文章目录
1、缺失值处理
1.1、缺失值的产生
①有些信息暂时无法获取
②有些信息被遗漏或者错误处理了
1.2、缺失值的处理方式
①数据补齐
②删除对应缺失行
③不处理
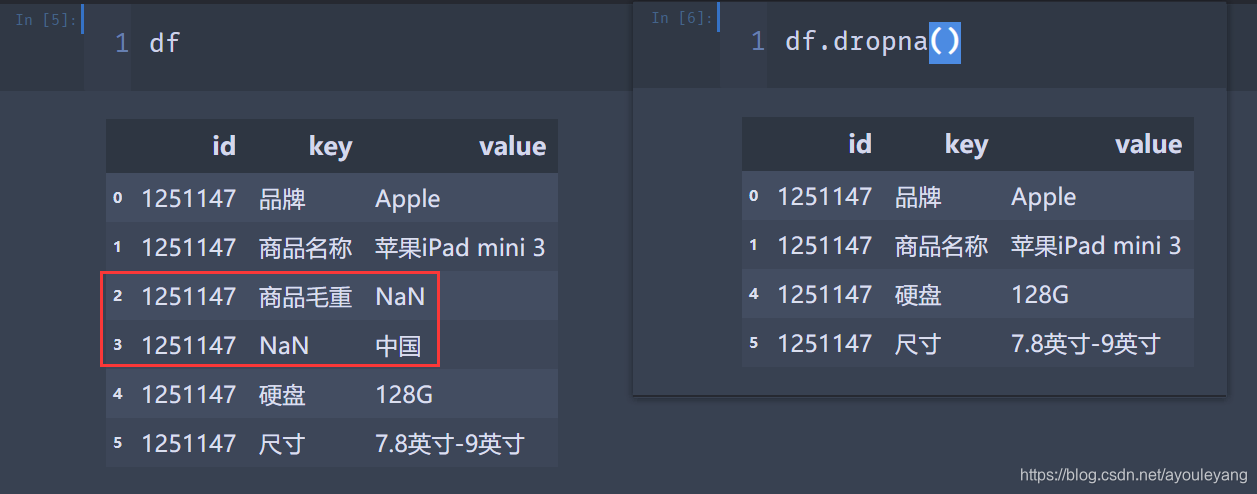
■dropna函数作用:去除数据结构中值为空的数据。
■dropna函数语法: dropna()
1.2.1、导入数据:
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.4\\data.csv")
1.2.2、:去掉缺失值
df.dropna()
2、空格数据处理
2.1、空格数据实列
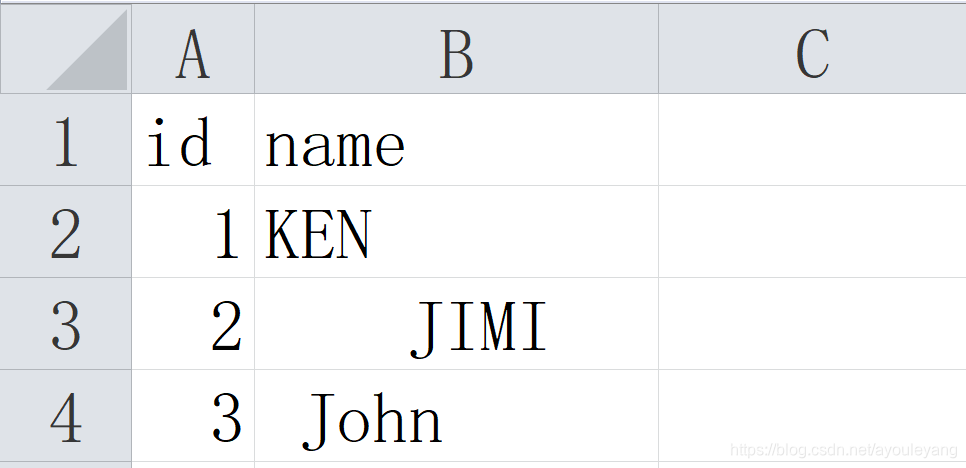
2.2、导入数据实列
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.5\\data.csv")
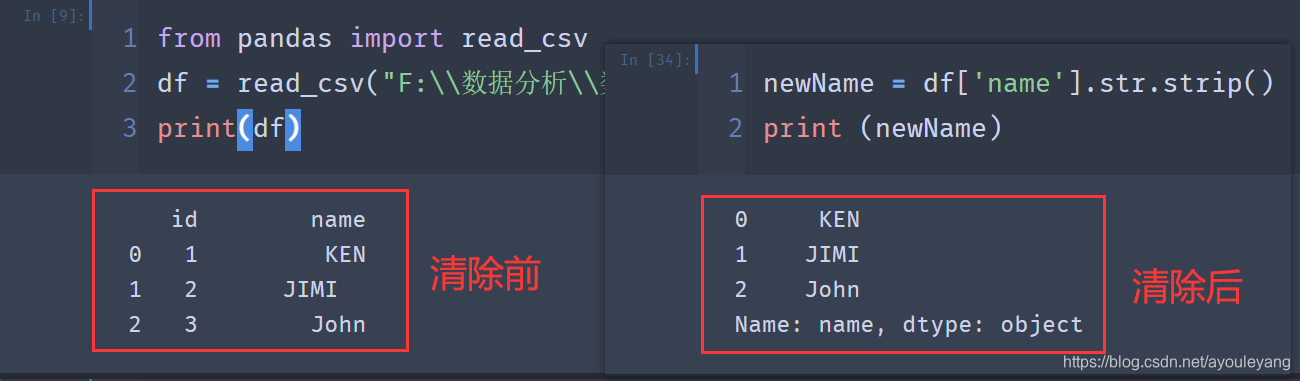
2.3、清除左右空格方法
■strip函数作用:清除字符型数据左右的空格。
■strip函数语法: strip()
df['name'].str.strip()#name数据为头部索引
3、数据字段抽取
■字段抽取,是根据已知列数据的开始和结束位置,抽取出新的列
■字段截取函数: slice(start, stop)
3.1、导入数据
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.6\\data.csv")
print (df)
tel
0 18922254812
1 13522255003
2 13422259938
3 18822256753
4 18922253721
5 13422259313
6 13822254373
7 13322252452
8 18922257681
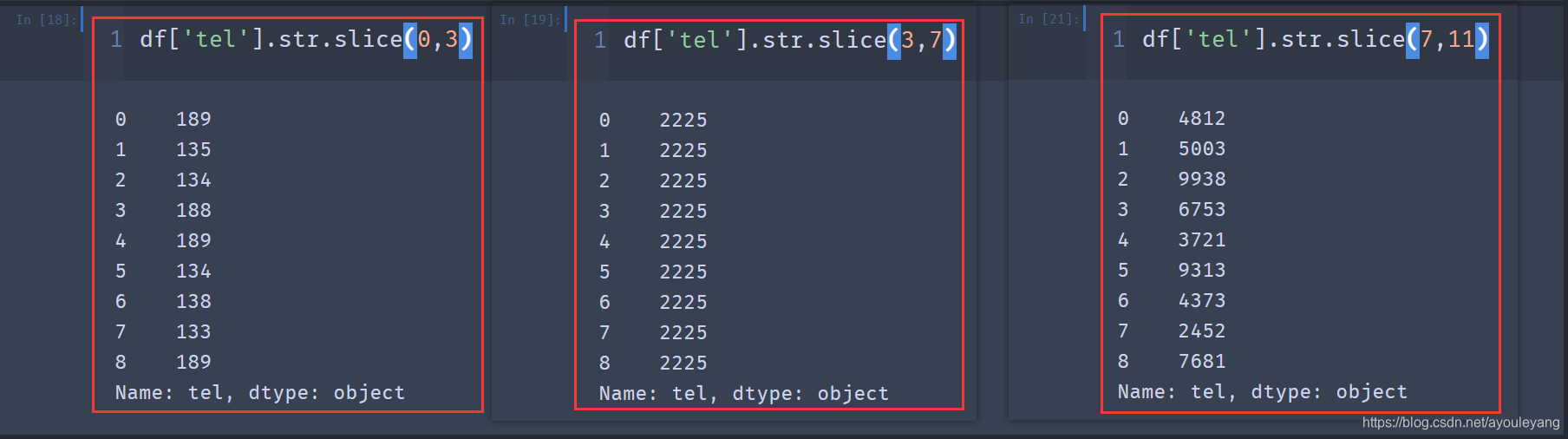
3.1、片段抽取
3.1.1、先把数据转化为字符型,才能进行切割
df['tel'] = df['tel'].astype(str)
3.1.2、选择切割范围
df['tel'].str.slice(0,3)
3.1.2、抽取结果
4、字段拆分
■字段拆分,是指按照固定的字符,拆分已有字符串
■字符分割函数: split(sep, n, expand=False)
| 参数说明 | 注释 |
|---|---|
| sep | 用于分割的字符串 |
| n | 分割为多少列 |
| expand | 是否展开为数据框,默认为False,返回Series;如果expand为True ,则返回DataFrame |
4.1、导入数据
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.7\\\data.csv")
print (df)
输出结果:
name
0 Apple iPad mini MF432CH/A 7.9英寸平板电脑 (16G WiFi版...
1 华为 MediaPad 7Vogue S7-601c(8G) 7英寸通话平板电脑-电信版
2 昂达(ONDA) V975m四核 2G主频最强A9四核 八核GPU 2G内存 16G 204...
