三连后观看,养成好习惯!
点个关注吧,球球啦!
前言
Apache Flink 一个高性能的分布式数据处理引擎,它用于对无界和有界数据流进行有状态计算,它被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
相信过多的我不需要做什么介绍,本系列将以flink整体架构,资源管理与作业调度,错误恢复三个层面详细的讲述Flink Runtime运行时架构核心机制。
正文
一个身材苗条,婀娜多姿,上身穿着白衬衫,下身包臀裙的小姐姐,拿着一个精致的笔记本,径直的走过来说“请跟我来”,我和她到了个小房间,窗外的阳光照映着她粉嫩的脸颊,这时,我决定了,我们的孩子以后叫。。。( 啊!喂!!你号不要了?!)
不过心中还是暗暗自喜的,不仅是因为看到了美女的舒畅,而且看她这么年轻感觉应该问的不会太难。但是后来我才发现噩梦,才刚刚开始o(╥﹏╥)o
美女面试官:帅哥,我们开始今天的面试吧!
嗯?!她竟然叫我帅哥啊!!!我是不是有戏?我想到了和她一起夕阳下奔跑的画面。
在我正在细算我的颜值能给这次面试加多少分的时候,她问道:
了解过Flink整体架构吗?能不能给我简单讲讲?
卧槽,上来就这么刺激?还好我有准备!!
来,我先给你看个大宝贝(我确定,我没有GHS!)
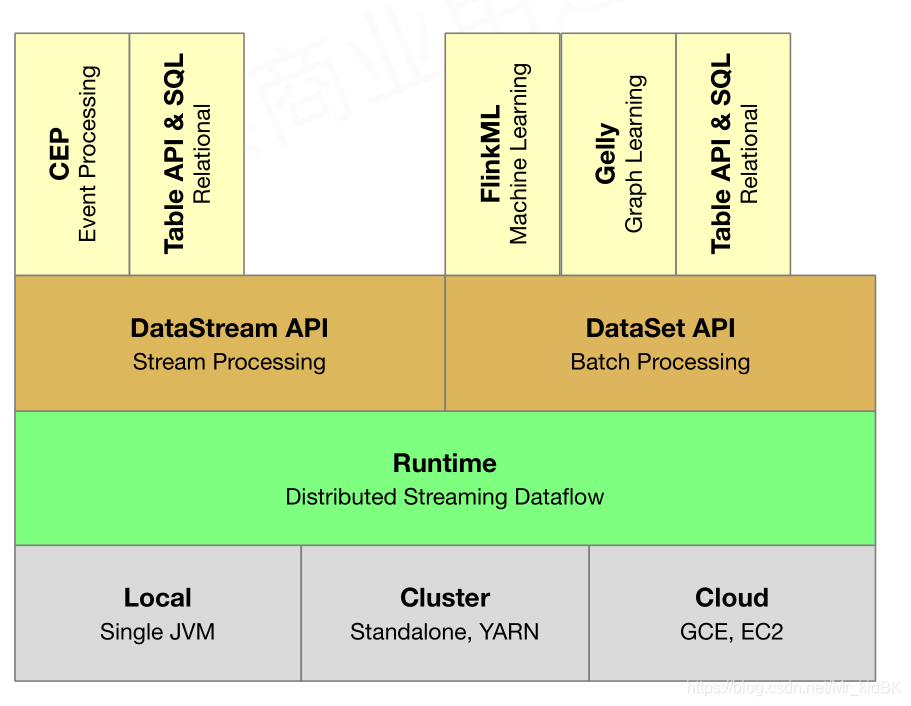
Flink整体架构主要分为4个层面,物理资源层,Runtime统一执行引擎,API层,High-level API层。
它可以跑在我们平时做调试用的单线程的Local环境里面,也可以跑在像Yarn,standalone(flink自带)等资源管理系统上面实现分布式资源管理,还可以跑在EC2这种云计算的环境里面。
针对不同的环境,Runtime层实现了统一的作业执行引擎。
基于Runtime层,Flink提供了两种不同的API,一个是用于操作流的DataStream API,一个是用于操作批数据的DataSet Api。
在这两种API之上,Flink提供了一组高级的API,像Table API&SQL,CEP, 方便用户做更简单的操作。
美女面试官:小帅哥,不错嘛!那Runtime层总体架构又是怎样的呢,具体细节你有了解过吗?
上来就这么深入??

