又是一周,这次给自己复习一下Hbase,算是写的比较详细的,当然比较晚了,还没写完,这两天一定抽时间把它补完。
接下来进入正题:
1、Hbase的介绍
之前我们熟悉的数据库,比如Mysql,属于是关系型数据库,但是它的单机单表的数据量还是有限,在700—1000万条(网查的),但是在大数据框架中,这点数据量还是捉襟见肘,所以采用NOSQL数据库
关系型数据库:例如mysql、 Oracle
非关系型数据库:HBase
注意:Hbase读比写慢,详情请看Hbase的读与写流程
2、Hbase的安装与配置
首先需要知道:Hbase的存储是基于HDFS的,并且Hbase的元数据信息也存储在Zookeeper中,所以zk与hadoop需要能够正常启动。
2.1 Zookeeper与Hadoop正常部署
zookeeper集群的启动:zk.sh start
Hadoop集群的正常部署并启动:hdfs.sh start
帮助提示:
zk的启动命令:bin/zkServer.sh start
hdfs服务的启动:sbin/start-dfs.sh
yarn启动:sbin/start-yarn.sh

2.2 HBase的解压
解压Hbase到指定目录:tar -zxvf hbase-1.3.1-bin.tar.gz -C /usr/local/
Hbase-1.3.1的安装包:
2.3 HBase的配置文件
修改HBase对应的配置文件,位置:hbase的conf目录下:
1)hbase-env.sh修改内容(配置环境变量):
export JAVA_HOME=/usr/local/opt/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
这是因为Hbase里面有一个内置的zookeeper,所以我们在这里关闭,使用我们自己的zookeeper集群
2)hbase-site.xml添加以下内容:
<configuration>
<!-- 配置Hbase的数据存储地址-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master102:9000/HBase</value>
</property>
<!-- 配置Hbase的集群分布式为true -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 配置zookeeper的集群 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master102,slaver103,slaver104</value>
</property>
<!-- 配置Hbase在zookeeper中存储数据的目录(存储元数据信息) -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
3)regionservers(配置hbase集群的节点):
master102
slaver103
slaver104
4)软连接hadoop配置文件到HBase:
ln -s /usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml /usr/local/hbase/conf/core-site.xml
ln -s /usr/local/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/hdfs-site.xml
2.4 HBase远程发送到其他集群
[later@master module]$ xsync hbase/
同步服务请参考:
2.5 Hbase服务的启动
1.启动方式
[later@master hbase]$ bin/hbase-daemon.sh start master
[later@master hbase]$ bin/hbase-daemon.sh start regionserver
2.启动方式2
[later@master hbase]$ bin/start-hbase.sh
停止服务:
[later@master hbase]$ bin/stop-hbase.sh
特别注意:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。集群时间同步请参考:
2.6 查看Hbase页面
http://master102:16010
2.7 HBase Shell基本测试
1.进入HBase客户端命令行
[later@master hbase]$ bin/hbase shell
2.查看帮助命令
hbase(main):001:0> help
3.查看当前数据库中有哪些表
hbase(main):002:0> list
1.创建表
hbase(main):002:0> create ‘student’,‘info’
2.插入数据到表
hbase(main):003:0> put ‘student’,‘1001’,‘info:sex’,‘male’
hbase(main):004:0> put ‘student’,‘1001’,‘info:age’,‘18’
hbase(main):005:0> put ‘student’,‘1002’,‘info:name’,‘Janna’
hbase(main):006:0> put ‘student’,‘1002’,‘info:sex’,‘female’
hbase(main):007:0> put ‘student’,‘1002’,‘info:age’,‘20’
3.扫描查看表数据
hbase(main):008:0> scan ‘student’
hbase(main):009:0> scan ‘student’,{STARTROW => ‘1001’, STOPROW => ‘1001’}
hbase(main):010:0> scan ‘student’,{STARTROW => ‘1001’}
4.查看表结构
hbase(main):011:0> describe ‘student’
5.更新指定字段的数据
hbase(main):012:0> put ‘student’,‘1001’,‘info:name’,‘Nick’
hbase(main):013:0> put ‘student’,‘1001’,‘info:age’,‘100’
6.查看“指定行”或“指定列族:列”的数据
hbase(main):014:0> get ‘student’,‘1001’
hbase(main):015:0> get ‘student’,‘1001’,‘info:name’
7.统计表数据行数
hbase(main):021:0> count ‘student’
8.删除数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall ‘student’,‘1001’
删除某rowkey的某一列数据:
hbase(main):017:0> delete ‘student’,‘1002’,‘info:sex’
9.清空表数据
hbase(main):018:0> truncate ‘student’
提示:清空表的操作顺序为先disable,然后再truncate。
10.删除表
首先需要先让该表为disable状态:
hbase(main):019:0> disable ‘student’
然后才能drop这个表:
hbase(main):020:0> drop ‘student’
提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first.
