常用数据处理
这里主要介绍了包括以下几种类型的数据处理:
- 数值型数列均值、方差、分位数的计算
- 噪声数据过滤
- 缺失值补全方法
1. 实现数值型数列均值、方差、分位数的计算
1.1 均值计算
1、传入数据;
2、然后是构造计算均值的函数;
3、步骤为:(1)传入要计算列的参数;(2)设置变量存储该列数据的总和,以及设置变量存储数据的长度;(3)长度调用len()函数;(4)数据总和循环整个长度(也可以设置循环当有值存在时,长度加1,同时累加数据的和);(5)数据总和除以数据长度得到均值(需满足长度不为0);
4、调用函数,得到计算结果:
def LoadData(dataSet):
data = pd.read_csv(dataSet)
data.replace(to_replace='NaN', value=0, regex=True, inplace=True)
return data
def GetMean(dataSet):
"计算均值"
sumOfData = 0 #存储数据的总和
lengthOfData = len(dataSet) #存储数据的长度
for i in range(len(dataSet)):
#循环求和
sumOfData = sumOfData + float(dataSet.loc[i])
if lengthOfData != 0 :
#返回均值
return sumOfData/lengthOfData
else:
return '此数据无均值'1.2 方差计算
1、传入数据;
2、然后是构造计算方差的函数;
3、步骤为:(1)传入要计算的数据列;(2)设置变量存储该列的均值,调用之前构造的均值计算函数;(3)设置变量存储数据列中每个值与均值差值的平方和,通过循环整个数据列的长度,其中平方和计算调用了pow(x,2)函数,也可以使用x**2计算;(4)若数据长度不为0返回方差结果。
4、调用函数,得到计算结果:
def LoadData(dataSet):
data = pd.read_csv(dataSet)
data.replace(to_replace='NaN', value=0, regex=True, inplace=True)
return data
def GetVar(dataSet):
"计算方差"
average = GetMean(dataSet) #得到均值
lengthOfData = len(dataSet)
variance = 0
for i in range(len(dataSet)):
#首先计算各值与均值差值的平方和
variance = variance + pow(float(dataSet.loc[i]) - average,2)
if lengthOfData != 0:
return variance/lengthOfData
else:
return '无标准差'1.3 分位数计算
1、传入数据:随机输入乱序的列表
2、然后是构造分位数计算函数;
3、步骤为:(1)传入参数为数据列和要计算的分位数的数值;(2)判断分位数是否输入正确,错误则直接返回;(3)对传入的数据列进行升序排序;(4)确定该分位数的位置,即长度与分位数的乘积,若位置坐标不为整数时,向上取整;(5)根据位置坐标来选取分位数的数值结果,位置大于1时在列表中的坐标为实际位置减1,位置小于1时,即第一个点的位置。
4、调用函数,得到计算结果:
def LoadData(dataSet):
data = pd.read_csv(dataSet)
data.replace(to_replace='NaN', value=0, regex=True, inplace=True)
return data
def GetQuantile(dataSet,percent):
"计算分位数"
if percent >=1 or percent < 0:
return '分位数数值传入出错,需要在0-1之间'
dataSet.sort()
print(dataSet)
#如果不为整数,向上取整
i = math.ceil(len(dataSet)*percent)
print(i)
if i > 1 :
quantile = float(dataSet[i-1])
else :
quantile = float(dataSet[0])
return quantile2. 噪声数据过滤
2.1 噪声数据过滤–最大最小阈值过滤噪声数据
1、传入数据列dataframe类型或者其他的如列表格式也可以,只是对每个数据值的操作不同,构造函数;
2、步骤为:(1)传入参数数据列、最大最小的阈值;(2)通过循环整个数据列的长度,对每个数据进行数值大小判断,当该数据小于最小阈值或者大于最大阈值时,数据置空,最后返回数据列。
3、函数调用,以及输出结果。
def FilterNoiseThreshold(dataSet,maxThreshold,minThreshold):
"利用最大最小的阈值来过滤噪声数据"
for i in range(len(dataSet)):
if float(dataSet.loc[i]) < minThreshold or float(dataSet.loc[i]) > maxThreshold:
dataSet.loc[i] = np.nan
return dataSet2.2 噪声数据过滤–等频装箱均值填充过滤噪声数据
1、等频装箱:将数据排序后,分为不同箱子,在每个箱子中数据的个数一样,使用每个箱子的均值来填充每个箱子中的原本的值,进行噪声平滑处理。
2、传入数据列。
3、构造等频装箱函数。
def GetFrequencySpiltbox(data,box):
"等频装箱:每个箱子用均值填充"
data.sort() #首先进行排序
print(data)
flag = len(data) % box #用于判断最后面的箱子是否刚好分完
dict = {} #存储于字典中
#最后的箱子不能分完
if flag >= 1:
boxNum = len(data)/box + 1
i = 0
j = 0 #盒子长度的移动
for i in range(int(boxNum)-1):
dict[i] = data[0+j:box+j]
j = j + box
# #均值填充
# dict[i] = [GetMean(DataFrame(dict[i]))]*len(DataFrame(dict[i]))
dict[i+1] = data[j:]
#print(dict[i+1])