3 昂达(ONDA) V975四核 (9.7英寸 A31四核八显 32G 2048*1536视网...
4 华为(HUAWEI) 荣耀X1 7英寸(月光银)3G通话平板 WCDMA/GSM
5 酷比魔方(CUBE) TALK7X四核 7.0英寸平板电脑(MTK8382 IPS全视角屏 ...
6 惠普(HP) Slate 7 3G通话平板(双卡双待7英寸 四核 IPS 超清炫屏 )
7 酷比魔方(ACUBE) TALK97 9.7英寸平板电脑(MTK8382 IPS大猩猩屏 3...
8 三星(SAMSUNG) GALAXY NotePro P901 12.2寸平板电脑 (双四核...
9 宏碁(acer) P3-131-21292G06as 11.6英寸变形触控本 (奔腾2129...
4.2、数据拆分
- 在拆分数据前,需要先分析原数据由什么来间隔开,才能进行拆分,如图:

- 把数据分为10列
df["name"].str.split(" ",10,True)
- 结果如图示:
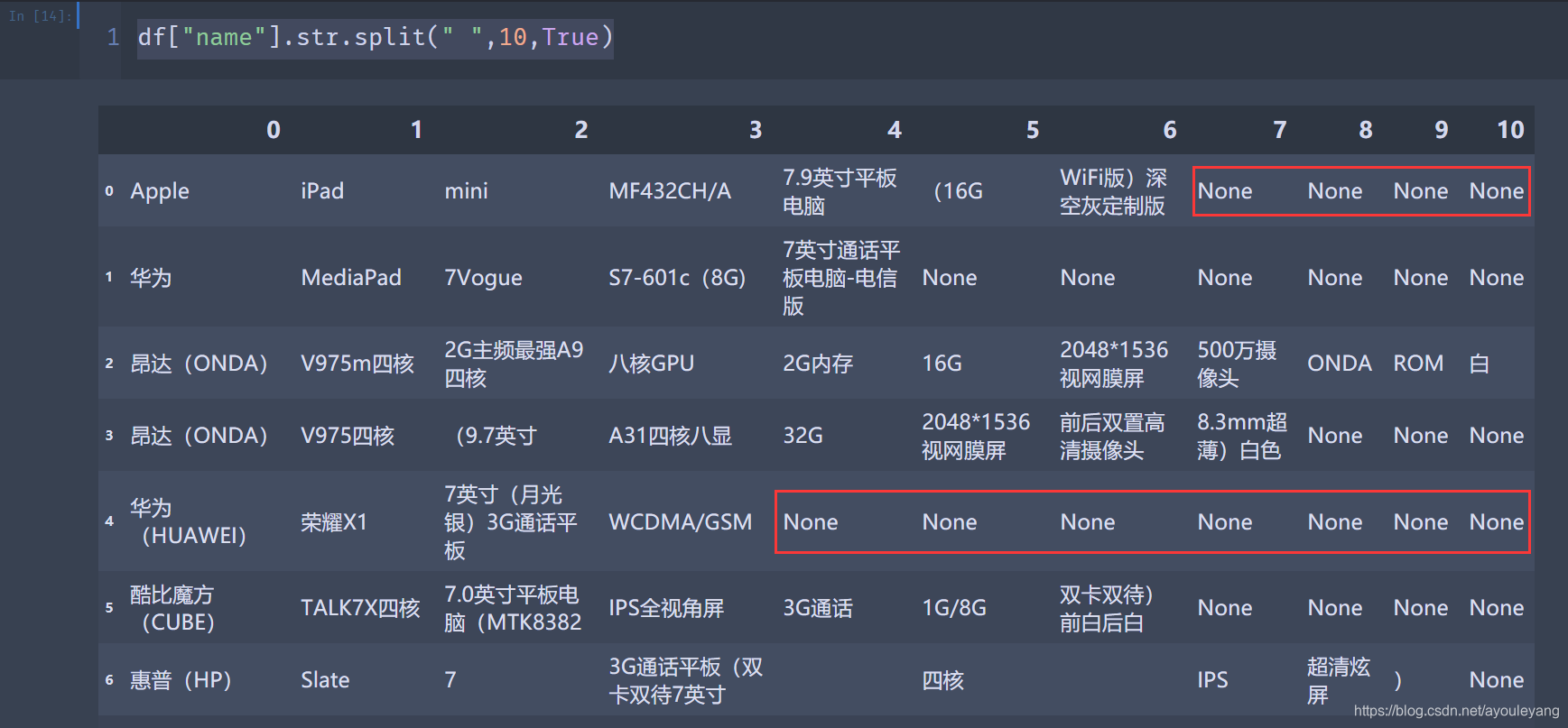
结论:如果数据的长度不一样,它会用“None”不全空格,显示完所有数据。
4.3、将结果保存到csv
filePath = "G:\\数据分析学习\\split.csv"
d.to_csv(filePath,index=True,header=True)
CSV截屏:

4.4、给数据加上列名
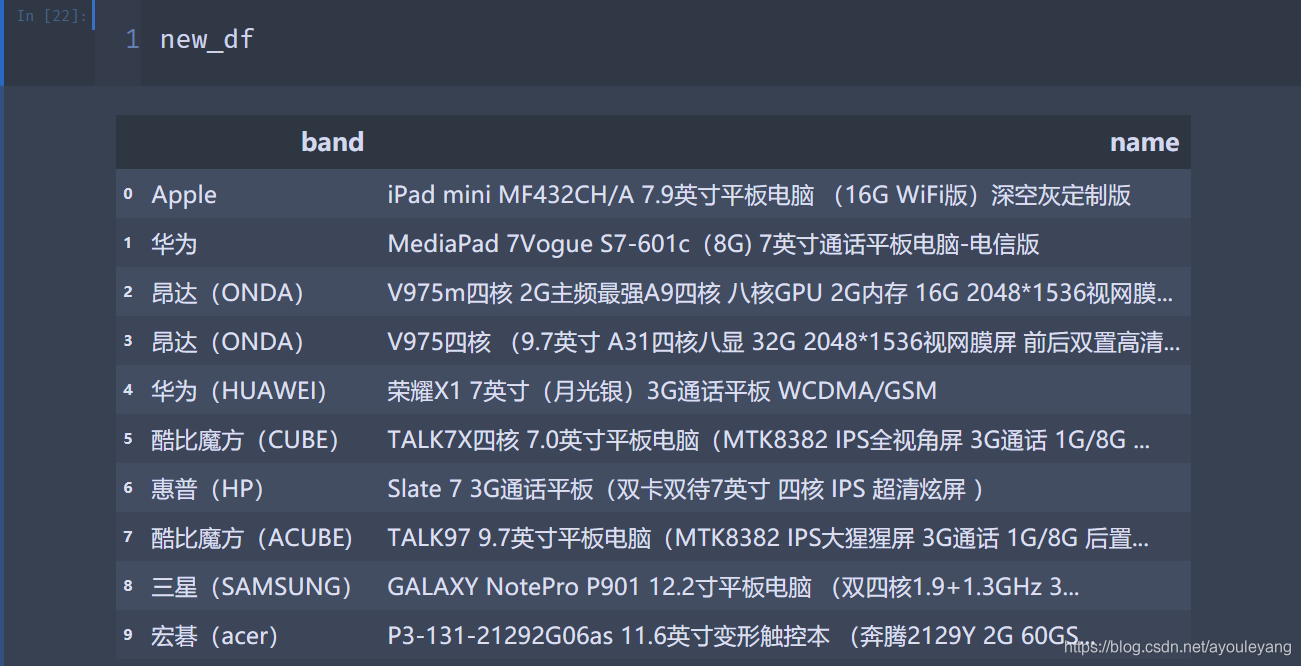
- 先把数据切分为两栏,第一列命名为band,第二列命名为name
new_df = df["name"].str.split(" ",1,True)
new_df.columns = ["band","name"]
5、记录抽取
■记录抽取,是指根据一定的条件,对数据进行抽取
■记录抽取函数: dataframe[condition]
■参数说明
①condition 过滤的条件
②DataFrame 返回值
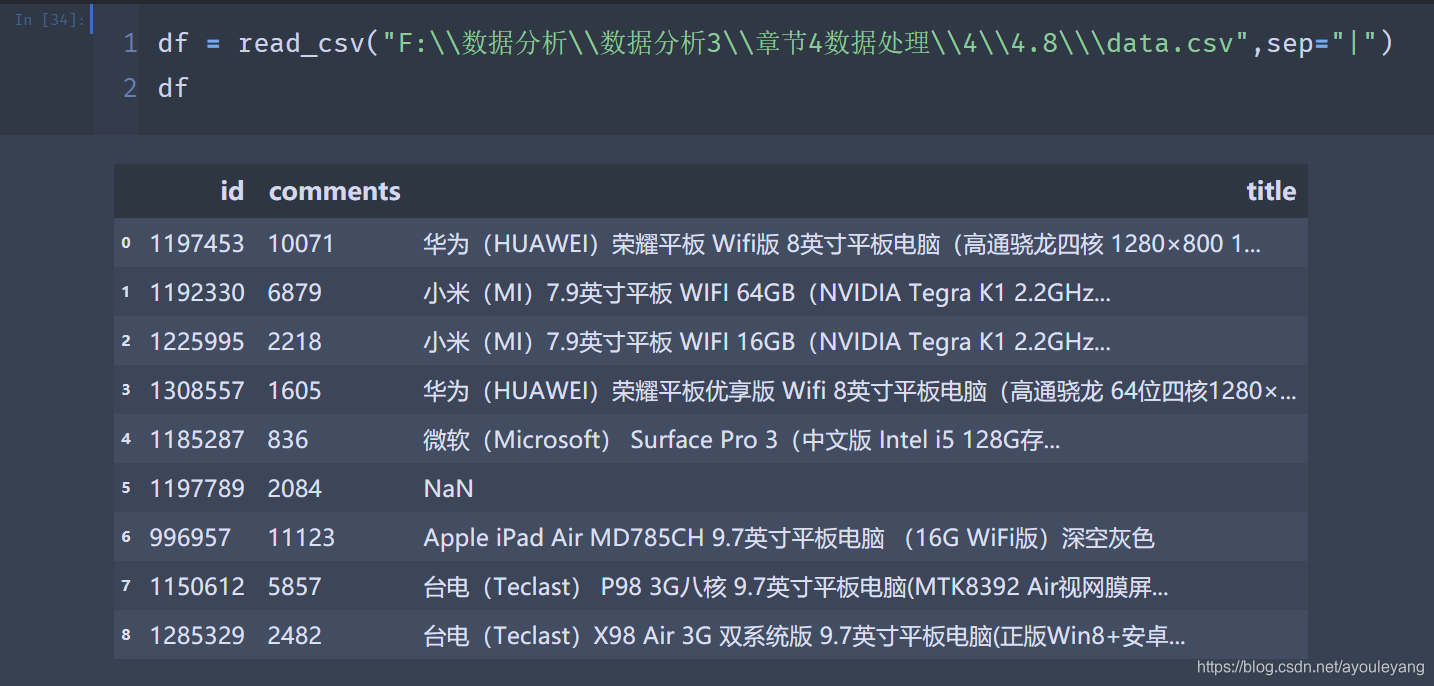
源数据:

读取数据并分割:
5.1、常见的条件类型
5.1.1、比较运算