11.变更表信息
将info列族中的数据存放3个版本:
hbase(main):022:0> alter ‘student’,{NAME=>‘info’,VERSIONS=>3}
hbase(main):022:0> get ‘student’,‘1001’,{COLUMN=>‘info:name’,VERSIONS=>3}
3、Hbase的架构
3.1 逻辑结构
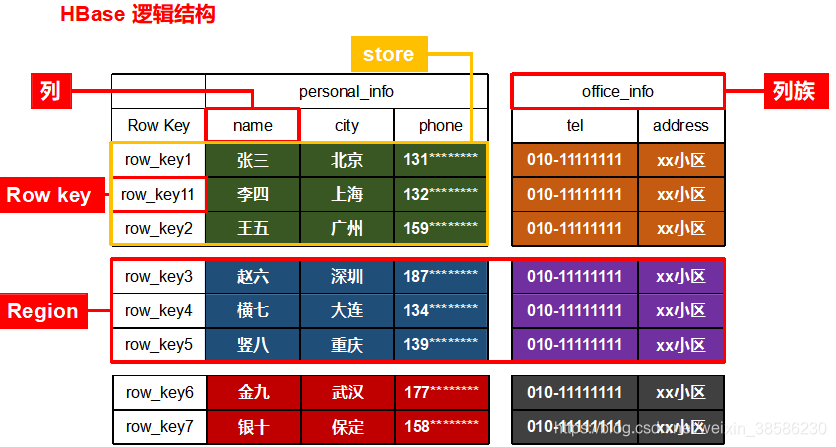
上图是用常见的二维表格在hbase中存储的逻辑结构
每一行的数据是按照rowKey来查找的,其中,因为该表可能列多,行多,所以我们
把多个列按照列族来管理,一个列族中包括多个列
把多个行按照Region来管理,一个Region中包括多行数据
把一个Region中的一个列族的数据叫做Store
3.2 物理存储结构
上面说的是逻辑结构,那么它实际上是如何存储数据的
注意:在Hbase中增删改数据,都会增加数据。只不过是type的不同
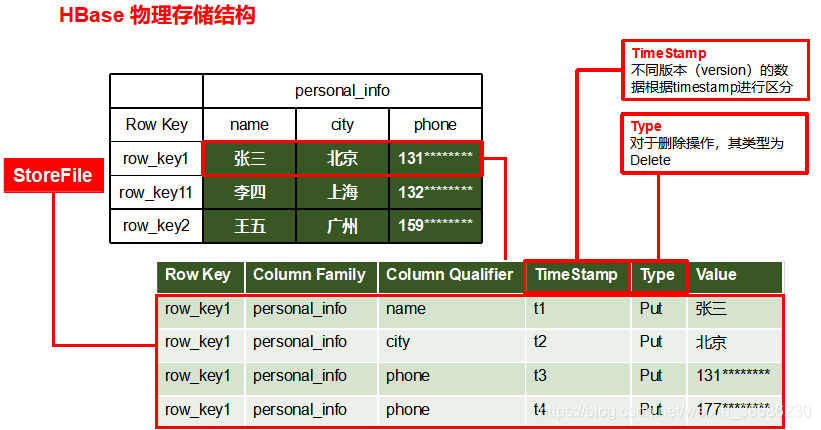
上图体现的是一行数据是怎么在Hbase中进行存储的
在关系库中,一个人的各种信息数据是以一行数据进行存储的,但在Hbase中并不是按照一行来存储的。而是把每个列的值都存为1行,关键信息为RowKey,列族信息,列名,时间戳,操作类型(添加这条数据时是删除还是添加还是修改),值
-
ROW:HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
-
Column:HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
-
Time Stamp:用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
-
Cell:由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。
cell中的数据是没有类型的,全部是字节码形式存贮。
-
Name Space:命名空间,类似于关系型数据库的DatabBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是“hbase”和“default”,“hbase”中存放的是HBase内置的表,“default”表是用户默认使用的命名空间。
-
Region:表的切片。类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3.3 架构原理
