一、BeautifulSoup模块
- Windows环境下运行,需要在命令提示符内运行代码:pip install bs4
- MacOS环境下需要输入pip3 install BeautifulSoup4

- requests库帮我们搞定了爬虫第1步——获取数据。
- HTML知识,则有助于我们解析和提取网页源代码中的数据。
- 本次,则掌握如何使用BeautifulSoup解析和提取网页中的数据。
二、解析数据与提取数据
我们平时使用浏览器上网,浏览器会把服务器返回来的HTML源代码翻译成我们能看懂的样子,之后我们才能阅读网页进行各种操作。
相应地,我们在爬虫要使用类似地工具,将HTML“翻译”成程序能读懂代码,我们才能通过程序提取到想要的数据。
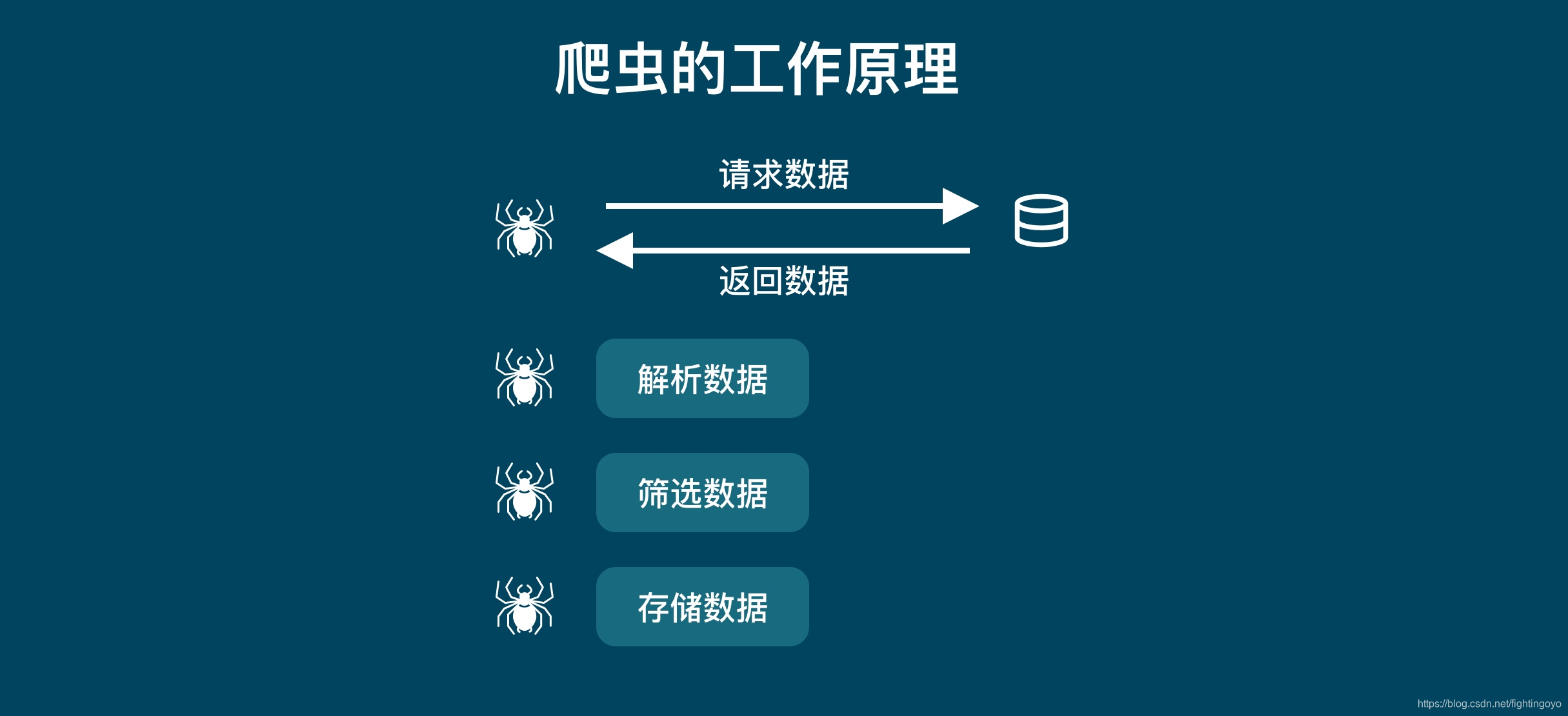
【提取数据】是指把我们需要的数据从源数据中有针对性地挑选出来。
三、使用BeautifulSoup解析数据

- 在括号中,要输入两个参数,第1个参数是要被解析的文本,注意了,它必须必须必须是字符串类型的值或者变量!!!
