目录:
前言
学习的结果要依靠输出来检验。
环境还是得特别强调一下:
硬件:
华硕(ASUS) 飞行堡垒三代FX60VM GTX1060 15.6英寸游戏笔记本电脑(i7-6700HQ 8G 128GSSD+1T FHD)黑色
软件:
python 3.6:下载
tensorflow 1.8.0 地址
cuda 9.0:下载
cudnn 7.1:下载
基本概念
要想流畅得使用tensorflow实现你的项目,必须要对一些基础概念有很深入的理解。
图
tensorflow中的计算可以表示为一个计算图,其中每一个运算操作将作为一个节点,节点与节点之间的连接称为边。这个计算图描述了数据的计算流程,必须要好好理解这个概念,才能体会到这个计算模型的优越。
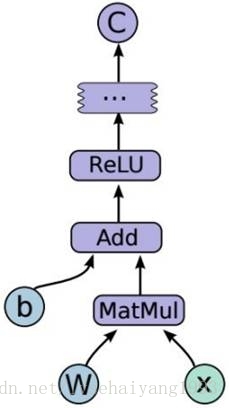
计算图中每一个节点可以有任意多个输入和任意多个输出,每一个节点描述了一种运算操作,节点可以算是运算操作的实例化。在计算图的边中流动的数据被称为张量,故得名tensorflow。session 是用户使用tensorflow时的交互式接口。用户可以通过Session的extend方法添加新的节点和边,用以创建计算图,然后就可以通过Session的Run方法执行计算图:用户给出需要计算的节点,同时提供输入数据,Tensorflow就会自动寻找所有需要计算的节点并按依赖顺序执行它们。
variables可以保存张量,而其他张量则不会保存。
实现原理

这张图很好的展示了,tensorflow的实现方式,高度抽象:
客户端负责与使用者交互。
master负责当客户端与worker的中介
worker则负责调度具体的硬件实现计算。
在只有一个硬件设备的情况下,计算图会按照依赖关系被顺序执行。 当一个节点的所有上游依赖都被执行完时(依赖数减为0),这个节点就会被加入ready queue 以等待执行。同时他下游的所有节点的依赖数减1.
分布式的时候遇到的难题:
- 每一个节点该让什么设备执行?
- 如何管理节点间的数据通信。
1第一个问题,目前采用贪婪策略解决,未来希望使用强化学习。
2第二个问题,当给节点的分配方案确定时,整个计算图就会被划分为许多子图,使用同一个设备并且相邻的节点会被划分到同一个子图。然后计算图中从x到y的边,会被取代为一个发送端的发送节点和一个接受端的接受节点,以及从发送节点到接受节点的边。

问题就这样简化了,机制很优秀。

这是cpu和gpu通信的图。
扩展功能
1自动求导
计算costfunction的梯度很关键,tensorflow支持自动求导,
比如一个tensor c在计算图中有一组依赖的tensor{x},那么在tensorflow中可以自动导出{dc/dx}。这个求解过程在计算途中通过增加节点自动实现。
反向规则。
[db,dw,dx]=tf.gradients(C,[b,w,x]).
2单独执行子图
用户可以选择计算图的任意子图,并沿某些边输入数据,同时从另一些边获取输出结果。Tensorflow用节点名加port的形式指定数据,例如bar:0表示名为bar的节点的第一个输出。
同时,tensorflow会自动确定哪些节点应该被执行。
3计算图的控制流
提供高阶函数,例如merge和swith来进行控制流。
4文件系统路径
在分布式的时候,直接读取本地文件,而不是读取异地文件。
5队列
tensorflow支持fifo队列,也支持shuffling queue队列进行调度,用以满足要求。
6容器
每一个进程的默认容器会一直存在,直到进程结束,它可以帮助不同计算图的会话分享状态变量。管理长期变量的机制。
性能优化
1高阶函数自动优化基本操作。
2任务调度优化,内存,cpu综合考虑。
3支持优化库。
4数据压缩
5并行计算模式:1数据并行,模型并行,流水线并行。
尾声:
学以致用,以学促用。
欢迎大家一起分享。