pandas数据处理
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
pd.__version__
# 就是pandas模块,对一些汉字,处理不好,版本会继续升级的
# 结果:'0.22.0'1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True¶
# age 11, 12, 13, 14 , 15, 17 ,17
# 在mysql中有属性表, 城市, 省份, 城市的名字只能是唯一, 唯一键的效率低
# 如果有属性数据重复, 那么pandas拿到的就是一个带有数据冗余的表
df = DataFrame({'color':['white','red','white'], 'size':[10,20,10]})
df
# 检查的是不是重复值, 不是就返回false, 是重复的就返回true
df.duplicated()
# 结果如下:
0 False
1 False
2 True
dtype: bool使用drop_duplicates()函数删除重复的行
df.drop_duplicates()
# 结果如下:
如果使用pd.concat([df1,df2],axis = 1)生成新的DataFrame,新的df中columns相同,使用pandas低版本使用duplicate()和drop_duplicates()都会出问题
df2 = pd.concat([df,df], axis=1)
df2
# 结果如下:
df2.duplicated()
# 结果如下:
0 False
1 False
2 True
dtype: booldf2.drop_duplicates()
# 结果如下:
# 如果真的出现了两列完全相同, 那么我们该怎么删除列
df3 = df2.drop_duplicates().T
df3
# 如何删除相同的行和列
df3.drop_duplicates().T
# 结果如下:
2. 映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
需要使用字典:
map = {
'label1':'value1',
'label2':'value2',
...
}
包含三种操作:
- replace()函数:替换元素
- 最重要:map()函数:新建一列
- rename()函数:替换索引
1) replace()函数:替换元素
df
# 结果如下:
d = {'white':255, 'red':128}
df.replace(to_replace=d)
# 结果如下:
df['size'][0] = np.nan
df
# map也可以用来检索文章中的敏感字
# 结果如下:
使用replace()函数,对values进行替换操作
作用:
数据处理时,需要将,String类型转换成int,然后才可以进行计算机运算
性别,男:0;女:1
首先定义一个字典
调用.replace()
replace还经常用来替换NaN元素
# 我们的表中. 如果有nan, 有就填充0, fillna(), 现在用map进行操作
d = {np.nan:0}
df.replace(d)
# 结果如下:
2) map()函数:新建一列
使用map()函数,由已有的列生成一个新列
适合处理某一单独的列。
df2 = DataFrame(np.random.randint(0,150,size=(4,2)),
columns=['Python', 'Java'], index=list('abcd'))
df2