- 括号中的第2个参数用来标识解析器,我们要用的是一个Python内置库:html.parser(它不是唯一的解析器,但是相对来说比较简单。其他的还有’lxml’等)。
import requests
# 获取网页源代码,得到response对象
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 检查请求是否正确响应
print(response.status_code)
# 将response的内容以字符串的形式返回
html = response.text
# 打印html
print(html)
以上的内容是我们之前学习过的,下面用BeautifulSoup来解析网页数据。
import requests
# 引入bs库
from bs4 import BeautifulSoup
# 获取网页源代码,得到response对象
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 检查请求是否正确响应
print(response.status_code)
# 将response的内容以字符串的形式返回
html = response.text
# 把网页解析为BeautifulSoup对象
bs_response = BeautifulSoup(html,'html.parser')
我们将soup的数据类型和soup本身用print函数进行输出.
import requests
# 引入bs库
from bs4 import BeautifulSoup
# 获取网页源代码,得到response对象
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 检查请求是否正确响应
print(response.status_code)
# 将response的内容以字符串的形式返回
html = response.text
# 把网页解析为BeautifulSoup对象
bs_response = BeautifulSoup(html,'html.parser')
print(type(bs_response))
print(bs_response)
输出结果如下:
200
<class 'bs4.BeautifulSoup'>
bs对象网页源代码过长,此处不予展示
- bs_response的数据类型是<class ‘bs4.BeautifulSoup’>,说明bs_response是一个BeautifulSoup对象。
- 仔细地观察,我们会发现,打印soup出来的源代码和我们之前使用response.text打印出来的源代码是完全一样的。
- 虽然我们使用了BeautifulSoup来解析数据,但从直观上来看,得到的结果竟然和没解析之前一样。
- 但是虽然response.text和soup打印出的内容,从表面上看长得一模一样,却有着不同的内心,它们属于不同的类:<class ‘str’> 与<class ‘bs4.BeautifulSoup’>。前者是字符串,后者是已经被解析过的BeautifulSoup对象。之所以打印出来的是一样的文本,是因为BeautifulSoup对象在直接打印它的时候会调用该对象内的str方法,所以直接打印 bs 对象显示字符串是str的返回结果。
四、使用BeautifulSoup提取数据

1. find()与find_all()
- find()与find_all()是BeautifulSoup对象的两个方法,它们可以匹配HTML的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。
- 它俩的用法基本是一样的,区别在于,find()只提取首个满足要求的数据,而find_all()提取出的是所有满足要求的数据。

import requests
# 引入bs库
from bs4 import BeautifulSoup
# 获取网页源代码,得到response对象
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将response的内容以字符串的形式返回
html = response.text
# 把网页解析为BeautifulSoup对象
bs_response = BeautifulSoup(html,'html.parser')
# 使用find方法提取首个div元素,并放到变量item里
item = bs_response.find('div')
print(type(item))
print(item)
# 输出结果:
<class 'bs4.element.Tag'>
div元素内容过多,不予展示
运行结果正是首个<div>元素!我们还打印了它的数据类型:<class ‘bs4.element.Tag’>,说明这是一个Tag类对象。
再来试试find_all()吧,它可以提取出网页中的全部三个
import requests
