一、单引双引号都可以定义字符串 三引号允许一个字符串跨多行
在java语言中,字符'a' "abc"
字符串在内容中如何储存?字符串常量池
只要是变量传递方式.带有字符串运算的都是新内存
python是解释执行.没有内存优化,编译优化
字符串常量:即不变的量
新内存:开辟新空间
s='不迟到' s1="不早退" s2=''' <html> <hand></hand> <body></body> </html> ''' print(type(s2))
执行命令得
<class 'str'>
二、切片字符串
可以使用中括号和下标来获取单个字符,或者截取字符串,即 切片
顺序取值
s='不迟到,不早退' print(s[s.__len__()-1])#获取最后一位 print(s[-(s.__len__()])#获取第一位 print(s[2:5])#获取下标为2-4的字符 print(s[:])#获取所有 即冒号前后不写就取自然结果 print(s[3:2])#如果前面大雨后面则什么都不输出且报错
执行命令得
退 不 到,不 不迟到,不早退
逆顺序取值
s='不迟到,不早退' print(s[-1:-6:-1])#取下标-1到-6的字符 后面必须加步长-1 print(s[::-1])#从尾到头 print(s[-1::-1])#从尾到头 print(s[-1:0:-1])#固定语法不包含第一位 print(s[1:6:2])#取1-6之间每哥两个的值包含1
执行命令得
退早不,到 退早不,到迟不 退早不,到迟不 退早不,到迟 迟,早
三、Python字符串运算符
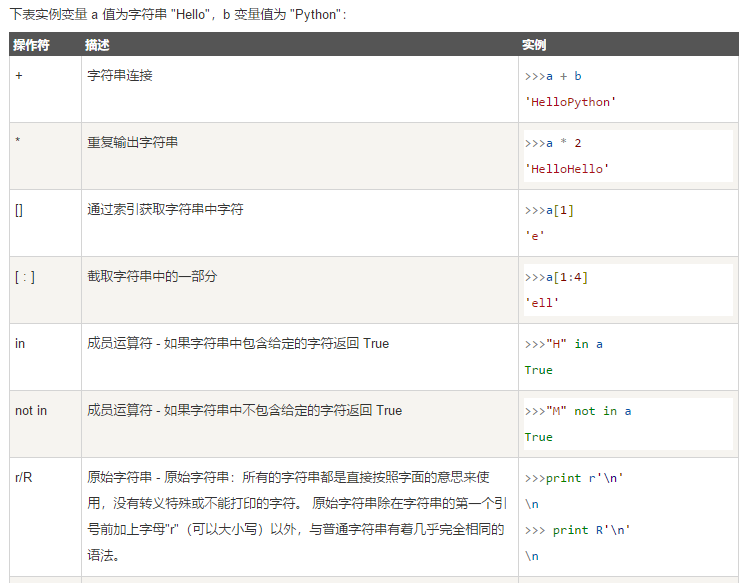
python命令例
s=R'不\\t迟到,不\n早退'#原样输出字符串
print(s)
print('迟'in s)
print('迟'not in s)
执行命令得
True False 不\\t迟到,不\n早退
四、字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
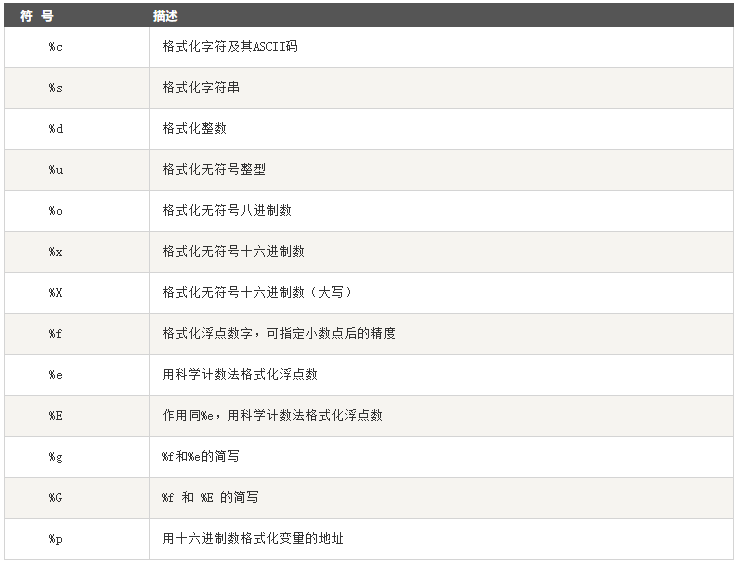
格式化操作符辅助指令
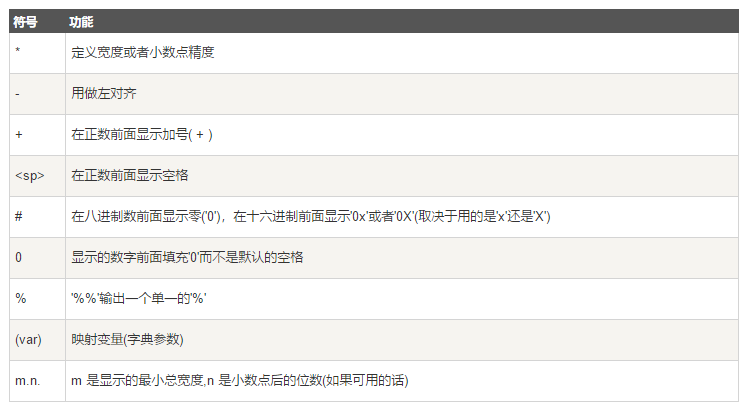
python命令例
print('%s今晚 请%s 去%s 吃%s 喝%s 消费%.2f 元'%('张三','李四','三里屯','烤肉','江小白',12))#%.2f为精确到小数点后两位
print('%s天气不错'%'明天')#如果只有一个百分号后可以胜率括号
执行命令得
张三今晚 请李四 去三里屯 吃烤肉 喝小白 消费12.00 元 明天 天气不错
.format()格式化:
想输出{}则输出两个{{}}例如:print('aaa{{0}}'.format())
print('{name}今年{age}岁'.format(name='张三',age=23))
print('姓名:{0},年龄:{1}'.format('张三',23))
print('姓名:{{0}},年龄:{1}'.format('张三',23))
执行命令得
张三今年23岁
姓名:张三,年龄:23
姓名:{0},年龄:23
五、字符串中的内建函数用法
| 序号 | 方法及描述 |
| 1 | capitalize() 将字符串的第一个字符转化为大写 |
| 2 | center(width,fillchar) 返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格. |
| 3 | count(str,beg=0,end=len(string)) 返回str在string里面出错的次数,如果beg或者end指定则返回指定范围内str出现的次数 |
| 4 | bytes.decode(encoding="utf-8",errors="strict") Python3 中没有decode用法,但是我们可以使用bytes对象的decode()方法来解码给定的bytes对象,这个butes对象可以由str.encode()来编码返回. |
| 5 | encode(encoding='UTF-8',errors='strict') 以encoding制定的编码格式编码字符串,如果出错默认报一个ValueError的异常,除非errors指定的是'ignore'或者'replace' |
| 6 | endswith(suffix,beg=0,end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str.beg=0 end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str,beg=0,end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常. |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isapha() 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | lower() 转换字符串中所有大写字符为小写. |