# 结果如下: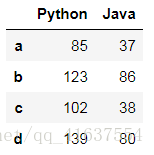
# 使用map函数新建一列
# 生成一个Math的列
df2['Math'] = df2['Python'].map(lambda x : x + 20)
df2
# 结果如下: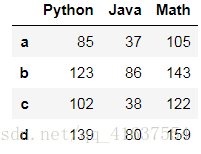
def level(x):
if x > 100:
return '完美'
elif x < 100 and x >= 80:
return '优秀'
elif x < 80 and x >= 60:
return '及格'
else:
return '不及格'
# 用数学成绩判断标准
df2['level'] = df2['Math'].map(level)
df2
# 结果如下: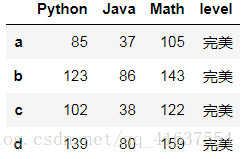
仍然是新建一个字典
map()函数中可以使用lambda函数
transform()和map()类似
transform是变形的意思
transform中的值只能是一个function
df2['Math'] = df2['Math'].transform(lambda x:x + np.random.randint(0, 50, size=1)[0])
df2
# 结果如下: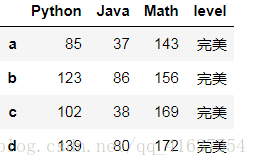
# 删除level列
df2.drop('level', axis=1, inplace=True)
df2
# 结果如下: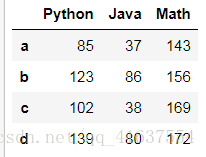
# 我们在pandas中map和transfrom最大的区别就是一个可以使用dict, 一个不能使用
df2['level'] = df2['Java'].transform(level)
df2
3) rename()函数:替换索引
仍然是新建一个字典
使用rename()函数替换行索引
# df2.index[0] = '张三' 这种替换方式是错误的
# rename 要替换的索引存在则替换, 不存在就不管
df2.rename({'a':'张三','Python':'大蟒蛇'}, axis=1)
# 结果如下: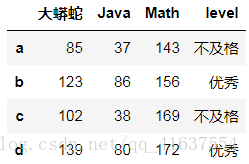
# rename中的参数值可以是一个func
def index_rename(item):
if item == 'a':
return '张三'
else:
return '李四'
df2.rename(index_rename)
# 结果如下:
3. 异常值检测和过滤
使用describe()函数查看每一列的描述性统计量
# 数据中比较大的, 或者特别小的, 都可以认为是异常值
# 大头儿子和小偷爸爸都算是人类中的异常值
# NaN也是异常值
df3 = DataFrame(np.random.randint(0,150,size=(10,4)),
columns=['Python','Java','PHP','VR'])
df3
# 结果如下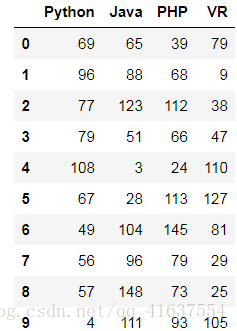
df3.describe()
# 结果如下:
使用std()函数可以求得DataFrame对象每一列的标准差
df3.std()
# 结果如下:
Python 28.436284
Java 44.721484
PHP 36.054896
VR 40.832993
dtype: float64根据每一列的标准差,对DataFrame元素进行过滤。
