三岁带你白话学编程,讲的一定懂,不懂的私下问,耐心到你懂!!!
前言
你还在为了找图片烦恼,还在为需要大量图片烦恼?那么你就out了
爬虫,动动手,想要的全都有。
不会怎么办,这个三岁已经给大家准备好了。
点击链接下载可执行文件,有网即可下载。
爬取思路

主要的思路是这样子的。
先找的网站的API
分析获得的网页,从网页中获得图片地址
在列表中保存地址
查看是否存在下载文件夹,没有就新建一个
把列表中的图片地址进行下载
保存照片
涉及到的第三方库
requests #请求网站数据
BeautifulSoup #分析页面
os #查看文件及创建文件
BeautifulSoup 需要安装
在cmd中输入 pip install bs4
分析网站
以必应网站为准https://cn.bing.com/images/async?查看其代码情况
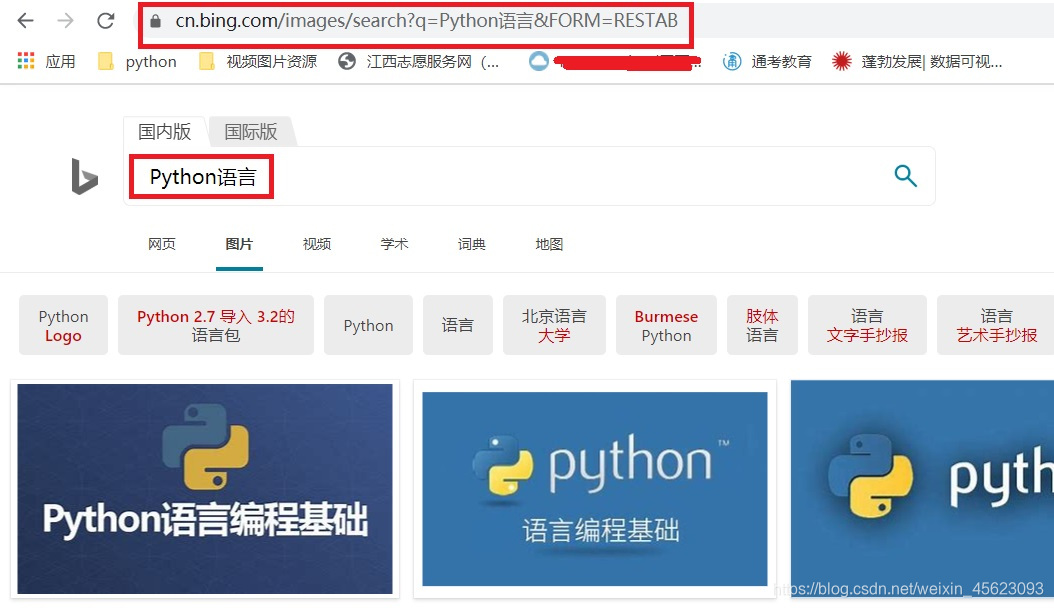
在网站查找发现q=后面的内容就是我们查找的内容emmm这个应该就是我们所说的API接口?
有可能吧
爬取网页信息初尝试
import requests
url = 'https://cn.bing.com/images/search?q=小猫'
kv = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 '
'Safari/537.36'}
def GetHtmlHTML(url, kv):
try:
r = requests.get(url, headers = kv)
r.raise_for_status() # 不是200报错
r.encoding = r.apparent_encoding
return r.text
except:
print('请求错误')
print(GetHtmlHTML(url, kv))

看了一下好像不是我们要的?那么问题在哪里呢?
emmm接口不对?
启用传说中的F12

没明白就是这个那么它里面是什么?
