计算公式


- 缺陷:受样本个数限制,若某个属性值在训练集中没有与某个同类同时出现过,如P清脆|是=P (敲声=清脆|好瓜=是)=0/8=0,则连乘公式
h (好瓜=是)则必为零,其他属性取任意值都不能改变这一结论。 - 修正方法:拉普拉斯平滑处理

算法处理过程

原始的朴素贝叶斯只能处理离散数据,连续数据使用高斯朴素贝叶斯(Gaussian Naive Bayes)完成分类任务。
当处理***连续数据***时,一种经典的假设是:与每个类相关的连续变量的分布是基于高斯分布的,故高斯贝叶斯的公式如下:
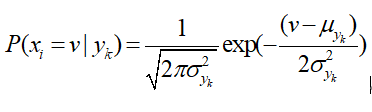

优点:
-
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
-
对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
-
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
- 在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好
- 在某些时候会由于假设的先验模型的原因导致预测效果不佳。
- 通过先验和数据来决定后验的概率从而决定分类,导致分类决策存在一定的错误率。
- 对输入数据的表达形式很敏感。
Python实现
高斯朴素贝叶斯
• 构造方法:sklearn.naive_bayes.GaussianNB
• GaussianNB 类构造方法无参数,属性值有:
- class_prior_ #每一个类的概率
theta_ #每个类中各个特征的平均
sigma_ #每个类中各个特征的方差
注:GaussianNB 类无score 方法
多项式朴素贝叶斯——用于文本分类
构造方法:
sklearn.naive_bayes.MultinomialNB()
- 属性:
alpha=1.0 #平滑参数
fit_prior=True #学习类的先验概率
class_prior=None) #类的先验概率
利用朴素贝叶斯算法实现对鸢尾花分类模型的构建及模型性能的基本评估
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
data_tr, data_te, label_tr, label_te = train_test_split(iris.data, iris.target, test_size=0.2)
clf = GaussianNB()
clf.fit(data_tr, label_tr)
pre = clf.predict(data_te)
print(pre)
acc = sum(pre == label_te)/len(pre) #模型在测试集样本上的预测精度
print(acc)