| 21 | ljust(width[,fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | replace(old,new[,max]) 把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str,beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex(str,beg=0,end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[,fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串字符串末尾的空格. |
| 31 | split(str="",num=string.count(str)) num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串 |
| 32 | splitlines([keepends]) 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(str,beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table,deletechars="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill(width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
一些常用的函数举例:
<1>len()获取参数的长度 可以是str list(列表) tuple(元组)
s='不迟到' print(s.__len__()) print(len(s))
执行命令得
3 3<2>
Python count() 方法用于统计字符串里某个字符出现的次数.可选参数为在字符串搜索的开始与结束位置
count()语法:
str.count(sub,start=0.end=len(string)
sub--搜索的子字符
start--字符串开始搜索的位置.默认为第一个字符,第一个字符索引值为零
end--字符串中结束走坐的位置.字符中第一个字符的索引0.默认字符串的最后一个位置
s='不迟到,不早退'
print(s.count('不'))
执行命令得
2
<3>capitalize()将字符串的第一个字符转化成大写
title()将每一个单词的首字母进行大写
split(str='',num=string.count(str)):mystr.split(""):如果split()什么都不写,就是将通过\t和空格进行拆分 num=分割几次
print('hello python'.capitalize())
print('hello,python my name is ok'.title())
listA='hello,my name is zhang san'.split(' ')
listB=' '
for i in listA:
temp=i.split(',')
for j in temp:
listB+=j.capitalize()+" "
print(listB)
执行命令得
Hello python Hello,Python My Name Is Ok Hello My Name Is Zhang San
str='hello python my name is ok not is java'
print(str.split(' ',2)#2为分割次数number执行命令得
['hello', 'python', 'my name is ok not is java']
<4>find()找字符串,返回找到的字符串下标 beg=0,end
rfind(str,beg=0,end=len(string))从右边开始找beg-end制定一个范围
index():和find()一样,找到才能在的下标,如果包含子字符串返回开始的索引值,否则抛出异常
rindex():从又面开始找
find() vs index():如果找不到,index()产生异常,find()则返回-1
str='hello python my name is ok not is java'
print(str.find('python'))
print(str.find('python3'))
print(str.index('python')#如果找不到报错执行命令得
6 -1 6
<5>replace()替换字符 但是原字符串不改变
str='hello python my name is ok not is java'
print(str.replace('python','java'))
print(str)
执行命令得
hello java my name is ok not is java hello python my name is ok not is java
练习
输出一个邮箱判断邮箱的格式是否正确并打印出用户名
email=input('请输入邮箱:')
if email.find('@')==-1 \#是否有@
or email.find('.')==-1 \#是否有'.'