借助any()函数, 测试是否有True,有一个或以上返回True,反之返回False
对每一列应用筛选条件,去除标准差太大的数据
# 大于70的数据,我们认定为异常值
cond1 = df3 >= 70
cond2 = cond1.all(axis=1) # 如果所有的值都为True, 才返回True
df3[cond1]
# 结果如下: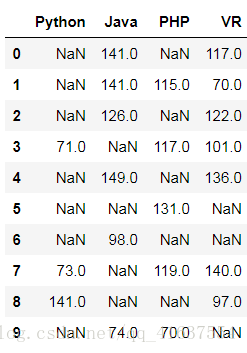
删除特定索引df.drop(labels,inplace = True)
4. 排序
使用.take()函数排序
可以借助np.random.permutation()函数随机排序
# 生成指定大小的矩阵
np.random.permutation(5)
# 结果:array([0, 3, 2, 1, 4])df2
# 结果如下: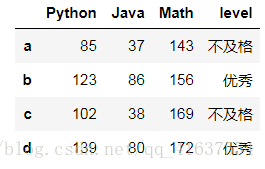
# 倒叙排序
df2.iloc[::-1]
# 结果如下: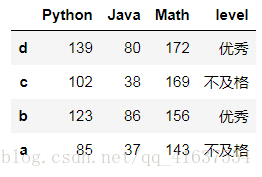
# 通过手写的方式将矩阵进行颠倒
df2.take([3,2,1,0])
# 结果如下: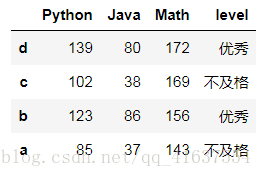
# 怎么进行一个随机的排序
df2.take(np.random.permutation(4), axis=1)
随机抽样
当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样
df4 = DataFrame(np.random.randint(0,150,size=(10,4)),
columns=['Python','Java','Math','China'])
df4
# 结果如下:
df4 = DataFrame(np.random.randint(0,150,size=(1000,4)),
columns=['Python','Java','Math','China'])
# 抽取1000行当中的50个
# 公司年会可以做一个抽奖系统
df4.take(np.random.randint(0,1000,size=50))5. 数据聚合【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心: groupby()函数
groupby() 在整个pandas中也担任分组的重担
如果想使用color列索引,计算price1的均值,可以先获取到price1列,然后再调用groupby函数,用参数指定color这一列
使用.groups属性查看各行的分组情况:
df5 = DataFrame({'item':['萝卜','白菜','西红柿','辣椒','冬瓜','萝卜','西红柿','白菜','西红柿','辣椒','冬瓜'],
'seller':['李大妈','李大妈','李大妈','王大妈','王大妈','王大妈','王大妈','赵大妈','赵大妈','赵大妈','赵大妈'],
'price':np.random.randint(3,10,size=11)},
columns = ['item','seller','price'])
df5
# 结果如下:
# 首先是分组, 然后是找出一个最小值
# 找出各种蔬菜中最便宜的
df5.groupby(['item']).min()
# 找出各种蔬菜中最贵的
df5.groupby(['item']).max()# 求平均值, 并且添加前缀
