
Spark性能调优与原理分析
01、Spark运行模式
运行Spark的应用程序,其实仅仅需要两种角色,Driver和Executor。Driver负责将用户的应用程序划分为多个Job,分成多个Task,将Task提交到Executor中运行。Executor负责运行这些Task并将运行的结果返回给Driver程序。Driver和Executor实际上并不关心是运行在哪的,只要能够启动Java进程,将Driver程序和Executor运行起来,并能够使Driver和Executor进行通信即可。所以根据Driver和Executor的运行位置的不同划分出了多种部署模式。在不同的环境中运行Executor,其实都是通过SchedulerBackend接口不同实现类实现的。SchedulerBackend通过与不同的集群管理器(Cluster Manager)进行交互,实现在不同集群中的资源调度。其架构如图1所示。
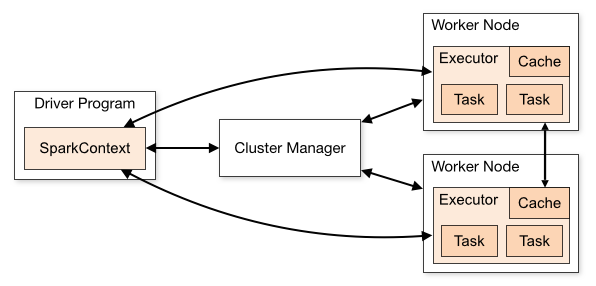
▍图1 Spark部署模式
Spark任务的运行,运行方式可分为两大类。即本地运行和集群运行。Spark在本地运行模式一般在开发测试时使用,该模式通过在本地的一个JVM进程中同时运行driver和1个executor进程,实现Spark任务的本地运行。在集群中运行时,Spark当前可以在Spark Standalone集群、YARN集群、Mesos集群、Kubernetes集群中运行。其实现的本质都是考虑如何将Spark的Driver进程和Executor进程在集群中调度,并实现Dirver和Executor进行通信。如果解决了这两大问题,也就解决了Spark任务在集群中运行的大部分问题。每一个Spark的Application都会有一个Driver和一个或多个Executor。在集群中运行时,多个Executor一定是在集群中运行的。而Driver程序,可以在集群中运行,也可以在集群之外运行,即在提交Spark任务的机器上运行。当Driver程序运行在集群中时,被称为cluster模式,当Driver程序运行在集群之外时,称为client模式。Spark在集群中的运行模式如图2所示。
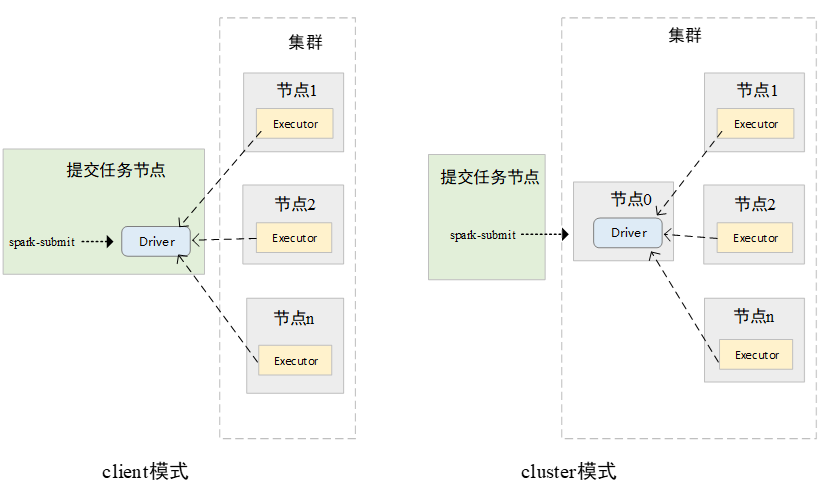
▍图2 Spark集群运行模式
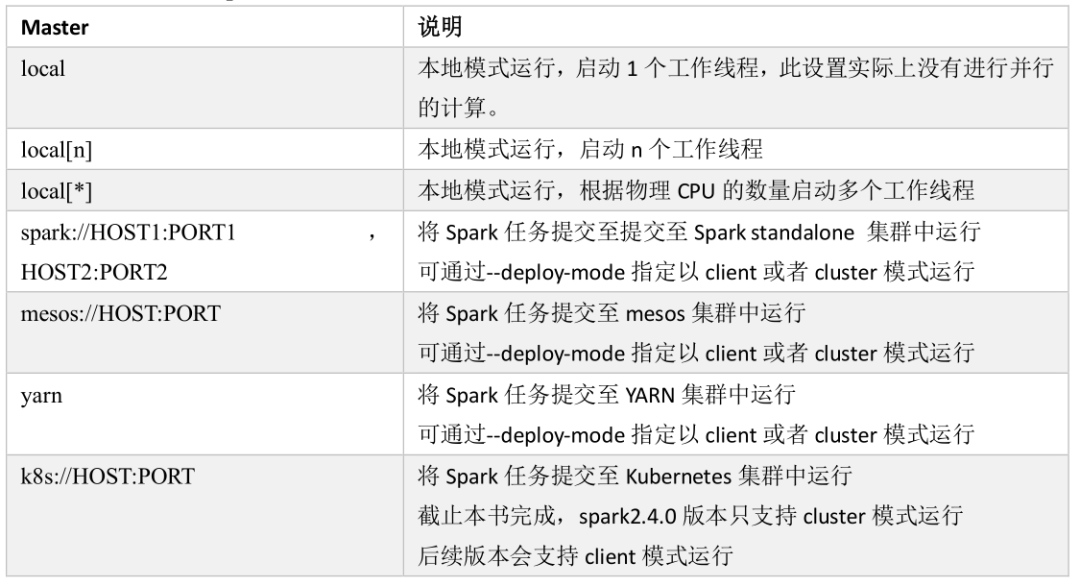
在提交Spark任务时,可以通过spark-submit 脚本通--mater参数指定集群的资源管理器,通过--deploy-mode参数指定以client模式运行还是以cluster模式运行。也可以在代码中硬编码指定Mater。Spark支持的Mater常用参数如下表所示。
1.Local模式
在Local运行模式中,Driver和Executor运行在同一个节点的同一个JVM中。在Local模式下,只启动了一个Executor。根据不同的Master URL,Executor中可以启动不同的工作线程,用于执行Task。Local模式Driver和Executor关系如下图3所示。
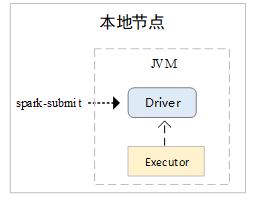