大于(>),小于(<),大于等于(>=),小于等于(<=),不等于(!=)
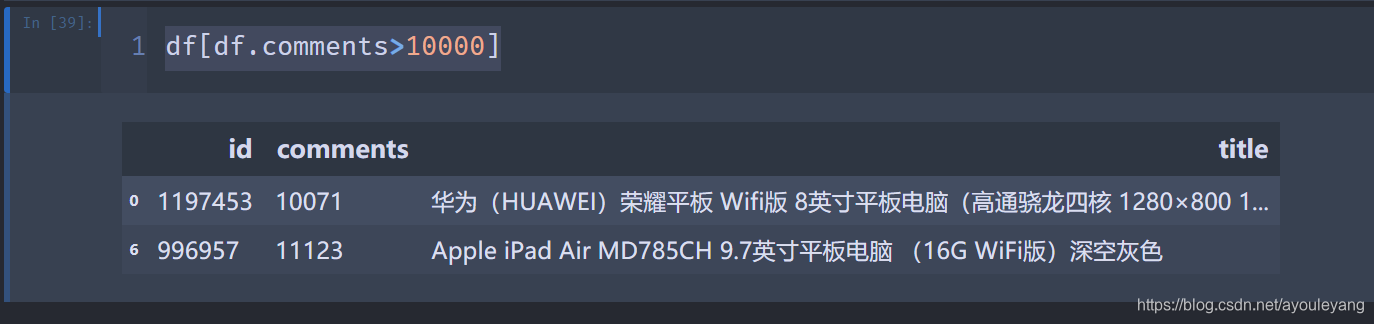
例如:抽取comments大于10000,就只有华为和Apple满足:
df[df.comments>10000]
5.1.2、范围运算
- between(left, right)
- 注意:它是(>=,<=),具有包含关系
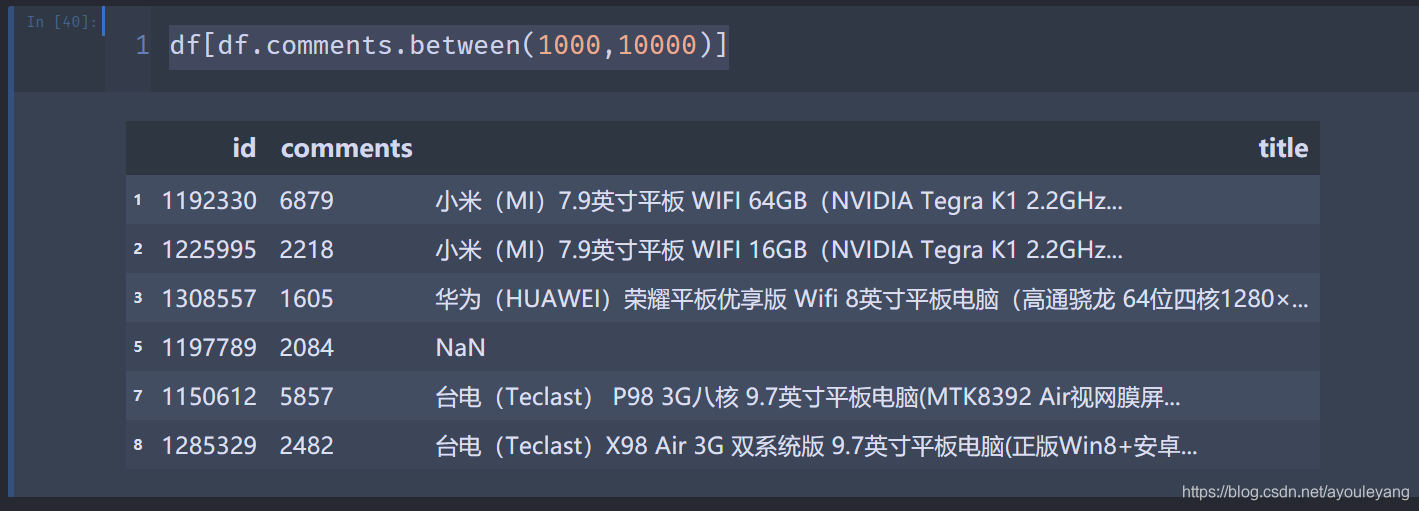
列如抽取"1000<=comments<=10000"
df[df.comments.between(1000,10000)]
5.1.3、控制匹配
- pandas.isnull(column)
pandas.isnull(df.title)
#运行结果
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 False
8 False
Name: title, dtype: bool
5.1.4、字符匹配
- 通过某个关键字,把某列中包含该关键词的列都搜索出来
- 语法:
str.contains(patten,na=False) - na是空值的处理,一般是空值我们是不需要匹配的
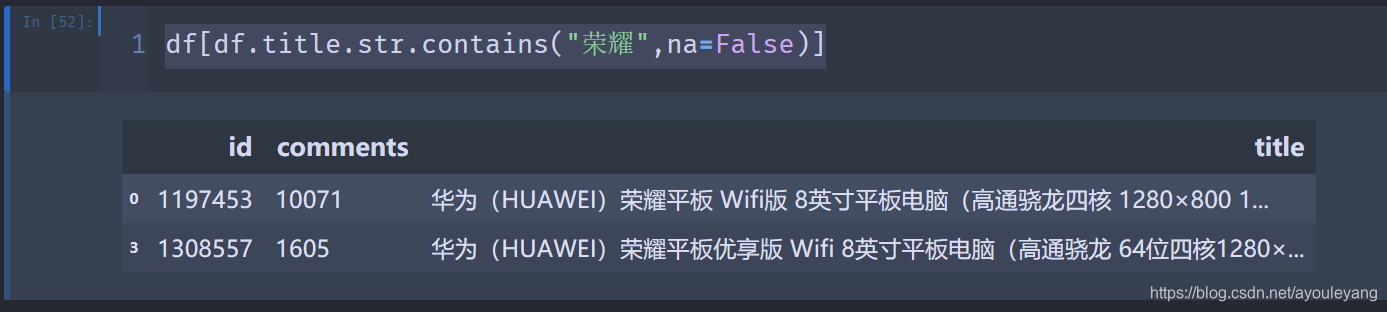
例如把title中带有“荣耀”的数据全部匹配出来
df[df.title.str.contains("荣耀",na=False)]
5.1.5、逻辑运算
- 与(&),或(|),取反(not)
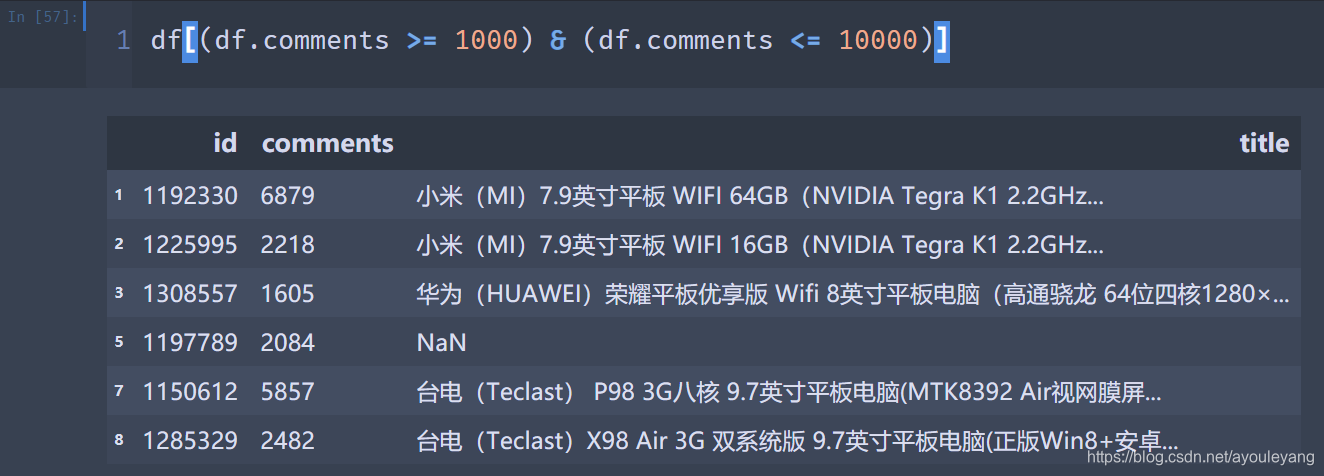
- 例如:
df[(df.comments >= 1000) & (df.comments <= 10000)] - 与上面的范围运算( df[df.comments.between(1000, 10000)] )等价
6、随机抽样
■随机抽样,是指随机从数据中按照一定的行数或者比例抽取数据
■随机抽样函数:numpy.random.randint(start, end, num)#[start,end)
6.1、导入源数据

6.2、数据抽样