mean_price = df5.groupby(['item']).mean().add_prefix('mean_')
mean_price
# 结果如下: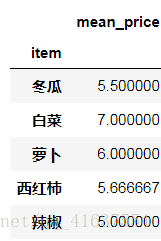
# 把得到的平均值融合到原表中
# left_on 设定左边表的关联列, 右表对齐, 多对多
df6 = pd.merge(df5,mean_price, left_on='item', right_index=True)
df6
# 结果如下: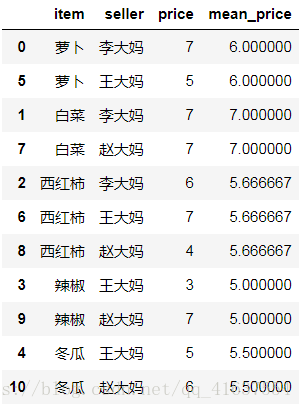
# 先求一个平方差, 求各个蔬菜的价格波动
price_std = df5.groupby(['item']).std().add_prefix('std_')
price_std
# 结果如下: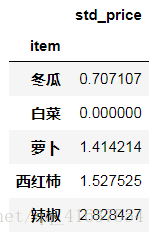
# 将蔬菜的波动值融合到原数据中
df7 = pd.merge(df6, price_std, left_on='item',right_index=True)
df7
# 结果如下: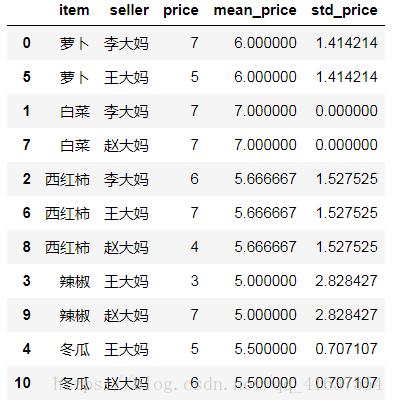
# std()标准平方差, 看数据的波动, 描述情况
def std_price(std_p):
if std_p >= 2.5:
return '价格太坑'
elif 1 < std_p < 2.5:
return '价格稳定'
else:
return '良心菜价'# map()
# 将各个蔬菜的价格情况添加为一列
df7['std_p'] = df7['std_price'].map(std_price)
df7
# 结果如下: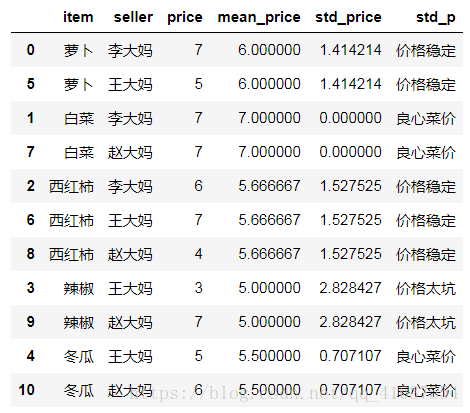
6.0 高级数据聚合
可以使用pd.merge()函数将聚合操作的计算结果添加到df的每一行
使用groupby分组后调用加和等函数进行运算,让后最后可以调用add_prefix(),来修改列名
可以使用transform和apply实现相同功能
在transform或者apply中传入函数即可
# 将各个蔬菜的价格求和
df7.groupby(['item'])['price'].sum()
# 结果如下:
item
冬瓜 11
白菜 14
萝卜 12
西红柿 17
辣椒 10
Name: price, dtype: int32df7.groupby(['item'])['price'].transform(sum)
# 结果如下:
0 12
5 12
1 14
7 14
2 17
6 17
8 17
3 10
9 10
4 11
10 11
Name: price, dtype: int32transform()与apply()函数还能传入一个函数或者lambda
df = DataFrame({'color':['white','black','white','white','black','black'],
'status':['up','up','down','down','down','up'],
'value1':[12.33,14.55,22.34,27.84,23.40,18.33],
'value2':[11.23,31.80,29.99,31.18,18.25,22.44]})
apply的操作对象,也就是传给lambda的参数是整列的数组
# np.mean()
# apply 与 transform最大的区别, 在于transform做了循环(交叉表)
df7.groupby(['item'])['price'].apply(sum)