or email.find('@')==0 \#@不能在第一位
or email.find('.')<email.find('@')#'.'有没有在@之前:
print('格式错误')
else:
print('邮箱格式 正确用户名正确',email[0:email.find('@')])#打印出@前的用户名
执行命令得
请输入邮箱:[email protected] 邮箱格式 正确用户名正确 zhangsan
<6>查找字符串的开始与结束字符
startswith(str,beg=0,end=len(string)):以xx开头 bool
endswith():以xx结尾 bool
str='hello,python my name is ok,not is java'
print(str.startswith('python',6,20))#第6位开始 20位结束
print(str.endswith('java',6))
执行命令得
True True
<7>转换字符串的大小写
小拓展
gt 意思是greater than(大于) ge 意思是greater and equal(大于等于) eq 意思是equal(等于) le 意思是less and equal(小于等于) lt 意思是less than(小于)
lower()将字符串的所有大写转化为小写
upper()将字符串中的小写转化为大写
print('Hello'.lower().__eq__('Hello'.lower())
print('Hello'.upper().__eq__('Hello'.upper())
执行命令得
True True<8>ljust(int num,str=""),rjust(),center():字符串输出是怎样对齐,括号里写大小写达到一个新的高度 以什么填充
print('hello'.ljust(8,'*'))#number必须大于本身的字符长度,ljust rjust center代表的是字符的位置即hello
print('hello'.ljust(8,'*'),'python')
print('hello'.center(9,'*'),'python')
执行命令得
hello*** hello*** python **hello** python
<9>strip(),lstrip(),rstrip()去除空格
print(len(' hello '))
print(len(' hello '.strip()))#去除全部空格
print(len(' hello '.rstrip()))#去除右边的空格
print(len(' hello '.lstrip()))#去除左边的空格
执行命令得
8 5 6 7
<10>拆分
paritition():str.partition('xxx')一次字符串为节点拆分 返回头、分隔符、尾部三部分,返回头尾空元素的三个元祖
str='hello,python my name is ok not in java'
print(str.split(' '))
print(str.partition(' '))
执行命令得
['hello,python', 'my', 'name', 'is', 'ok', 'not', 'in', 'java']
('hello,python', ' ', 'my name is ok not in java')
splitlines(bool keepends):按照换行符进行拆分,如果字符串中有"\n" 结果里是否去掉换行符('\r','\r\n','\n'),默认为False,不包含换行符,如果为True则保留换行符
str='hello,python\n my name is\n ok not in java' print(str) print(str.splitlines()) print(str.splitlines(True))
执行命令得
hello,python my name is ok not in java ['hello,python', ' my name is', ' ok not in java'] ['hello,python\n', ' my name is\n', ' ok not in java']
<11>判断字符串
isalpha():判断字符串是否全是字母/文字(汉字)非特殊字符(符号) true flase
isdigit():判断字符串是否全是数字 true/false
isalnum():判断字符串是否是数字和字母(汉字)非特殊字符 true/false
str='hello'
print(str.isalpha())
str='123j发'
print(str.isdigit())
print(str.isalnum())
执行命令得
True False True
<12>
join(sequence):将列表组成新的字符串,str.join("")sequence要拼接列表 str连接项
list=['你好','我好','大家好'] str="-__-" print(str.join(list))
执行命令得
你好-__-我好-__-大家好