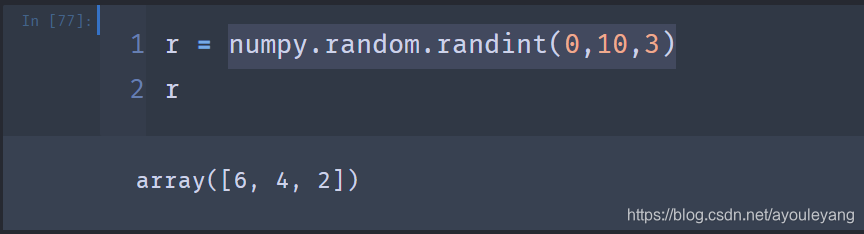
6.2.1、构造随机数
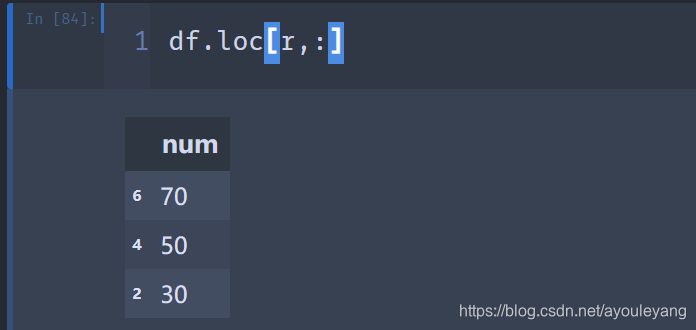
numpy.random.randint(0,10,3)
6.2.1、利用随机数提取数据
df.loc[r,:]
7、记录合并
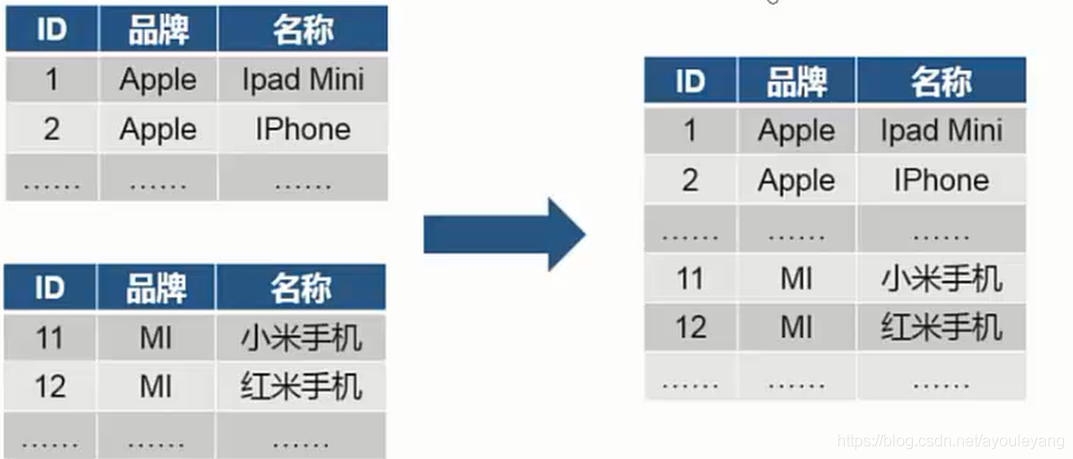
■记录合并,是指将两个结构相同的数据框,合并成一个数据框
■记录合并函数:concat([dataFrame1,dataFrame2,…])
■上下合并的方式,如:
- 参数说明
①DataFrame1 数据框
②DataFrame2 数据框
③… 任意多个数据框 - 返回值
①DataFrame
7.1、导入数据
import pandas
from pandas import read_csv
df1 = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.10\\data1.csv",sep="|")
df2 = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.10\\data2.csv",sep="|")
df3 = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.10\\data3.csv",sep="|")
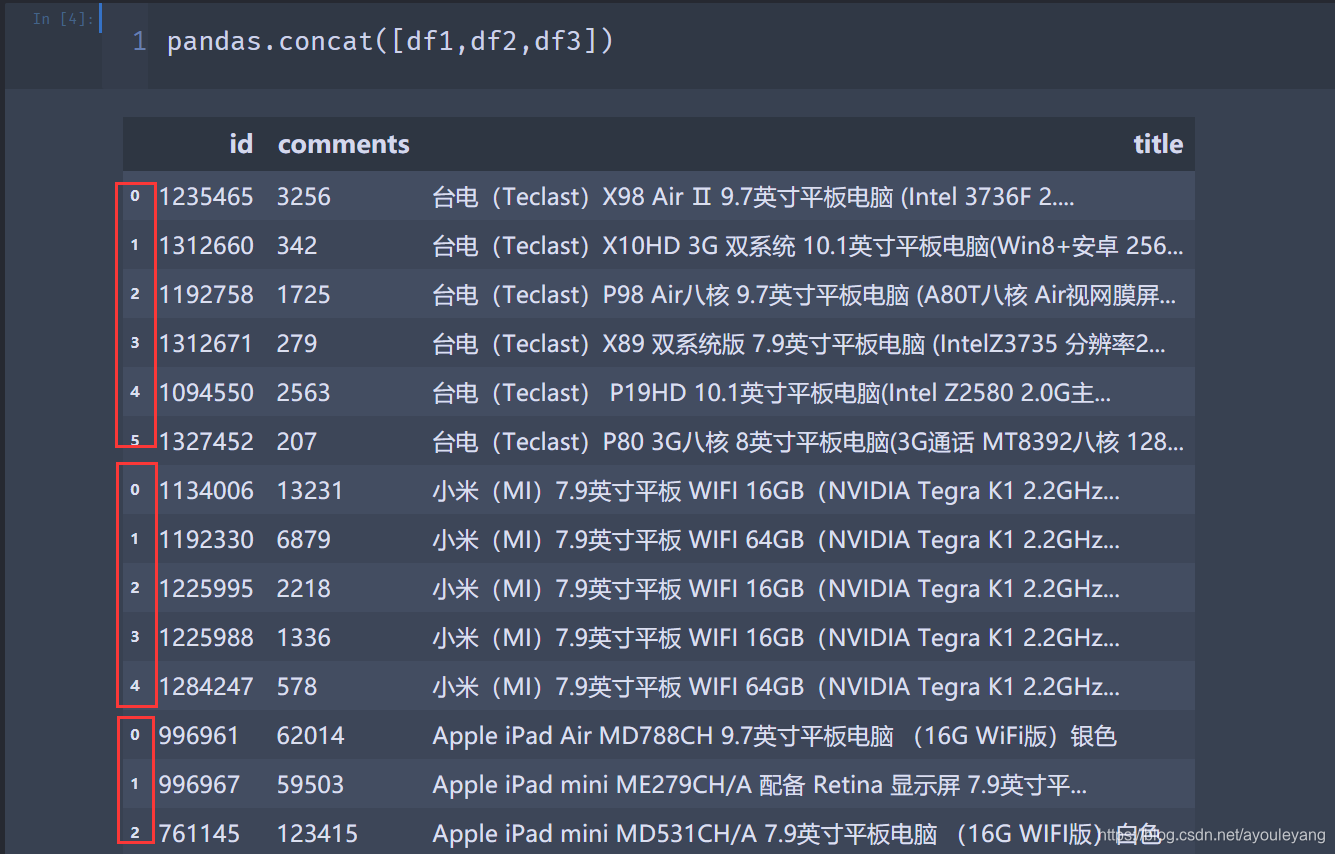
7.2、合并数据
pandas.concat([df1,df2,df3])
合并结果:
8、字段合并
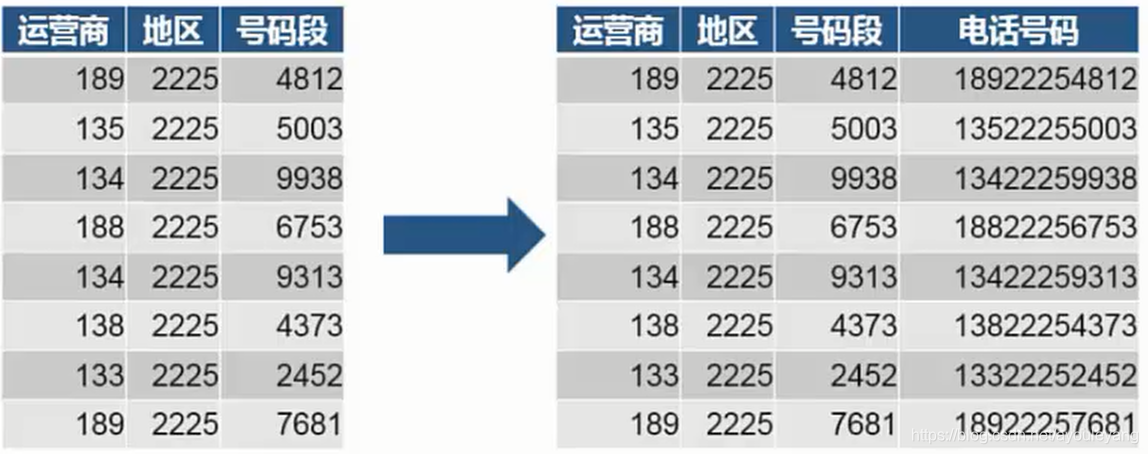
■字段合并,是指将同-个数据框中的不同列,进行合并,形成新的列
■左右合并的方式,如:
■要求:同一表格,字符型数据,长度一样
■字符合并方法: x = x1+x2+x3+… ,返回值位Serise
8.1、导入数据
from pandas import read_csv
df = read_csv(
"F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.11\\data.csv",