# 结果:
item
冬瓜 11
白菜 14
萝卜 12
西红柿 17
辣椒 10
Name: price, dtype: int64df7.groupby(['item'])['price'].apply(np.mean)
# 结果是:
item
冬瓜 5.500000
白菜 7.000000
萝卜 6.000000
西红柿 5.666667
辣椒 5.000000
Name: price, dtype: float64绘图函数
Series和DataFrame都有一个都有一个生成各类图标的plot方法,默认情况下锁生成的都是线形图
# java php
# python golang mysql redis mongo http 设计模式(和python没什么大的联系, python讲究的是简洁,
# 而这个指的是多分类)
# 引导别人
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
# matplotlib不引入, 在调用plot()时候不会报错, 但是图片也显示不出来
# pandas和matplotlib进行了深度的合作
import matplotlib.pyplot as plt线形图
简单示例:Series图例表示.plot()
s = Series(np.random.randint(0,20,size=10))
s
# 结果:
0 7
1 15
2 14
3 5
4 10
5 11
6 7
7 12
8 4
9 14
dtype: int32s.plot()
# 结果是:
简单的DataFrame图标实例.plot()
df = DataFrame(np.random.randint(0,150,size=(5,4)),
columns=['Python','Java','PHP','Ruby'])
df.plot()
# 结果是:
柱状图
DataFrame柱状图例
df.plot(kind='bar')
df.plot(kind='barh')
# 结果是:
读取tips.csv,查看每天聚会人数,每天各种聚会规模的比例饿 求和并df.sum(),注意灵活使用axis()
tip = pd.read_csv('../data/tips.csv')
tip
# 行 代表的是星期几
# 列 代表的是几个人一起去吃饭
# 结果是:
将第一列day数据编程行索引set_index
tip.set_index(keys='day',inplace=True)
tip
# 结果如下:
tip.plot(kind='bar')
# 结果是:
# 将不重要的数据去除掉
tip.drop(axis=1,labels=['1','6'],inplace=True)
tip.plot(kind='bar')
# 下课自己去尝试一下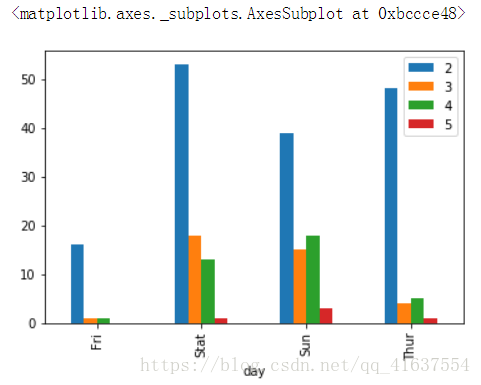
# 还能用什么方法保留2-5之间的数据
tip.iloc[:,2:5].plot(kind='bar')
# 结果如下: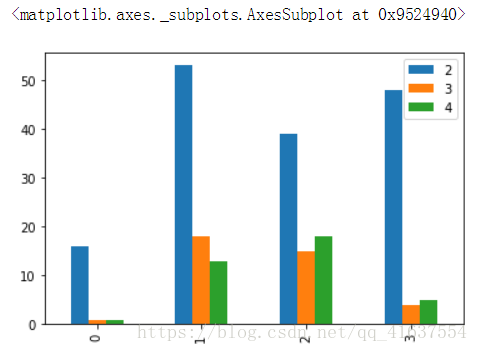
直方图
random生成随机直方图,调用hist()方法
nd = np.random.randint(0, 10, size=10)
nd
# 结果:array([4, 1, 8, 7, 5, 0, 4, 3, 6, 1])s = Series(nd)
# binds 默认值是10 值越大,条越细
s.hist(bins=100)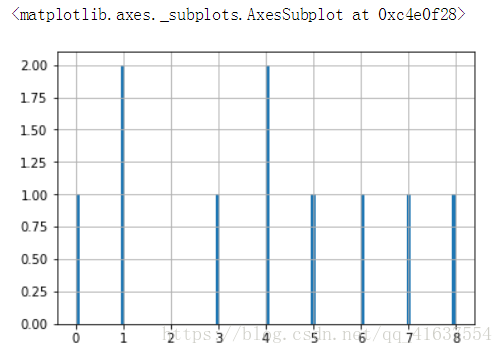