# 引入bs库
from bs4 import BeautifulSoup
# 获取网页源代码,得到response对象
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将response的内容以字符串的形式返回
html = response.text
# 把网页解析为BeautifulSoup对象
bs_response = BeautifulSoup(html,'html.parser')
# 使用find方法提取首个div元素,并放到变量item里
item = bs_response.find_all('div')
print(type(item))
print(item)
# 输出结果如下:
<class 'bs4.element.ResultSet'>
find_all的结果以列表的形式输出了
三个<div>元素,它们一起组成了一个列表结构。打印items的类型,显示的是\<class ‘bs4.element.ResultSet’>,是一个ResultSet类的对象。其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理。
- 练习:爬取网站https://xiaoke.kaikeba.com/example/canteen/index.html的三道菜、材料及步骤
import requests
from bs4 import BeautifulSoup
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将返回的数据转换成BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过最小级父标签及属性,提取出包含三道菜信息的代码
foods = bs_response.find_all(class_='show-list-item')
# 打印出的结果为列表类型
print(foods)
打印出的列表并不是我们最终想要的东西,我们想要的是列表中的值,所以要想办法提取出列表中的每一个值。用for循环遍历列表,将其中的值提取出来。
import requests
from bs4 import BeautifulSoup
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将返回的数据转换成BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过最小级父标签及属性,提取出包含三道菜信息的代码
foods = bs_response.find_all(class_='show-list-item')
# for循环遍历列表
for food in foods:
print(food)
程序运行很顺利,结果正是那三道菜的<div>元素。
但是,我们现在打印出来的东西还不是我们最终想要的东西,因为我们打印出来的东西还含有HTML标签。
接着涉及提取数据中的另一个知识点——Tag对象。
2. Tag对象

刚才在网页中提取三道菜信息的代码可以继续进行。
import requests
from bs4 import BeautifulSoup
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将返回的数据转换成BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过最小级父标签及属性,提取出包含三道菜信息的代码
foods = bs_response.find_all(class_='show-list-item')
# for循环遍历列表
for food in foods:
# 分别提取标题、原材料、步骤的内容
title = food.find(class_='desc-title')
material =food.find(class_='desc-title')
step = food.find(class_='desc-step')
# 打印内容
print(title,material,step)
运行结果的数据类型,又是三个<class ‘bs4.element.Tag’>,用find()提取出来的数据类型和刚才一样,还是Tag对象。
这时,可以用到Tag对象的另外两种属性——Tag.text,和Tag[‘属性名’]。
import requests
from bs4 import BeautifulSoup
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将返回的数据转换成BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过最小级父标签及属性,提取出包含三道菜信息的代码
foods = bs_response.find_all(class_='show-list-item')