sep=" ",
names=['band','area','num'])
print (df)
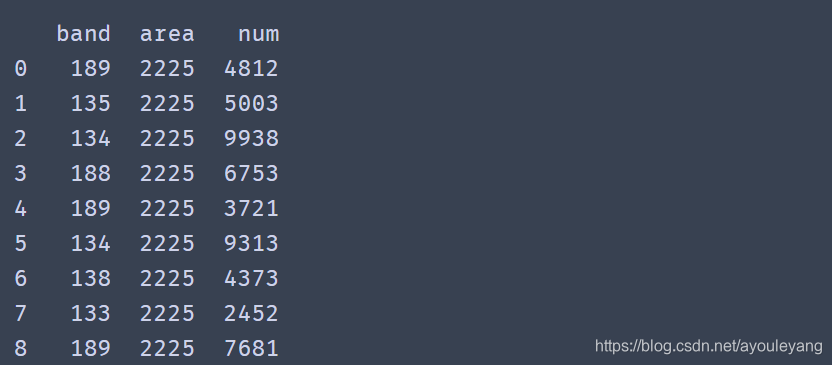
8.2、数值转换为字符型
df = df.astype(str)
注意: 如果不转为字符型,它会直接求和
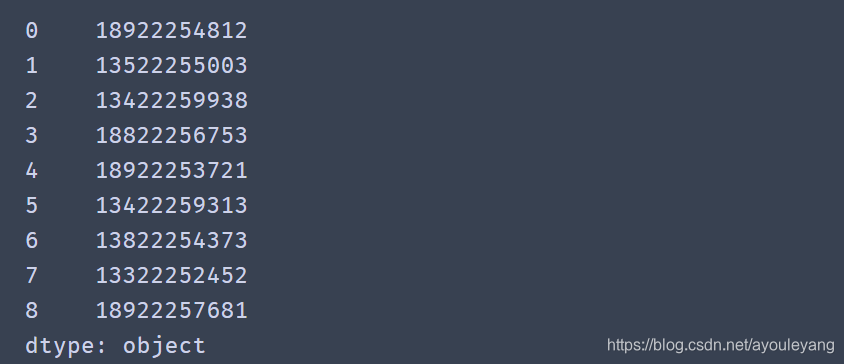
8.3、合并数据
tel = df['band']+df['area']+df['num']
print (tel)
合并结果:
9、字段匹配
■字段匹配,是指不同结构的数据框,按照一定的条件进行合并,相对于Excel中的vlookup函数,如:
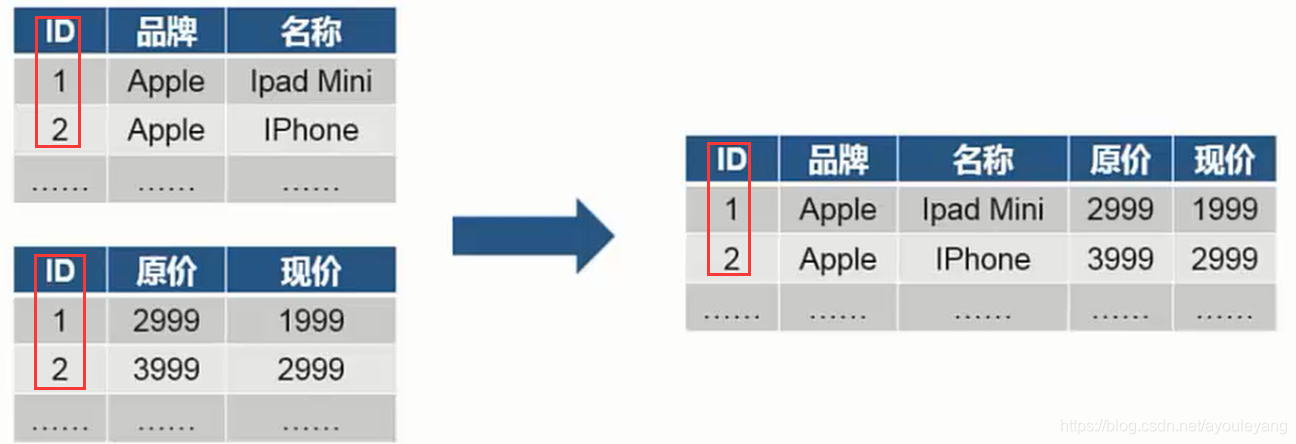
- 字段匹配函数: merge(x,y,left_on,rihtf_on),返回值为DataFrame
| 参数 | 注释 |
|---|---|
| x | 第一个数据框 |
| y | 第二个数据框 |
| left_on | 第一个数据框用于匹配的列 |
| right_on | 第二个数据框用于匹配的列 |
9.1、导入数据
from pandas import read_csv
items = read_csv(
"F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.12\\data1.csv",
sep="|",
names=['id','comments','title'])
prices = read_csv(
"F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.12\\data2.csv",
sep="|",
names=['id','oldPrice','nowPrice'])
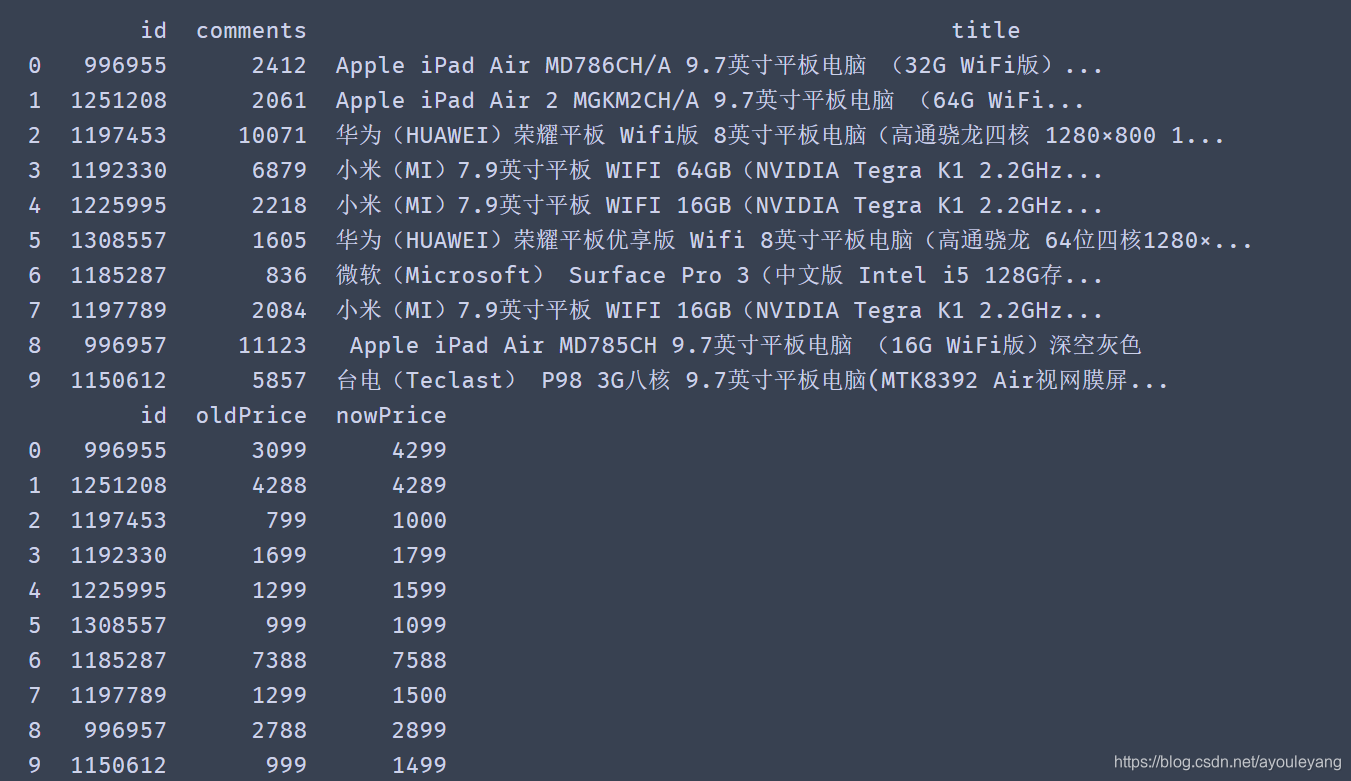
print (items)
print (prices)
9.2、字段匹配
itemPrices = pandas.merge(
items,
prices,
left_on='id',