随机百分比密度图
# density 密度
s.plot(kind='kde')
# 结果如下: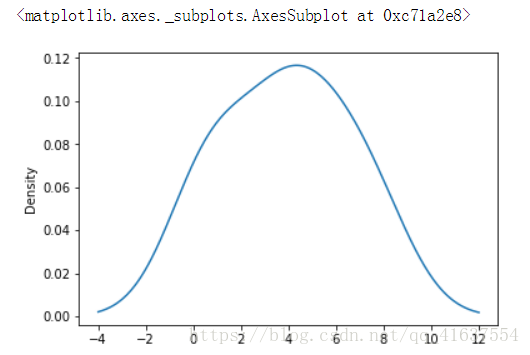
这两张表经常会被画在一起,直方图以规格形式给出(以便画出密度图),然后在再其上绘制核密度估计。
接下来看看一个由两个不同de 标准正太正太分布组成的双峰分布。
np.random.normal()正太分布函数
直方图hist,函数中心必须添加属性normed = True
nd1 = np.random.normal(loc=15,scale=5,size=1000)
nd2 = np.random.normal(loc=-5,scale=1,size=1000)
nd3 = np.concatenate([nd1,nd2])
nd3
# 结果是:array([11.58565851, 13.64360712, 14.05157839, ..., -5.2255662 ,
# -4.84837998, -4.67554639])s8 = Series(nd3)
# 密度图
s8.plot('kde')
# 结果如下: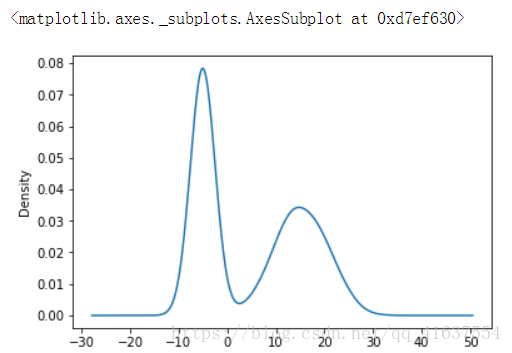
s8.hist(bins=70)
# 结果如下: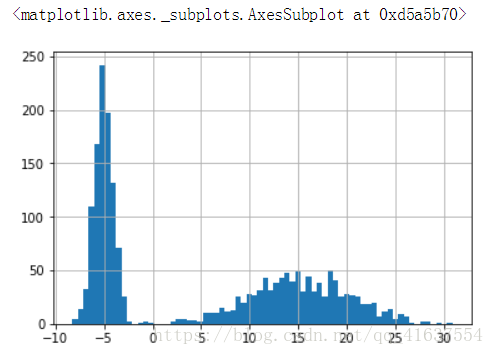
s8.plot('kde')
# 怎么解决密度线趴下来的问题
# normed 统一的, 是将数据归一化
s8.hist(bins=70, normed=True)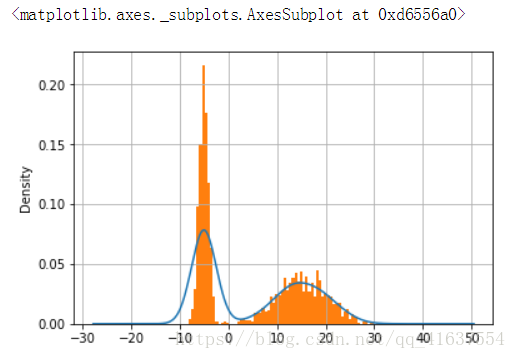
散布图
df = DataFrame(np.random.randint(0,150,size=(10,3)),
columns=['Python','Java','PHP'])
df
# 结果如下: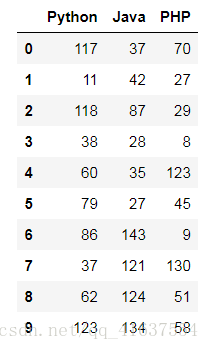
df['C++'] = df['Python'] * 1.2
df
# 结果如下: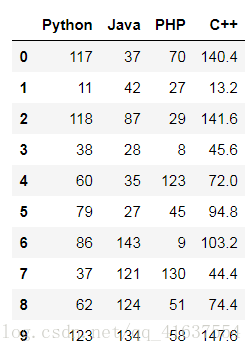
散布图 散布图是观察两个一维数据列之间的关系的有效方法
注意是用kind=’scatter’ , 给标签columns
# scatter是散布图, 可以找到两组数据之间的关系
df.plot(kind='scatter', x='Python', y='Java')
# 结果如下: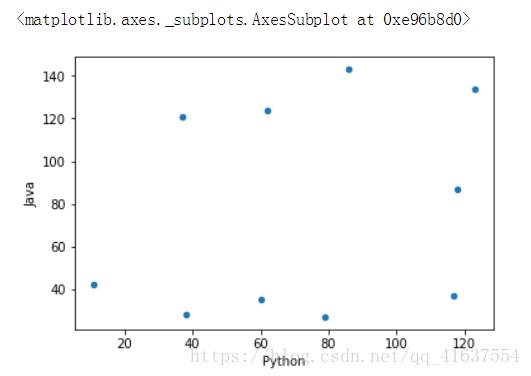
# 因为Python的成绩和C++的成绩是相关联的, 所以分布图都在一条直线上
df.plot(kind='scatter', x='Python', y='C++')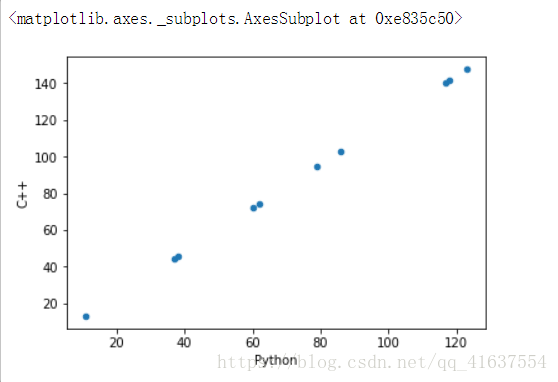
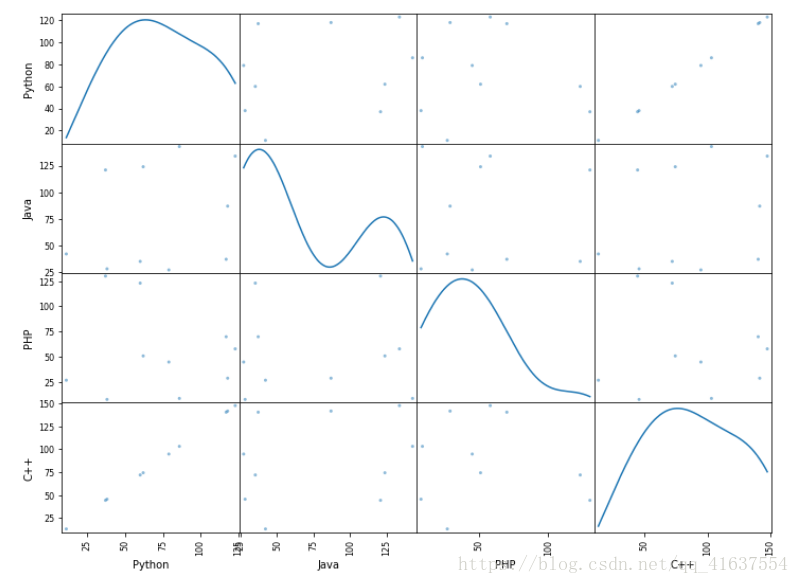
散布图矩阵,当有多个时,两两点之间的联系
函数:pd.plotting.scatter_matrix(),注意参数diagnol:对角线
pd.plotting.scatter_matrix(df, figsize=(12,9), diagonal='kde')
# 散布图可以让我们找到两列数据之间的关系,
# 1. 如果数据量太小, 两列数据没有关系, 加大数据量, 又会形成关系
# 2. 并不是说数据量越大, 两列之间的关系就会越明确, 在数据量过大的情况下, 关系会发生改变