用prevew查看大致内容
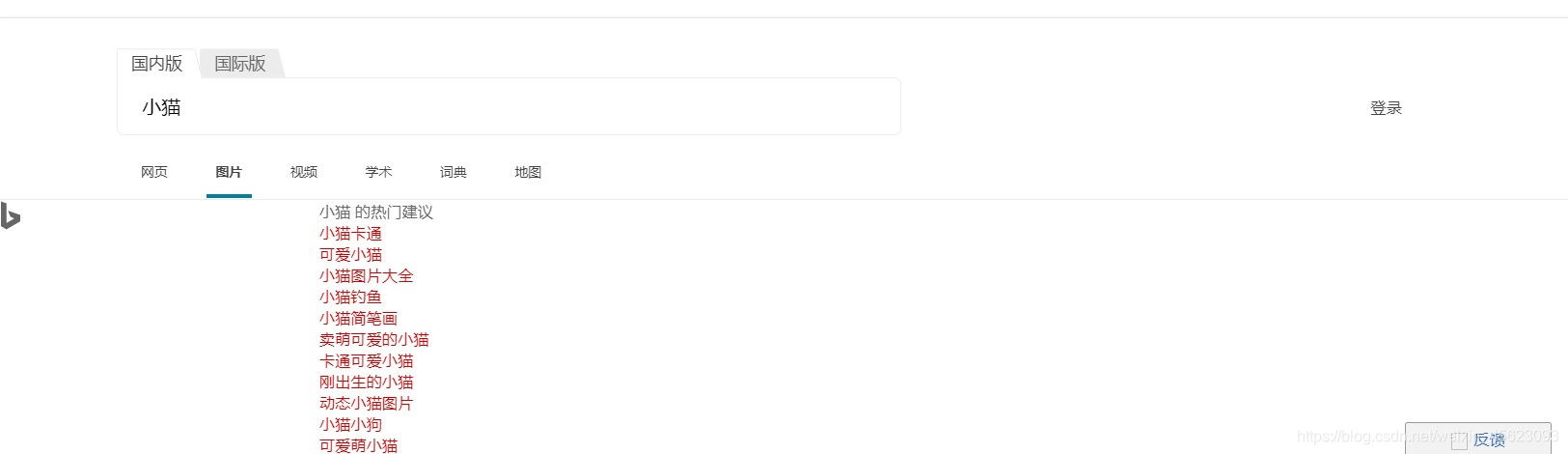
嗯,是他是他就是他
几乎一模一样的
那那那怎么没有
我们往下看

它里面没有图片的内容,就是一个网址,那么api还是不对
那么再找,去抓包去
API再查找
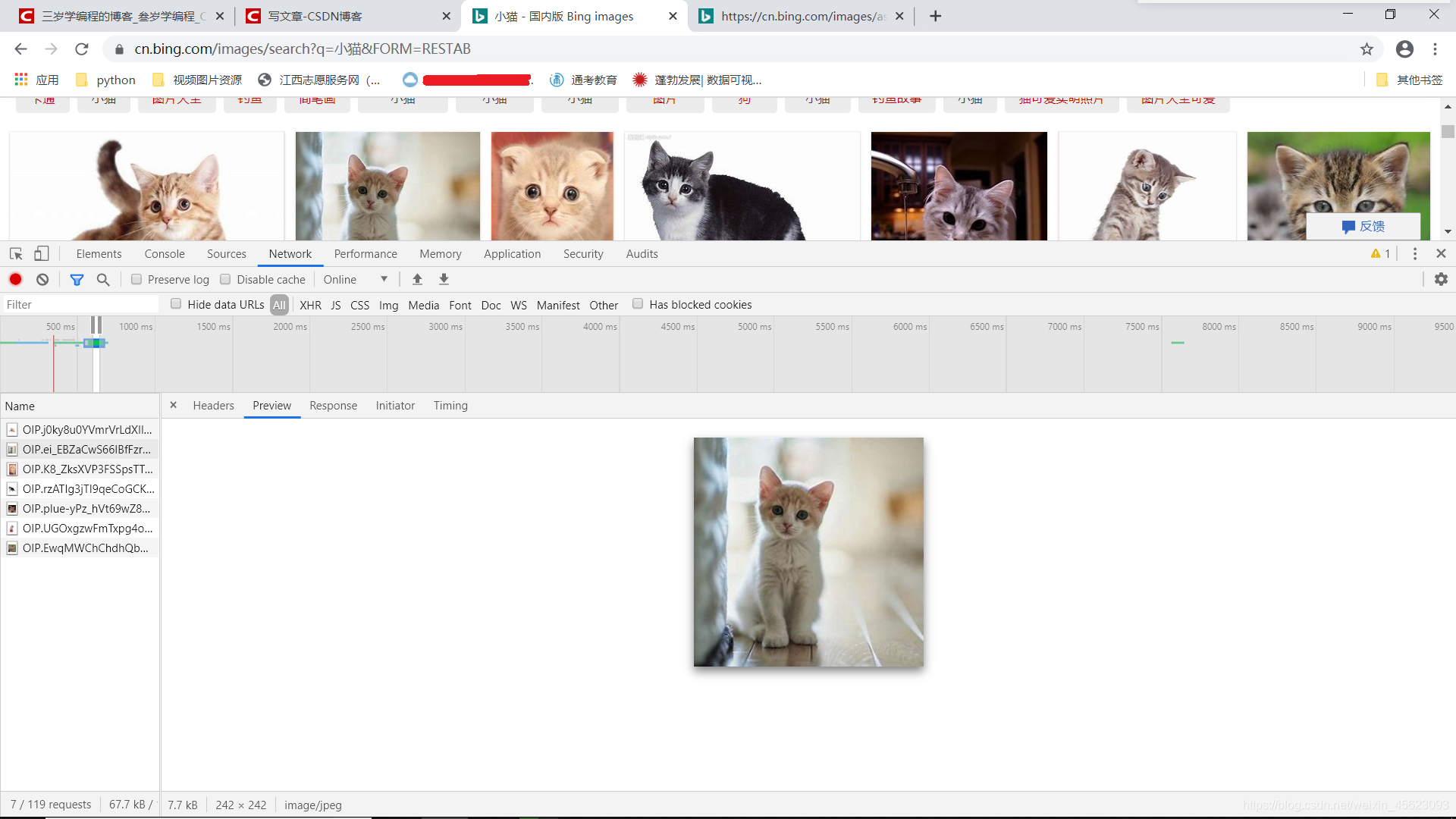
这些就是图片,找到了那么不可能一个一个去找,目标还没有达到,继续吧

清空network里面的内容,然后点击查看更多图片
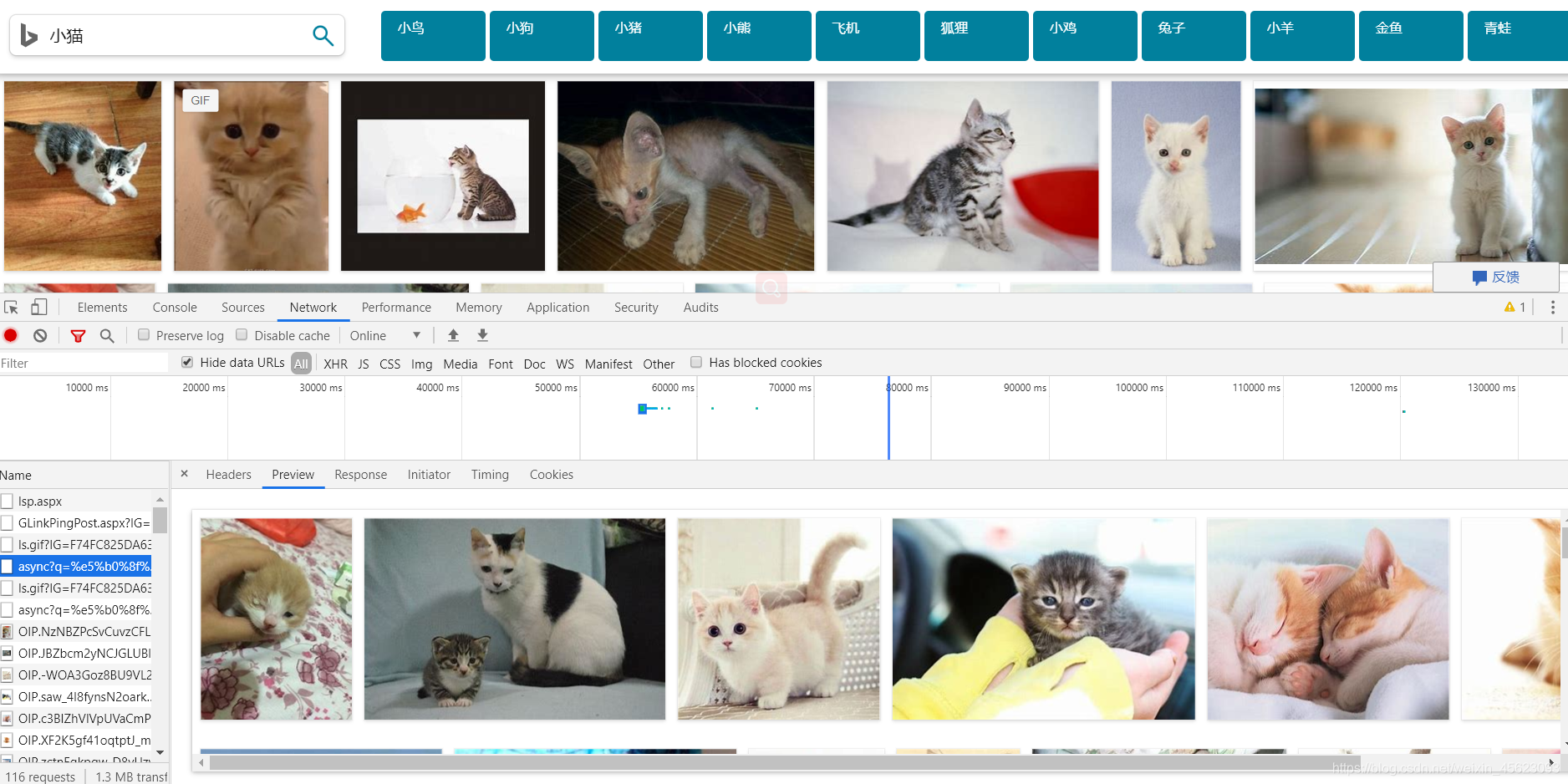
貌似找到了,全部都是图片

###爬取网页信息
import requests
url = 'https://cn.bing.com/images/async?q=%e5%b0%8f%e7%8c%ab&first=245&count=35&relp=35&scenario=ImageBa' \
'sicHover&datsrc=N_I&layout=RowBased&mmasync=1&dgState=x*0_y*0_h*0_c*7_i*211_r*34&IG=F74FC825DA634' \
'4CB990A128C90605EF0&SFX=7&iid=images.5624'
kv = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 '
'Safari/537.36'}
def GetHtmlHTML(url, kv):
try:
r = requests.get(url, headers = kv)
r.raise_for_status() # 不是200报错
r.encoding = r.apparent_encoding
return r.text
except:
print('请求错误')
print(GetHtmlHTML(url, kv))
结果:

里面蓝色的就是图片地址,我们把地址提取出来就好了
网页分析
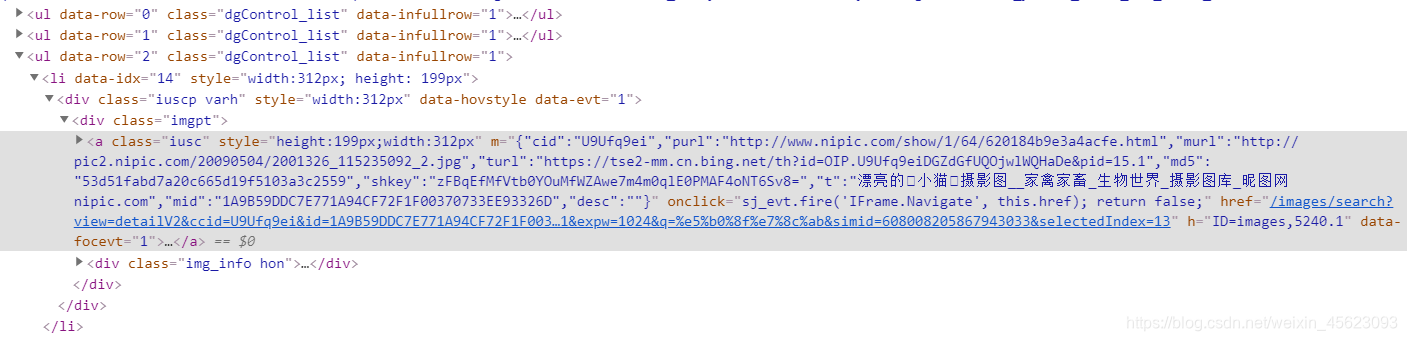
分析代码
<img class="mimg"
style="background-color:#a02b35;color:#a02b35"
height="204" width="292"
src="https://tse3-mm.cn.bing.net/th/id/OIP.kUY7yDmFNb
LXNE7Z6IBxtwHaFM?w=292&h=204&c=7&o=5&pid=1.7"
alt="小猫 的图像结果"/>
我们要的是img标签下的src里面的内容
代码如下
def fillPhotList(soup):
phot_list = []
tag_mass = BeautifulSoup.find_all(soup, {'img'})
#获得html下的所有img标签
for i in range(len(tag_mass)):
phot_site = (tag_mass[i].attrs['src'])
#循环标签获得scr里面的内容
phot_list.append(phot_site)
#把获得信息放到列表中
return phot_list
结果