right_on='id'
)
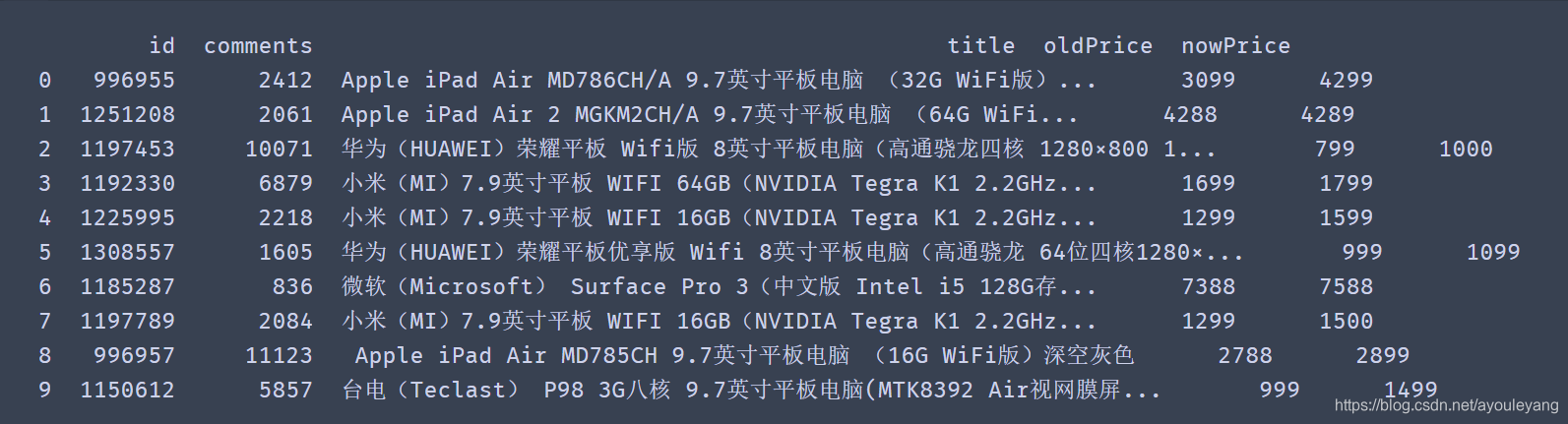
print(itemPrices)
匹配结果:
10、简单计算
■简单计算,通过对字段进行加、减、乘、除等四则算术运算,计算出来需要的字段,如:

10.1、导入数据
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.13\\data.csv",sep="|")
print (df)

10.2、乘法运算
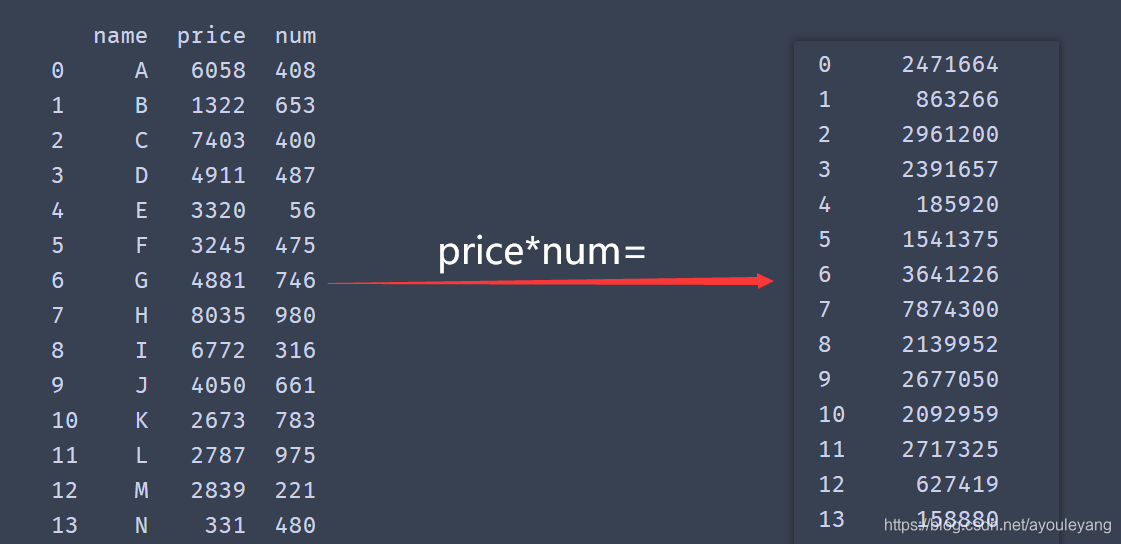
result = df.price*df.num #方法一
result = df['price']*df['num'] #方法二
print (result)
计算结果:
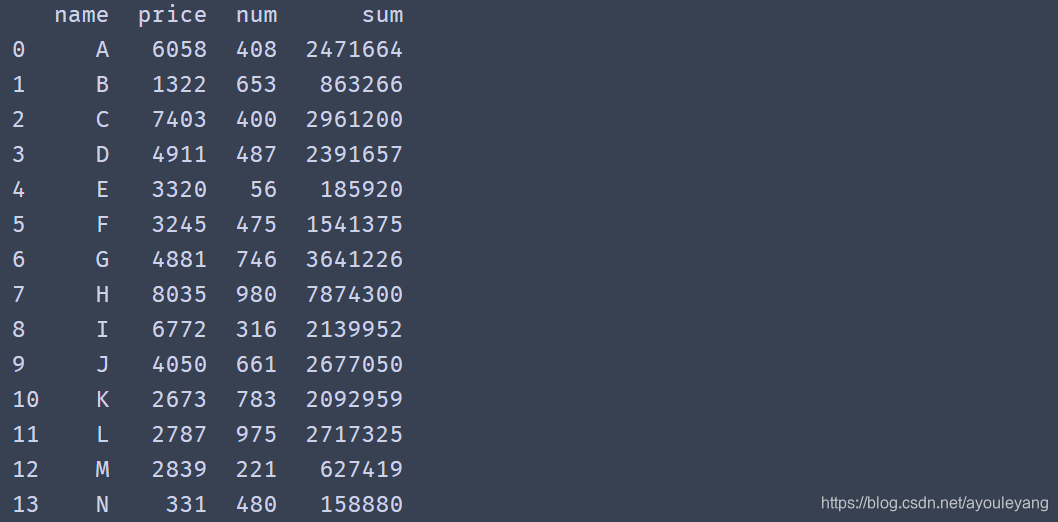
10.3、把结果并为一列
df['sum'] = result
print (df)
11、数据标准化
■数据标准化,是指将数据按比例缩放,使之落入到特定区间,一般我们使用0-1标准化;方便做10分制或百分制的转化,乘以相应的数即可。
■公式:
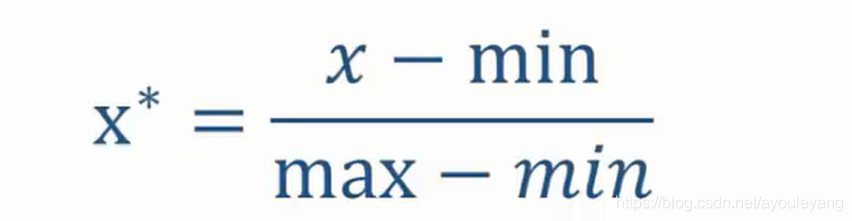
11.1、导入数据
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.14\\data.csv")
print (df)
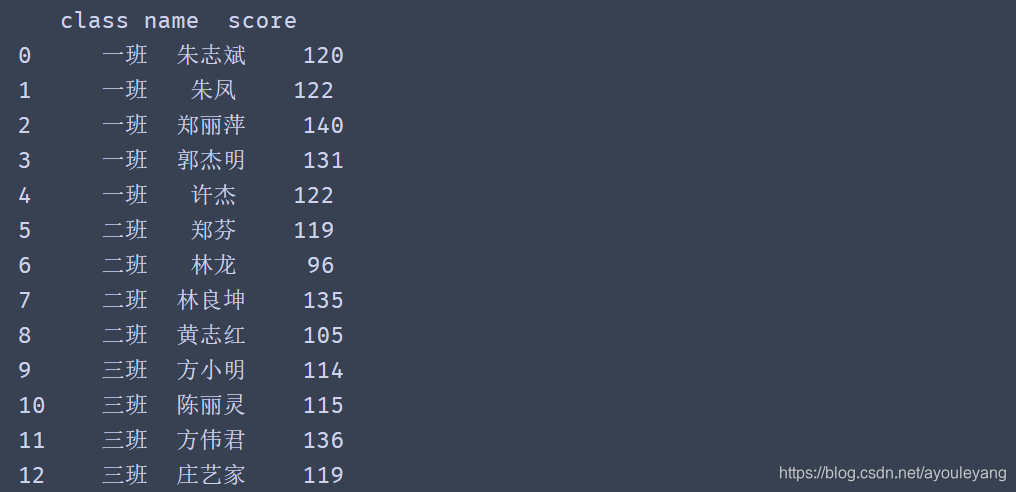
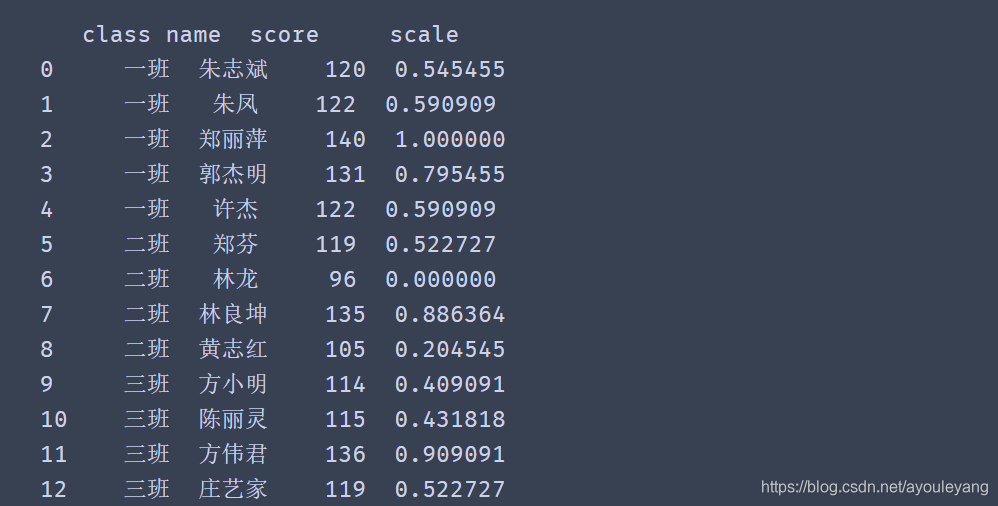
11.2、数据标准化
scale = (df.score - df.score.min()) / (df.score.max() - df.score.min())
df['scale'] = scale
print (df)
12、数据分组
■数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来进行研究,以揭示其内在的联系和规律性,如:

- cut函数: cut(series,bins,right=True,labgels=NULL)