# for循环遍历列表
for food in foods:
# 分别提取标题、原材料、步骤的内容
title = food.find(class_='desc-title')
material =food.find(class_='desc-title')
step = food.find(class_='desc-step')
# 打印内容
print(title.text,'\n',material.text,'\n',step.text)
输出结果中有空格和换行,使用replace()替换空格与换行
import requests
from bs4 import BeautifulSoup
response = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
# 将返回的数据转换成BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过最小级父标签及属性,提取出包含三道菜信息的代码
foods = bs_response.find_all(class_='show-list-item')
# for循环遍历列表
for food in foods:
# 分别提取标题、原材料、步骤的内容
title = food.find(class_='desc-title')
material =food.find(class_='desc-material')
step = food.find(class_='desc-step')
# 打印内容
print(title.text.replace(' ',''),'\n',material.text.replace(' ',''),'\n',step.text.replace(' ',''))
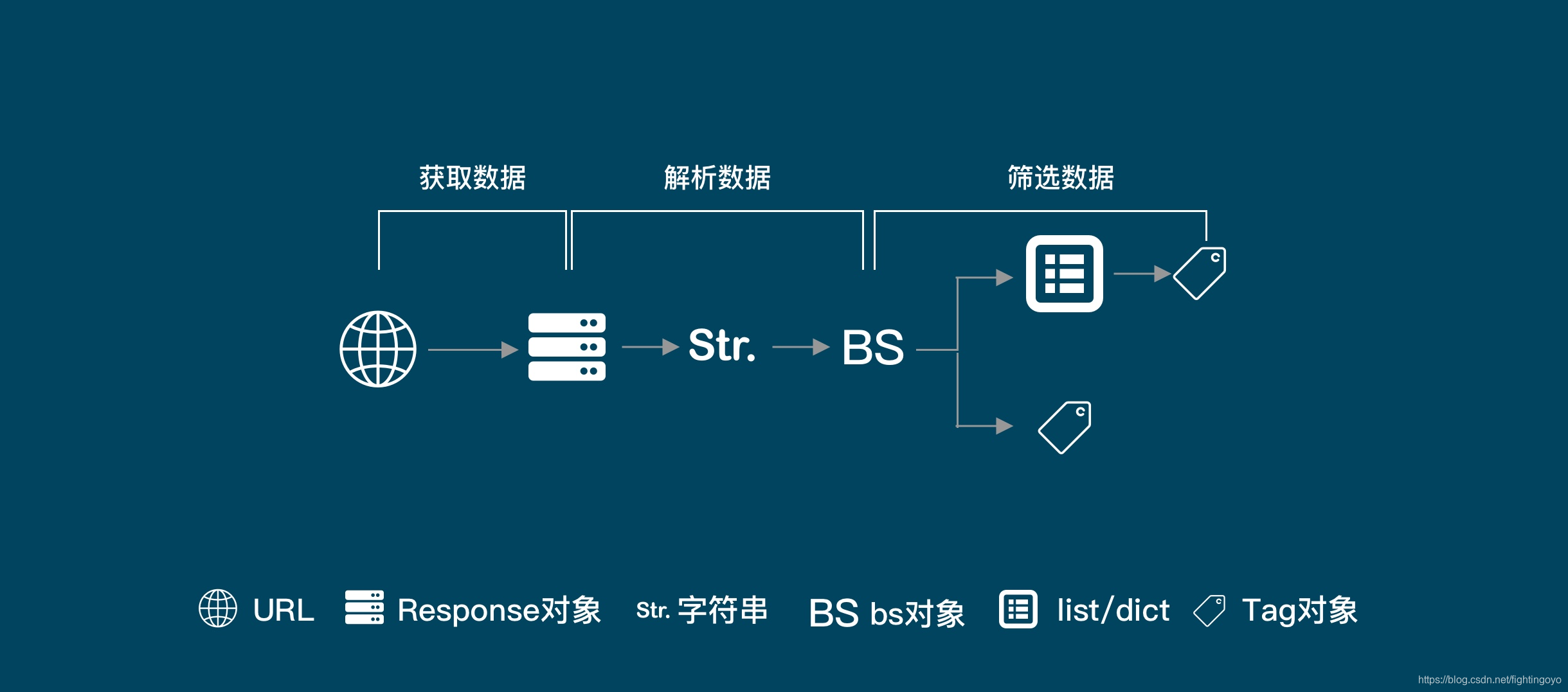
五、总结
我们的操作对象是这样的:Response对象——字符串——BS对象。到这里,又产生了两条分岔:一条是BS对象——Tag对象;另一条是BS对象——列表——Tag对象。




六、练习
- 爬取豆瓣新片榜的电影数据。网址:https://movie.douban.com/chart
- 第一种方法:找到父级标签,组成列表,再从中分别提取每个电影的信息
# 引用requests库
import requests
# 引用Beautiful库
from bs4 import BeautifulSoup
# 伪装请求头,避免反爬
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
# 向网站发起请求,返回response对象
response = requests.get('https://movie.douban.com/chart',headers=headers)
# 将返回的数据转换为BS对象
bs_response = BeautifulSoup(response.text,'html.parser')
# 通过每个电影代码块,找到最小父级标签
list_movie = bs_response.find_all('div',class_="pl2")
# 循环遍历列表
movies = []
for movie in list_movie:
tag_a = movie.find('a')
title = tag_a.text.replace(' ','').replace('\n','')
url = tag_a['href']
tag_p = movie.find(class_='pl')
info = tag_p.text.replace(' ','').replace('\n','')
rating = movie.find(class_="star clearfix").text.replace(' ','').replace('\n','')
movies.append([title,url,info,rating])
print(movies)
- 第二种方法:分别提取电影的信息,然后按顺序将信息组合起来,并将文件存入CSV中。
import requests
from bs4 import BeautifulSoup
import csv
# 伪装请求头,避免反爬
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
# 使用get()获取response对象
reponse = requests.get('https://movie.douban.com/chart',headers=headers)
# 将字符串转换为bs对象
bs_response = BeautifulSoup(reponse.text,'html.parser')
# 使用find_all()找到所有的电影信息
tag_name = bs_response.find_all('div',class_='pl2')