['https://tse1-mm.cn.bing.net/th?q=%e5%b0%8f%e9%b8%9f&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse1-mm.cn.bing.net/th?q=%e5%b0%8f%e7%8b%97&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse4-mm.cn.bing.net/th?q=%e5%b0%8f%e7%8c%aa&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse2-mm.cn.bing.net/th?q=%e5%b0%8f%e7%86%8a&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse3-mm.cn.bing.net/th?q=%e9%a3%9e%e6%9c%ba&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse3-mm.cn.bing.net/th?q=%e7%8b%90%e7%8b%b8&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse3-mm.cn.bing.net/th?q=%e5%b0%8f%e9%b8%a1&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse3-mm.cn.bing.net/th?q=%e5%85%94%e5%ad%90&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse2-mm.cn.bing.net/th?q=%e5%b0%8f%e7%be%8a&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse2-mm.cn.bing.net/th?q=%e9%87%91%e9%b1%bc&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse2-mm.cn.bing.net/th?q=%e9%9d%92%e8%9b%99&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse4-mm.cn.bing.net/th?q=%e5%b0%8f%e7%8c%b4&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
'https://tse3-mm.cn.bing.net/th/id/OIP.j0ky8u0YVmrVrLdXIlHMawHaE9?w=300&h=201&c=7&o=5&pid=1.7',
'https://tse3-mm.cn.bing.net/th/id/OIP.ei_EBZaCwS66IBfFzr6WuAHaHa?w=225&h=218&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.K8_ZksXVP3FSSpsTTwWhqwHaLH?w=152&h=218&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.rzATIg3jTI9qeCoGCKs-XAHaFz?w=282&h=218&