- 参数说明
| 参数 | 注释 |
|---|---|
| series | 需要分组的数据 |
| bins | 分组的划分数组 |
| right | 分组的时候,右边是否闭合 |
| labels | 分组的自定义标签,可以不自定义 |
12.1、导入数据
import pandas
from pandas import read_csv
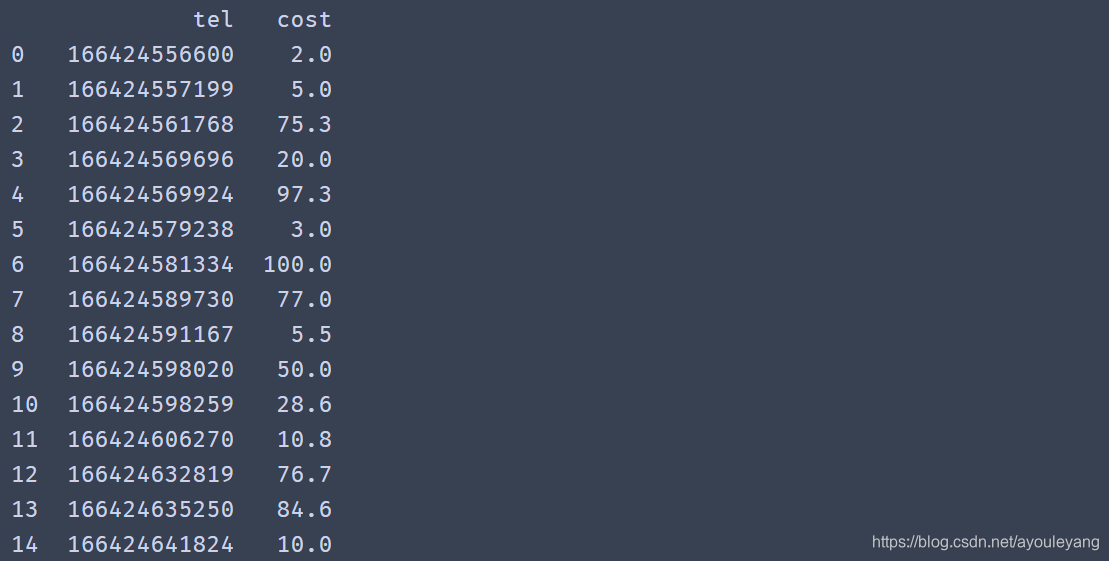
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.15\\data.csv",sep="|")
print (df)
12.2、自定义数组
bins = [min(df.cost)-1,20,40,60,80,100,max(df.cost)+1]
labels = ['20以下','20到40','40到60','60到80','80到100','100以上']
print (bins)
print (labels)

12.3、数据分组
- 存在区间,默认右边为闭区间
pandas.cut(df.cost,bins)
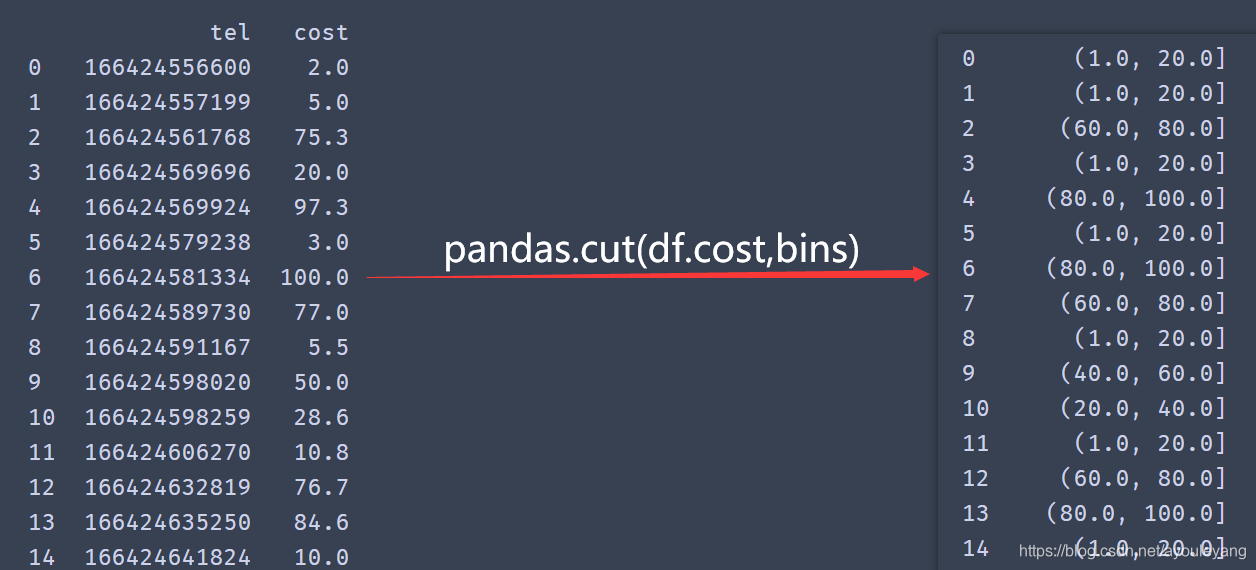
- 存在区间,让左边为闭区间
pandas.cut(df.cost,bins,right=False)

- 区间以自定义方式现实
pandas.cut(df.cost,bins,right=False,labels=labels)

13、日期转换
■日期转换,是指将字符型的日期格式的数据,转换成为日期型数据的过程;
■日期转换函数:data = to_datatime(dateString,format)
| 属性 | 注释 |
|---|---|
| %Y | 代表年份 |
| %m | 代表月份 |
| %d | 代表日期 |
| %H | 代表小时 |
| %M | 代表分钟 |
| %S | 代表秒数 |
13.1、导入数据
from pandas import to_datetime
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.16\\data.csv")