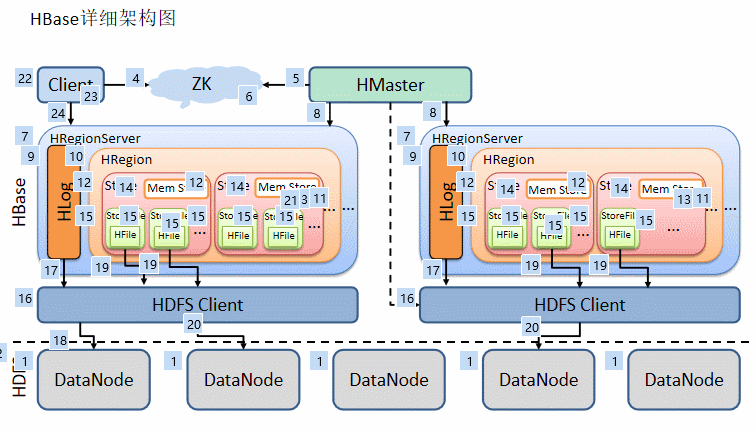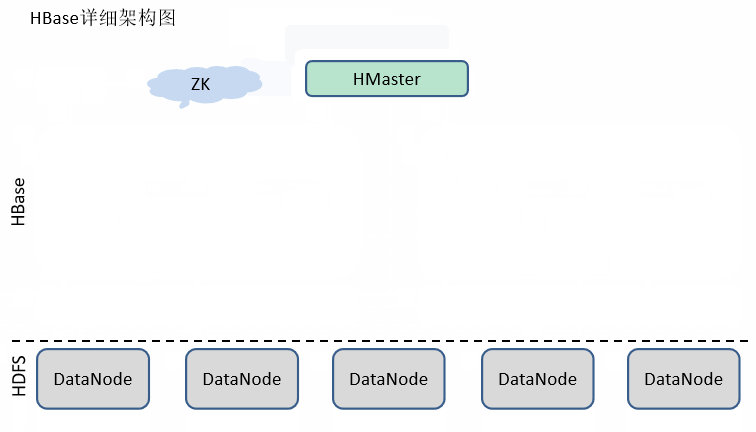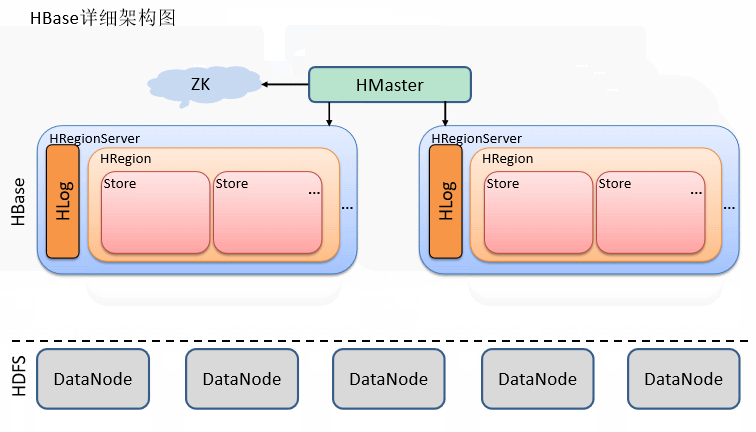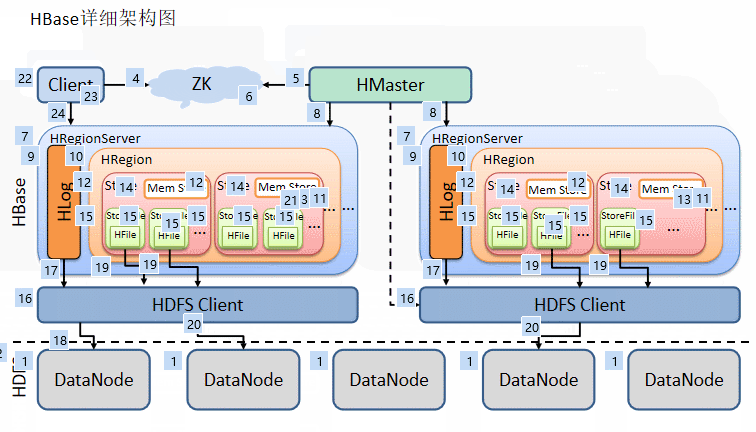
首先数据的存储依赖于HDFS,为HBase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
在Hbase的框架中,HMaster依赖于ZK,HMaster的作用管理数据的元数据(Hbase有一个meta表),类似于Hadoop中的NameNode
这里假设:Hbase集群有2个节点进行数据存储
-
每个节点都会有个进程HRegion Server,由Master进行管理,负载均衡。
-
而HRegion Server为Region的管理者,也就是其中包含着多个Region
-
Region是表的切片,所以Region中又有多个Store(列族的切片),也就是说同一个Region中的不同的Store来自于不同的列族
-
在每个Store中,数据的存储又依赖于内存区域:Mem Store,当内存达到一定的条件,就会刷写到磁盘(刷写机制见3.6),多次刷写后就有了多个Store File,刷写到磁盘的文件格式为HFile
-
考虑到多个刷写出来的文件较多,所以进行合并,当合并后的文件过大的时候(默认达到10G切分),不便于查找,按照midRowKey将进行切分。
-
最后Store File真正的存储还是要依赖于HDFS,其中还有Hlog也存储在HDFS(Hlog为预写入日志,及时落盘,用于HBase恢复数据)
-
HMaster和HDFS进行通信,来向HMaster汇报存储数据的元数据
术语解释:
1)Region Server
Region Server为Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
2)Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3.4 Hbase的写流程

1)客户端Client先访问zookeeper,获取hbase:meta表位于哪个RegionServer。
2)客户端继续访问对应的RegionServer,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出要写入的目标数据位于哪个RegionServer中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache(LRUcache方法,最近最常使用),方便下次访问。