dict[i+1] = [GetMean(DataFrame(dict[i+1]))]*len(DataFrame(dict[i+1]))
#箱子刚好分完
else:
boxNum = len(data)/box
i = 0
j = 0
for i in range(int(boxNum)):
dict[i] = data[0+j:box+j]
j = j + box
# #均值填充
# dict[i] = [GetMean(DataFrame(dict[i]))]*len(DataFrame(dict[i]))
print('每个箱子的个数为:'+str(box))
for value in dict:
#print('第'+str(value+1)+'个箱子用均值平滑结果')
print('第'+str(value+1)+'个箱子结果')
print(dict[value])2.3 噪声数据过滤–等宽装箱均值填充过滤噪声数据
1、等宽装箱:将数据排序后,分为不同箱子,在每个箱子中数据最大最小的差值是一样的,即箱子的宽度相同,使用每个箱子的均值来填充每个箱子中的原本的值,进行噪声平滑处理。
2、传入数据列。
3、构造等宽装箱函数。
def GetWidthSpiltbox(data,width):
"等宽装箱:每个箱子用均值填充"
data.sort() #首先进行排序
print(data)
t=0
i=width
box = []
for line in data:
#判断当前值是否大于第一个值加宽度,如果大于就需要放进下一个箱子
if line >= (data[t]+i):
#返回line这个值在data列表中的位置
ind = data.index(line)
#为当前箱子赋值
box.append(data[t:ind+1])
#当前游标为索引值再后移1个单位
t = ind
t += 1
#如果line已经到达最后了,不管是否达到宽度都属于最后一个箱子
elif line == data[len(data)-1]:
ind = data.index(line)
box.append(data[t:ind+1])
print('设定区间范围为:'+str(width))
for i in range(len(DataFrame(box))):
print('第'+str(i+1)+'个箱子分箱结果为:')
# for j in range(len(DataFrame((box[i])))):
# box[i] = list(DataFrame(box[i]).mean())*len(DataFrame((box[i])))
print(box[i])3. 缺失值补全方法
3.1 缺失值填充–均值/分位数填充缺失值
1、传入数据列,构造函数;
2、步骤为:(1)传入需要填充的数据列参数;(2)首选将数据中的缺失值替换为0;(3)均值填充:如果当前值为0,则调用均值函数替换当前值;(4)分位数填充:如果当前值为0,则调用分位数函数替换当前值;(5)返回缺失值补全的数据列。
3、函数调用,以及输出结果。
def GetFillMissing(dataSet):
"均值和分位数填充缺失值"
dataSet.replace(to_replace='NaN', value=0, regex=True, inplace=True)
#均值填充GetMean(dataSet.H3MeK4_N)
dataSet.H3MeK4_N = dataSet.H3MeK4_N.map(lambda x : GetMean(dataSet.H3MeK4_N) if x==0 else x)
#分位数填充GetQuantile(dataSet,percent)
#dataSet.H3MeK4_N = dataSet.H3MeK4_N.map(lambda x : GetQuantile(list(dataSet.H3MeK4_N),0.5) if x==0 else x)
return dataSet3.2 缺失值填充–启发式补全
—————–启发式补全是数据分析最常用的填充方式,能够很好消除一些不确定性,让结果更加精确。比如此处以男女身高缺失为例,直接使用均值、中位数或者其他进行填充,效果必定差于用男性均高填充男性缺失身高,女生同理。如果属性更多,也可以使用更多的属性来进行启发式补全,比如出生年龄、出生地、家庭背景等等属性。
1、传入dataframe类型的数据,0代表女性,1代表男性:
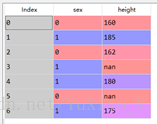
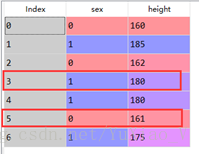
2、启发式补全:对于其中3号男性和5号女性使用启发式补全缺失的身高,想要用女性的平均身高填充5号身高,用男性的平均身高填充3号的身高。
3、函数调用;
4、步骤为:(1)首先填充缺失值为0;(2)循环所有的数据,对于性别为女的身高求一次平均值,对于身高为男性的求一次平均值;(3)再循环所有的数据,给对应性别的身高缺失的数据填充对应的性别的身高均值。
5、调用函数,结果为:
def GetFillMissingHeuristic(data):
"启发式补全"
sex = data.sex
height = data.height
data.replace(to_replace='NaN', value=-1, regex=True, inplace=True)
sumHeight0 = 0
len0 = 0
sumHeight1 = 0
len1 = 0
for i in range(len(data)):
if (int(sex.loc[i]) == 0) & (int(height.loc[i])!=-1):
sumHeight0 += height.loc[i]
len0 += 1
elif (int(sex.loc[i]) == 1) & (int(height.loc[i])!=-1):
sumHeight1 += height.loc[i]
len1 += 1
for i in range(len(data)):
if (int(data['height'].loc[i]) == -1) & (int(data['sex'].loc[i]) == 0):
data['height'].loc[i] = sumHeight0/len0
if (int(data['height'].loc[i]) == -1) & (int(data['sex'].loc[i]) == 1):
data['height'].loc[i] = sumHeight1/len1
return data