# 找到包含电影基本信息的标签
tag_p = bs_response.find_all('p',class_='pl')
# 找到包含电影评价信息的标签
tag_div = bs_response.find_all('div',class_='star clearfix')
# 创建文件"douban_film.csv,并以写入模式打开
myfile = open('douban_film.csv','w')
# 写入文件的对象
myfile_writer = csv.writer(myfile)
# 写入表头
movie_title = myfile_writer.writerow(['电影名称','网址URL','基本信息','评价信息'])
# 循环提取电影标题、URL、评价、信息
for num in range(len(tag_name)):
# 取得每个电影的名称
title = tag_name[num].find('a').text.replace(' ','').replace('\n','')
# 取得每个电影的URL
url = tag_name[num].find('a')['href']
# 取得每个电影的基本信息
info = tag_p[num].text.replace(' ','').replace('n','')
# 取得每个电影的评价信息
rating = tag_div[num].text.replace(' ','').replace('\n','')
# 将每部电影分别写入文件的行中
myfile_writer.writerow([title,url,info,rating])
# 关闭文件
myfile.close()
- 爬取豆瓣电影TOP250的列表,并存入xlsx文件中。
import requests
from bs4 import BeautifulSoup
import openpyxl
# 请求头,避免反爬
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
# 使用requests.get()获取response对象,循环更新每页的页码
# 创建xlsx工作簿
wb = openpyxl.Workbook()
# 创建工作表
sheet = wb.active
# 将工作表命名为豆瓣电影250
sheet.title = '豆瓣电影TOP250'
# 添加工作表头
sheet.append(['序号', '电影名称', '网址URL', '导演/演员', '评价信息', '影片简介'])
# 观察豆瓣TOP250的影片的URL,规律为每页间隔25.
for i in range(10):
reponse = requests.get(f'https://movie.douban.com/top250?start={i * 25}&filter=', headers=headers)
# 将返回的字符串转换为bs对象
bs_movie = BeautifulSoup(reponse.text, 'html.parser')
# 通过find_all找到包含电影信息的列表
list_movie = bs_movie.find_all('div', class_='item')
# 循环遍历列表,返回每个电影的信息
for movie in list_movie:
# 电影序号
num = movie.find('em').text
# 电影标题
title = movie.find('div', class_='hd').find('a').text.replace(' ', '').replace('\n', '')
# 电影网址URL
url = movie.find('a')['href']
# 电影导演与演员
director = movie.find('p').text.replace(' ', '').replace('\n', '')
# 电影评价信息
rating = movie.find('div', class_='star').text.replace(' ', '').replace('\n', '/')
# 电影简介,因第248条没有简介信息返回,所以使用异常捕捉报错
try:
info = movie.find('p', class_='quote').text.replace('\n', '')
except:
info = None
# 将电影信息逐行写入xlsx文件中
sheet.append([num, title, url, director, rating, info])
# 打印,以便发现问题
print(num)
print(title)
print(director)
print(rating)
print(info)
# 保存文件为"豆瓣点评TOP250.xlsx"
wb.save('豆瓣电影TOP250.xlsx')
# 关闭文件
wb.close()