3)客户端Client与目标RegionServer建立连接;
4)将数据顺序写入(追加)到WAL(也就是Hlog);
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;这个时候及时数据没有落盘,用户也可以查到。假如这个时候机器挂掉了,WAL也能帮助恢复
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
3.5 读流程
数据的读操作与HMaster没有关系
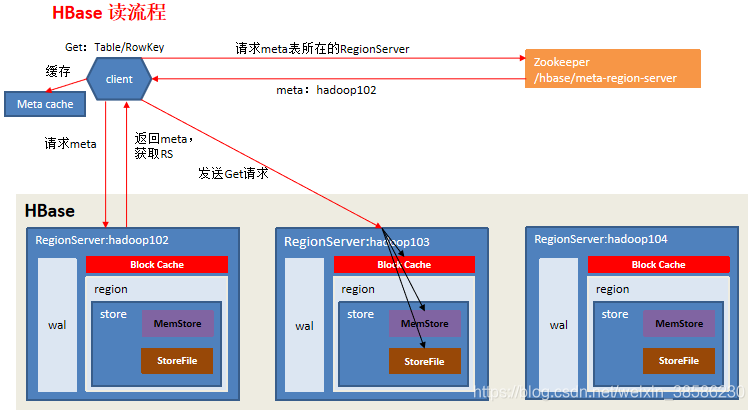
1)1-3步通写流程
4)分别在Block Cache(读缓存),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
这里的查询过程:
先要同时读取Block Cache(读缓存)和MemStore,再检索新落盘的文件,其中Block Cache缓存的是上一次落盘的文件
比如:同一个RowKey先写入(张三,时间戳为78),查找后缓存到Block Cache,过了几个小时,它已经落盘为文件,后写入(李四,时间戳为89),也落盘为文件了,但没进行查找,最后又写入(王五,时间戳为66),还在内存中
这个时候如果我们查找,理论上需要返回的是时间戳大的李四
查找过程:检索内存,时间戳为66,Block Cache缓存的是时间戳为78的张三,而李四属于是新落盘的文件,所以这个时候必须内存、缓存和文件都进行读取,才能返回结果。
5) 将从文件中查询到的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端
3.6 刷写机制
1.当单个Region中的memstroe的总大小达到了(默认值128M),其所在region的所有memstore都会刷写。
参数:hbase.hregion.memstore.flush.size(默认值128M)
2.当Region Server中memstore的总大小达到JVM堆内存的0.4时,region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。这个时候会阻塞客户端的写操作,直到当前内存的数据量小于堆内存的0.4*0.95,也就是堆内存的0.38时,才会打开写操作。
原因:只有当一直发生写操作,memstore的总大小达到JVM堆内存的0.4,那么这个时候开始了刷写,但如果说开始刷写后数据量还能达到JVM堆内存的0.38时,说明写数据的速度比刷写的速度快,如果不阻塞写操作,容易把内存爆了,发生OOM。