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP.pIue-yPz_hVt69wZ8HraOAHaHu?w=168&h=176&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.UGOxgzwFmTxpg4oGnAFYvQHaHr?w=170&h=176&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.EwqMWChChdhQbHdsF0NiOwHaHa?w=176&h=176&c=7&o=5&pid=1.7', 'https://tse2-mm.cn.bing.net/th/id/OIP.a4iLeJCI1jmRm-AY1yj2kwHaHa?w=177&h=176&c=7&o=5&pid=1.7',
'https://tse3-mm.cn.bing.net/th/id/OIP.nJ0i-5aEXzgP8yAQStIVrgHaE8?w=265&h=176&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP.vBWTVElkKbBzeBauacsOQgHaE8?w=230&h=160&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.k9fxiMC5hzAWgbvKQSLUQAHaJa?w=119&h=160&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.ILD6OMcZNO8xmu_mo9MhGgHaFk?w=204&h=160&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.FBwGALa6lJ1cNUa4Zvz6jQHaLH?w=115&h=160&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.U9Ufq9eiDGZdGfUQOjwlWQHaDe?w=288&h=140&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.03Yv6Q9oMzuag9qF44R7GAHaFQ?w=252&h=179&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.VA-8LB2iNUq62AZbHPKUkQHaFj?w=239&h=179&c=7&o=5&pid=1.7', 'https://tse2-mm.cn.bing.net/th/id/OIP.TL5MB54QdTIdjHIWabmzDAHaFj?w=239&h=179&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.RYp7V54BhIo7G3A3aUomcQHaFj?w=238&h=179&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.SIr8BxpqQGHbJ7BomIf86AHaGx?w=237&h=210&c=7&o=5&pid=1.7',
