map输出value对象FlowBean
package com.czxy.flow;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
@NoArgsConstructor
public class FlowBean implements Writable {
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(upCountFlow);
out.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readInt();
this.downFlow = in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
}
}
3.定义map类
package com.czxy.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
// 创建FlowBean对象
FlowBean flowBean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//136315798**** 13726230 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 游戏娱乐 24 27 2481 24681 200
// 类型转换
String s = value.toString();
// 字符串切割
String[] split = s.split("\t");
//给对象添加信息
flowBean.setUpFlow(Integer.parseInt(split[6]));
flowBean.setDownFlow(Integer.parseInt(split[7]));
flowBean.setUpCountFlow(Integer.parseInt(split[8]));
flowBean.setDownCountFlow(Integer.parseInt(split[9]));
// 输出
context.write(new Text(split[1]),flowBean);
}
}
4.定义reduce类
package com.czxy.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReduce extends Reducer<Text, FlowBean, Text, FlowBean> {
private FlowBean flowBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
// 定义变量
int UpFlow = 0;
int DownFlow = 0;
int UpCountFlow = 0;
int DownCountFlow = 0;
// 遍历
for (FlowBean value : values) {
// 累加
UpFlow += value.getUpFlow();
DownFlow += value.getDownFlow();
UpCountFlow += value.getUpCountFlow();
DownCountFlow += value.getDownCountFlow();
}
// 给对象添加信息
flowBean.setUpFlow(UpFlow);
flowBean.setDownFlow(DownFlow);
flowBean.setUpCountFlow(UpCountFlow);
flowBean.setDownCountFlow(DownCountFlow);
// 输出
context.write(key, flowBean);
}
}
5.定义启动类
package com.czxy.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FlowDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 获取job
Job job = Job.getInstance(new Configuration());
// 设置支持jar执行
job.setJarByClass(FlowDriver.class);
// 设置执行的napper
job.setMapperClass(FlowMapper.class);
// 设置map输出的key类型
job.setMapOutputKeyClass(Text.class);
// 设置map输出value类型
job.setMapOutputValueClass(FlowBean.class);
// 设置执行的reduce
job.setReducerClass(FlowReduce.class);
// 设置reduce输出key的类型
job.setOutputKeyClass(Text.class);
// 设置reduce输出value的类型
job.setOutputValueClass(FlowBean.class);
// 设置文件输入
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("./data/flow/"));
// 设置文件输出
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("./outPut/flow/"));
// 设置启动类
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new FlowDriver(), args);
}
}
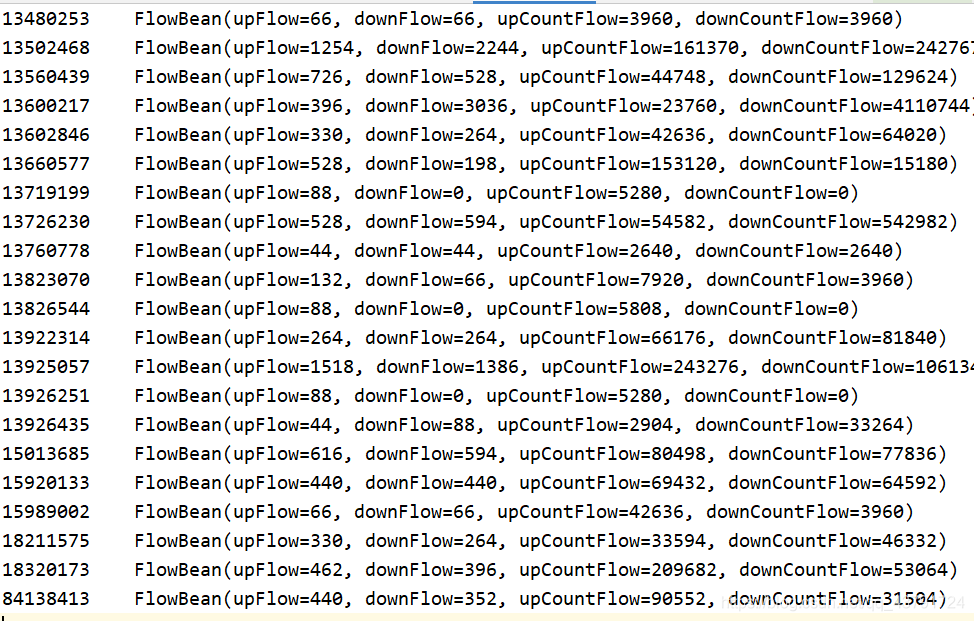
6.输入的文件及结果
点击下载(提取码 0t53 )
执行结果 part-r-00000
扫描二维码关注公众号,回复:
10723141 查看本文章