参数:java**_**heapsize * hbase.regionserver.global.memstore.size(默认值0.4)
hbase.regionserver.global.memstore.size.lower.limit**(默认值0.95)
3.单个MemStore到达自动刷写的时间(默认1小时,距离最后操作时间1小时),也会触发memstore flush。
参数:hbase.regionserver.optionalcacheflushinterval(默认1小时)。
4.当WAL(也就是Hlog)文件的数量超过(默认值32),region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
3.7 StoreFile合并
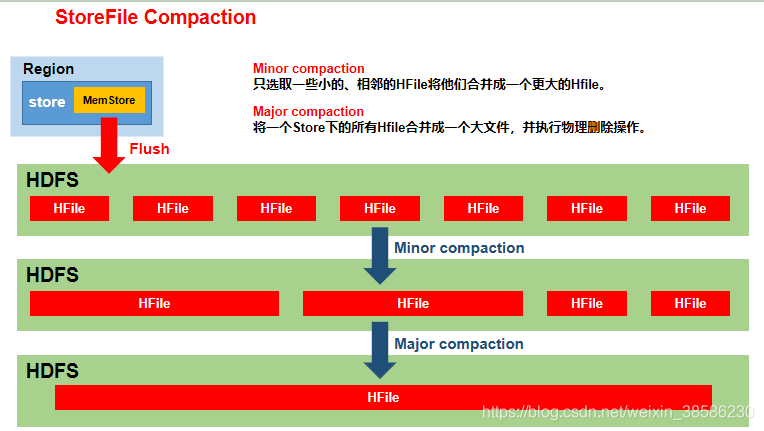
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。Compaction分为两种:
- Minor Compaction:会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据,可能原来有10个文件,合并完后还有3个。
- Major Compaction:会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。合并完后一定是只有1个文件。(默认为当一个Store下达到3个文件就会触发合并,当一个Store下文件数达到10时就会暂缓刷写,因为这个时候刷写的速度大于合并的速度)
3.7 Region Split

默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
Region Split时机:
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize(默认为10G),该Region就会进行拆分(0.94版本之前)。
2.当1个region中的某个Store下所有StoreFile的总大小超过
Min(R^2 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize"),该Region就会进行拆分,其中R为当前Region Server中属于该Table的个数(0.94版本之后)
4、Hbase的API
未完待续。。。
5、Hbase的优化
未完待续。。。
好了,关于Hbase的基本介绍就到这里了,知识水平、经验有限,可能有些细节没讲明白,欢迎大家指正。欢迎大家点赞、转发、评论哈。