'https://tse4-mm.cn.bing.net/th/id/OIP.GTlMOXaBCe9idB2xfpLfXwHaIF?w=202&h=210&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.sZokQsxrrh2ZT7-Bjv3qVAHaHa?w=220&h=210&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP.Nw_EX5WpS1r2od-n46pgKQHaEo?w=299&h=187&c=7&o=5&pid=1.7',
'https://tse3-mm.cn.bing.net/th/id/OIP.U1-OhecHyPtmdcSPF0O6BQHaJ9?w=136&h=183&c=7&o=5&pid=1.7', 'https://tse3-mm.cn.bing.net/th/id/OIP.MD0wuPDSIYtVliJpN2YVCgHaE8?w=274&h=183&c=7&o=5&pid=1.7',
'https://tse4-mm.cn.bing.net/th/id/OIP.AzJvhpHk4rGkVG6V8RcLTwHaE2?w=281&h=183&c=7&o=5&pid=1.7',
'https://tse3-mm.cn.bing.net/th/id/OIP.fqdc2NuD5O_nMEKtQx0IfAHaE6?w=277&h=183&c=7&o=5&pid=1.7',
'https://tse4-mm.cn.bing.net/th/id/OIP.FNEVcbnPwkkU3aWFG1wG3AHaJQ?w=174&h=213&c=7&o=5&pid=1.7',
'https://tse3-mm.cn.bing.net/th/id/OIP.74vJvidqi79nKFgGsSKjYgHaHa?w=218&h=213&c=7&o=5&pid=1.7',
'https://tse2-mm.cn.bing.net/th/id/OIP.VJmR82nfZs8FhZGGa8g9kwHaE8?w=300&h=200&c=7&o=5&pid=1.7',
'https://tse1-mm.cn.bing.net/th/id/OIP.d4psuyc0Gya7usUlJ3OFvwHaF7?w=271&h=213&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP.HHpurfyH1cNYBUYVBJuaKQHaKb?w=156&h=213&c=7&o=5&pid=1.7', 'https://tse2-mm.cn.bing.net/th/id/OIP.jLzJXbZUQ25rp4ZvyEEn3wHaFj?w=288&h=213&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP.nv4vTqTy-An2a0OFDp2ePAHaE9?w=300&h=200&c=7&o=5&pid=1.7', 'https://tse4-mm.cn.bing.net/th/id/OIP._Yb_Dlrw9IhEq06Hzf2vpAHaHa?w=218&h=213&c=7&o=5&pid=1.7', 'https://tse2-mm.cn.bing.net/th/id/OIP.ws2LTWtOXgqrp39RFK2HUwHaLG?w=130&h=195&c=7&o=5&pid=1.7', 'https://tse2-mm.cn.bing.net/th?q=%e5%b0%8f%e7%8c%ab%e5%8d%a1%e9%80%9a&w=120&h=120&c=1&rs=1&qlt=90&cb=1&pid=InlineBlock&mkt=zh-CN&adlt=strict&t=1&mw=247',