▍图3 Local模式
2.Spark Standalone
Spark框架除了提供Spark应用程序的计算框架外,还提供了一套简易的资源管理器。该资源管理器由Master和Worker组成。Master负责对所有的Worker运行状态管理,如Worker中可用CPU、可用内存等信息,Master也负责Spark应用程序注册,当有新的Spark应用程序提交到Spark集群中时,Master负责对该应用程序需要的资源进行划分,通知Worker启动Driver或Executor。Worker负责在本节点上进行Driver或Executor的启动和停止,向Master发送心跳信息等。Spark Standalone集群运行如图4所示。
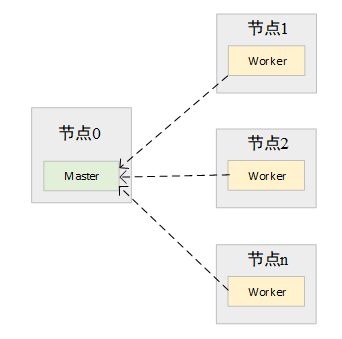
▍图4 Spark集群运行示意图
Spark任务运行在Spark集群中时,在client模式下,用户执行spark-submit脚本后,会在执行的节点上直接运行用户编写的main函数。在用户编写的main函数中会执行SparkContext的初始化。在SparkConext初始化的过程中,该进程会向Spark集群的Master节点发送消息,向Spark集群注册一个Spark应用程序,Master节点收到消息后,会根据应用程序的需求,通知在Worker上启动相应的Executor,Executor启动后,会再次反向注册到Driver进程中。此时Driver即可知道所有的可用的Executor,在执行Task时,将Task提交至已经注册的Executor上。其运行的流程如下图5所示。

▍图5 Spark集群client模式提交流程
在cluster模式下,用户编写的main函数即Driver进程并不是在执行spark-submit的节点上执行的,而是在spark-submit节点上临时启动了一个进程,这个进程向Master节点发送通知,Master节点在Worker节点中启动Driver进程,运行用户编写的程序,当Driver进程在集群中运行起来以后,spark-submit节点上启动的进程会自动退出,其后续注册Application的过程,与client模式是完全相同的。cluster模式下,提交Spark应用程序的流程如下图6所示。
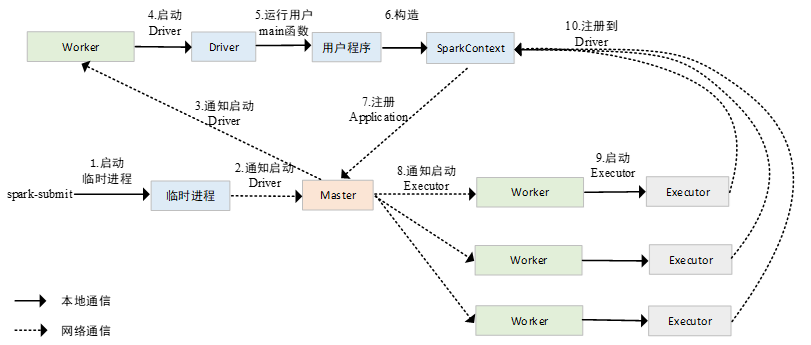
▍图6 Spark集群cluster模式提交流程
3.其他资源管理集群
在前文中已反复说明,Driver进程和Executor进程实际上并不关心是运行在哪里,只要有CPU和内存,能够保证Driver进程和Executor进程能够正常通信,运行在哪里都是相同的。在client和cluster两种运行模式中,很好的体现了这种特点,首先需要把Driver进程运行起来,后续的过程都是相同的。Spark应用程序能够运行在不同的资源管理集群中,也很好的提现了这一特点。Spark应用程序的Driver进程和Executor进程能够在不同的资源管理器中进行调度如YARN、Mesos、Kubernetes。其调度的过程与Spark Standalone集群相似,这里不再赘述。