这是一个在MTCNN和LPRNet中使用PYTORCH的两阶段轻量级和健壮的车牌识别。
MTCNN是一个非常著名的实时检测模型,主要用于人脸识别。修改后用于车牌检测。LPRNet是另一种实时的端到端DNN,用于模糊识别.该网络以其优越的性能和较低的计算成本而不需要初步的字符分割。在这项工作中嵌入了Spatial Transformer Layer(空间变换层 LocNet),以便有更好的识别特性。
在Nivida Quadro P4000上使用该结构在CCPD数据集上能达到~ 80 ms/image的速度,识别准确率可达99%。下面是流程框架:

MTCNN
MTCNN 基础知识
MTCNN 一开始主要是拿来做人脸识别的(不知道现在还是不是,希望大佬可以分享最新的人脸识别网络)。MTCNN人脸检测是2016年的论文提出来的,MTCNN的“MT”是指多任务学习(Multi-Task),在同一个任务中同时学习”识别人脸“、”边框回归“、”人脸关键点识别“。

- 首先对test图片不断进行Resize,得到图片金字塔。按照resize_factor(如0.70,这个具体根据数据集人脸大小分布来确定,基本确定在0.70-0.80之间会比较合适,设的比较大,容易延长推理时间,小了容易漏掉一些中小型人脸)对test图片进行resize,直到大等于Pnet要求的1212大小。这样子你会得到原图、原图resize_factor、原图*resize_factor2…、原图*resize_factorn(注,最后一个的图片大小会大等于12)这些不同大小的图片,堆叠起来的话像是金字塔,简单称为图片金字塔。注意,这些图像都是要一幅幅输入到Pnet中去得到候选的。

- 图片金字塔输入Pnet,得到大量的候选(candidate)。根据上述步骤1得到的图片金字塔,将所有图片输入到Pnet,得到输出map形状是(m, n, 16(2+4+10))。根据分类得分,筛选掉一大部分的候选,再根据得到的4个偏移量对bbox进行校准后得到bbox的左上右下的坐标,对这些候选根据IOU值再进行非极大值抑制(NMS)筛选掉一大部分候选。详细的说就是根据分类得分从大到小排,得到(num_left, 4)的张量,即num_left个bbox的左上、右下绝对坐标。每次以队列里最大分数值的bbox坐标和剩余坐标求出iou,干掉iou大于0.6(阈值是提前设置的)的框,并把这个最大分数值移到最终结果。重复这个操作,会干掉很多有大量overlap的bbox,最终得到(num_left_after_nms, 16)个候选,这些候选需要根据bbox坐标去原图截出图片后,resize为24*24输入到Rnet。

- 经过Pnet筛选出来的候选图片,经过Rnet进行精调。根据Pnet输出的坐标,去原图上截取出图片(截取图片有个细节是需要截取bbox最大边长的正方形,这是为了保障resize的时候不产生形变和保留更多的人脸框周围细节),resize为24*24,输入到Rnet,进行精调。Rnet仍旧会输出二分类one-hot2个输出、bbox的坐标偏移量4个输出、landmark10个输出,根据二分类得分干掉大部分不是人脸的候选、对截图的bbox进行偏移量调整后(说的简单点就是对左上右下的x、y坐标进行上下左右调整),再次重复Pnet所述的IOU NMS干掉大部分的候选。最终Pnet输出的也是(num_left_after_Rnet, 16),根据bbox的坐标再去原图截出图片输入到Onet,同样也是根据最大边长的正方形截取方法,避免形变和保留更多细节。

- 经过Rnet干掉很多候选后的图片输入到Onet,输出准确的bbox坐标和landmark坐标。大体可以重复Pnet的过程,不过有区别的是这个时候我们除了关注bbox的坐标外,也要输出landmark的坐标。(有小伙伴会问,前面不关注landmark的输出吗?嗯,作者认为关注的很有限,前面之所以也有landmark坐标的输出,主要是希望能够联合landmark坐标使得bbox更精确,换言之,推理阶段的Pnet、Rnet完全可以不用输出landmark,Onet输出即可。当然,训练阶段Pnet、Rnet还是要关注landmark的)经过分类筛选、框调整后的NMS筛选,好的,至此我们就得到准确的人脸bbox坐标和landmark点了,任务完满结束。
MTCNN车牌检测
这项工作只使用proposal net(Pnet)和output net(Onet),因为在这种情况下跳过Rnet不会损害准确性。Onet接受24(高度)x94(宽度)bGR图像,这与LPRNet的输入一致。
修改后的MTCNN结构如下:

LPRNet
LPRNet全程就叫做License Plate Recognition via Deep Neural Networks(基于深层神经网络的车牌识别)。LPRNet由轻量级的卷积神经网络组成,所以它可以采用端到端的方法来进行训练。据我们所知,LPRNet是第一个没有采用RNNs的实时车牌识别系统。因此,LPRNet算法可以为LPR创建嵌入式部署的解决方案,即便是在具有较高挑战性的中文车牌识别上。
LPRNet特性
- 实时、高精度、支持车牌字符变长、无需字符分割、对不同国家支持从零开始end-to-end的训练;
- 第一个不需要使用RNN的足够轻量级的网络,可以运行在各种平台,包括嵌入式设备;
- 鲁棒,LPRNet已经应用于真实的交通监控场景,事实证明它可以鲁棒地应对各种困难情况,包括透视变换、镜头畸变带来的成像失真、强光、视点变换等。
LocNet
首先,输入图像由空间变换层(Spatial Transformer Layer)预处理 LocNet 这是对检测到的车牌形状上的校正,使用 Spatial Transformer Layer(这一步是可选的),但用上可以使得图像更好得被识别。

下面是他的效果图,看起来是不是很舒服。

LPRNet的基础构建模块
LPRNet的基础网络构建模块受启发于SqueezeNet Fire Blocks和Inception Blocks,如下图所示。

特征提取骨干网络架构
骨干网将原始的RGB图像作为输入,计算得到空间分布的丰富特征。为了利用局部字符的上下文信息,该文使用了宽卷积(1×13 kernel)而没有使用LSTM-based RNN。骨干网络最终的输出,可以被认为是一系列字符的概率,其长度对应于输入图像像素宽度。
由于解码器的输出与目标字符序列长度不同,训练的时候使用了CTC Loss,它可以很好的应对不需要字符分割和对齐的end-to-end训练。

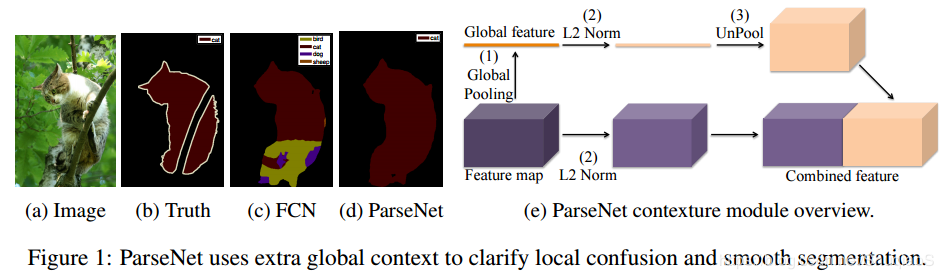
为了进一步地提升模型的表现,增强解码器所得的中间特征图,采用用全局上下文关系(global context)进行嵌入。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小,最后再与骨干网络的输出进行拼接 , 加入GAP思想源于Parsenet。下图为加入GAP拼接到feature map上进行识别的表示。
CCPD数据集
CCPD(中国城市停车数据集,ECCV)和PDRC(车牌检测与识别挑战)。这是一个用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
https://github.com/detectRecog/CCPD
该数据集在合肥市的停车场采集得来的,采集时间早上7:30到晚上10:00.涉及多种复杂环境。一共包含超多25万张图片,每种图片大小720x1160x3。一共包含9项。每项占比如下:
| CCPD- | 数量/k | 描述 |
|---|---|---|
| Base | 200 | 正常车牌 |
| FN | 20 | 距离摄像头相当的远或者相当近 |
| DB | 20 | 光线暗或者比较亮 |
| Rotate | 10 | 水平倾斜20-25°,垂直倾斜-10-10° |
| Tilt | 10 | 水平倾斜15-45°,垂直倾斜15-45° |
| Weather | 10 | 在雨天,雪天,或者雾天 |
| Blur(已删除) | 5 | 由于相机抖动造成的模糊(这个后面被删了) |
| Challenge | 10 | 其他的比较有挑战性的车牌 |
| NP | 5 | 没有车牌的新车 |
数据标注:
文件名就是数据标注。eg:
025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
由分隔符-分为几个部分:
-
025为区域, -
95_113对应两个角度, 水平95°, 竖直113° -
154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473) -
386&473_177&454_154&383_363&402对应四个角点坐标 -
0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y…
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
-
37亮度 -
15模糊度
所以根据文件名即可获得所有标注信息。