……]
创建文件夹
import os
#查看是否存在文件夹
def file_confirm(matter):
if not os.path.exists(matter):
os.makedirs(matter)
print(f'{matter}创建成功')
小猫创建成功
导入OS库,查看文件是否存在,不存在则创建一个,创建完输出已创建。
关键:保存图片
def havePhot(photlist, kv, matter, counts):
#循环列表
for i in range(len(photlist)):
phot = requests.get(photlist[i], headers = kv)
#保存文件
with open(f'./{matter}/{matter}+{counts}+{i}.jpg','wb')as f:
f.write(phot.content)
print(f'{matter}+{counts}+{i}.jpg下载完成')
#展示下载情况
小猫+0+0.jpg下载完成
小猫+0+1.jpg下载完成
小猫+0+2.jpg下载完成
小猫+0+3.jpg下载完成
小猫+0+4.jpg下载完成
小猫+0+5.jpg下载完成
小猫+0+6.jpg下载完成
小猫+0+7.jpg下载完成
小猫+0+8.jpg下载完成
小猫+0+9.jpg下载完成
小猫+0+10.jpg下载完成
小猫+0+11.jpg下载完成
小猫+0+12.jpg下载完成
小猫+0+13.jpg下载完成
主函数(函数入口)
def main():
matter = input('图片内容')
counts = int(input('大致需要图片数量')) // 35
file_confirm(matter)
for count in range(counts+5):
url = f"https://cn.bing.com/images/async?q={matter}&first={count*50}&relp=35&scenario=ImageBasicHover&datsrc=N_I&layout=RowBased_Landscape" \
"&mmasync=1&dgState=x*0_y*0_h*0_c*7_i*71_r*9&IG=3ABC8EDB67A0437FBDC8BF88BA9B2DCA&SFX=3&iid=images.5602"
html = GetHtmlHTML(url, kv)
soup = BeautifulSoup(html, 'lxml')
photList = fillPhotList(soup)
havePhot(photList, kv, matter,count)
main()
全部源码
emmm这个是以面向对象形式写的,当独的代码无法运行,那么我把源码展示如下
import requests
from bs4 import BeautifulSoup
import os
kv = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 '