print (df)
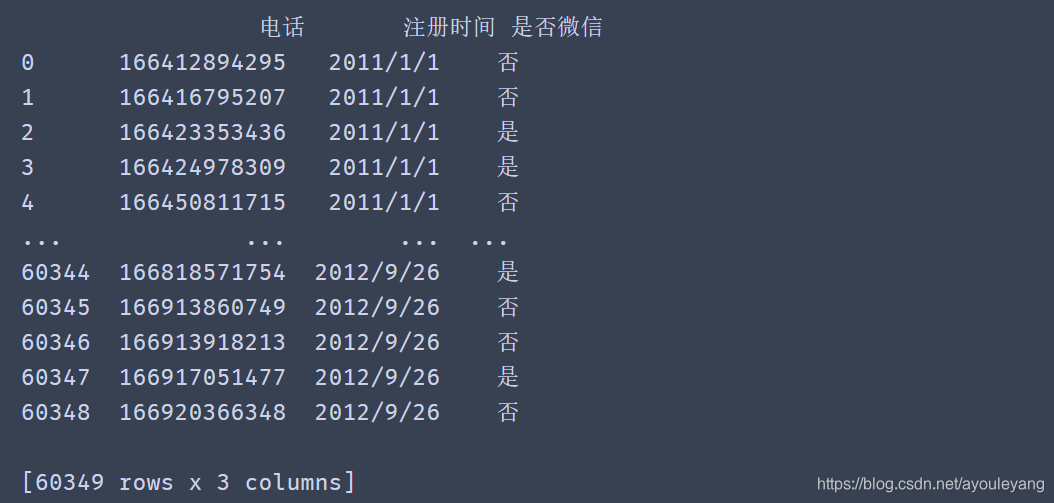
13.2、日期格式转换
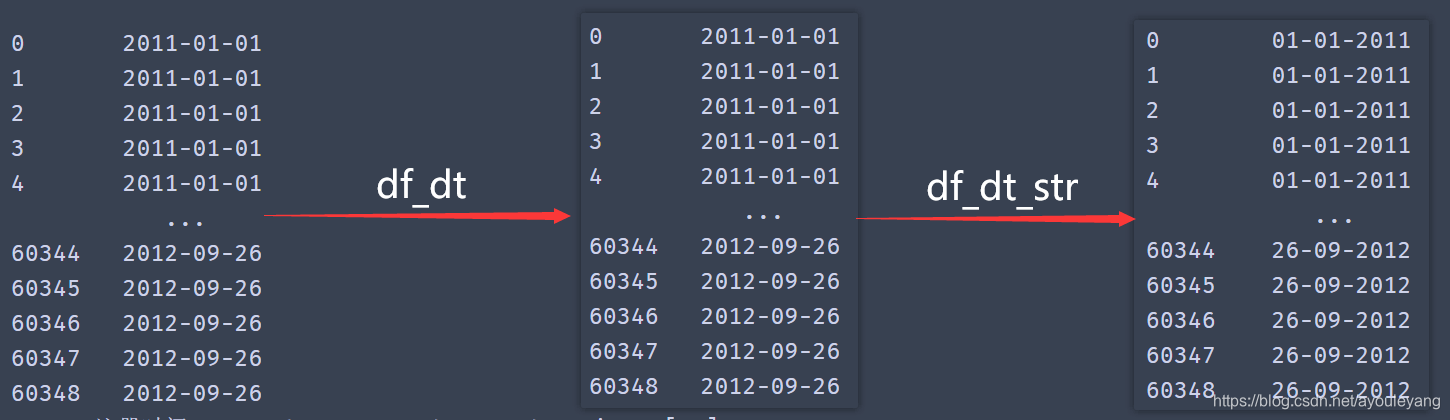
df_dt = to_datetime(df.注册时间,format='%Y/%m/%d')
print (df_dt)

13.3、日期格式化
■日期格式化:是指将日期型的数据,按照给定的格式,转为字符型的数据
■日期格式化函数:﹡apply(lambda x:处理逻辑)
﹡datetime,strftime(x,format)
from datetime import datetime
df_dt_str = df_dt.apply(lambda x:datetime.strftime(x,'%d-%m-%Y'))
print (df_dt_str)
14、日期抽取
■日期抽取,是指从日期格式里面,抽取出需要的部分属性
■抽取语法:datetime列.dt.property
| 属性 | 注释 |
|---|---|
| second | 1-60:秒,从1开始,到60 |
| minute | 1-60:分钟,从1开始,到60 |
| hour | 1-24:小时,从1开始,到60 |
| day | 1-31:一个月中的第几天,从1开始,最大31 |
| month | 1-12:月份,从1开始,到12 |
| year | 年份 |
| weekday | 1-7:一周中的第几天,从1开始,最大为7 |
from pandas import to_datetime
from pandas import read_csv
df = read_csv("F:\\数据分析\\数据分析3\\章节4数据处理\\4\\4.16\\data.csv")
df_dt = to_datetime(df.注册时间,format='%Y/%m/%d')#只有时间
df_dt.dt.year
df_dt.dt.second
df_dt.dt.minute
df_dt.dt.hour
df_dt.dt.day
df_dt.dt.month
df_dt.dt.weekday