'Safari/537.36'}
#请求
def GetHtmlHTML(url, kv):
try:
r = requests.get(url, headers = kv)
r.raise_for_status() # 不是200报错
r.encoding = r.apparent_encoding
return r.text
except:
print('请求错误')
#分析
def fillPhotList(soup):
phot_list = []
tag_mass = BeautifulSoup.find_all(soup, {'img'})
#print(tag_mass)
for i in range(len(tag_mass)):
phot_site = (tag_mass[i].attrs['src'])
#print(phot_site)
phot_list.append(phot_site)
print(phot_list)
return phot_list
#查看是否存在文件夹
def file_confirm(matter):
if not os.path.exists(matter):
os.makedirs(matter)
print(f'{matter}创建成功')
#下载保存
def havePhot(photlist, kv, matter, counts):
for i in range(len(photlist)):
phot = requests.get(photlist[i], headers = kv)
with open(f'./{matter}/{matter}+{counts}+{i}.jpg','wb')as f:
f.write(phot.content)
# thread_lock.release()
print(f'{matter}+{counts}+{i}.jpg下载完成')
#主函数
def main():
matter = input('图片内容')
counts = int(input('大致需要图片数量')) // 35
file_confirm(matter)
for count in range(counts+5):
url = f"https://cn.bing.com/images/async?q={matter}&first={count*50}&relp=35&scenario=ImageBasicHover&datsrc=N_I&layout=RowBased_Landscape" \
"&mmasync=1&dgState=x*0_y*0_h*0_c*7_i*71_r*9&IG=3ABC8EDB67A0437FBDC8BF88BA9B2DCA&SFX=3&iid=images.5602"
html = GetHtmlHTML(url, kv)
soup = BeautifulSoup(html, 'lxml')
photList = fillPhotList(soup)
havePhot(photList, kv, matter,count)
main()
源码中还涉及了图片数量,因为这个图片数量和选择内容有关判断困难所以以最低标准进行选择。
具体的问题有疑问的我们可以私聊哦
看看成果
帅哥,美女,小猫小狗,动漫的图随时随地都可以撸。
是不是很棒
一起学习学习
今天就到这里了,如果还不会欢迎来打我。