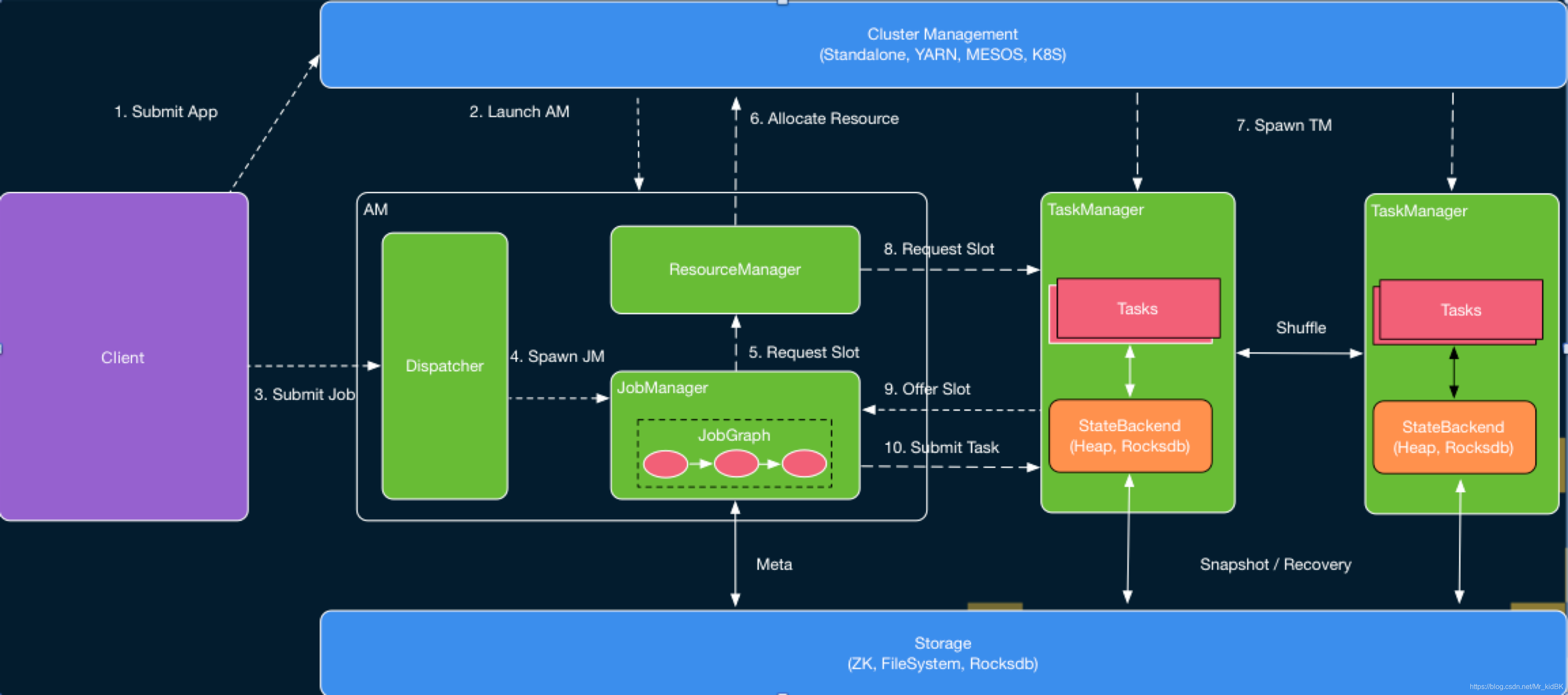
Flink运行时组件主要有Dispatcher,ResourceManager,JobManager,TaskManager。
* 分发器(Dispatcher)
分发器的主要作用是为client的应用提交提供rest接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。由于是REST接口,所以Dispatcher可以作为集群的一个HTTP接入点,这样就能够不受防火墙阻挡。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。它运行在ApplicationMaster进程中。
* 作业管理器(JobManager)
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager所控制执行。JobManager会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。JobManager会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。它运行在ApplicationMaster进程中。
* 资源管理器(ResourceManager)
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。它运行在ApplicationMaster进程中。
* 任务管理器(TaskManager)
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
我们就以yarn下的分布式模式为例吧。
 yarn提交有两种运行模式,一种是pre-job,还有一种是session,session模式比较简单,它是在作业提交之前就已经在yarn集群上启动了AM和TM,并且共用资源,我们这里就以说pro-job模式为例。
yarn提交有两种运行模式,一种是pre-job,还有一种是session,session模式比较简单,它是在作业提交之前就已经在yarn集群上启动了AM和TM,并且共用资源,我们这里就以说pro-job模式为例。
Flink采用了经典的master-slave架构,前面运行着Dsipachter、Resourcemanager、JobManager的ApplicationMaster相当于Master,后面的Taskmanager相当于slave。
首先,当我们客户端提交一个作业的时候,Client会先将用户用DataSteam、DateSet、Table API编写的作业转换成一个可以提交JobGraph(作业图),在这中间他会看哪些task可以分成一块,然后把它们栓(chain)在一起,还会去检查各个task的输入输出类型是否匹配,还有对一些job作一些额外的优化,比如说Batch Job。
Client会向yarn等资源管理器申请一个container容器,然后让yarn在容器中AM进程拉起来,启动完成后,作业会提交给Dispatcher,Dispatcher这时就会启动一个新的JM线程。
JM得到作业图后他会根据JobGraph先分析这个作业需要的资源,生成执行图(ExecutionGraph),然后他会找RM来获取所需要的资源,RM此时会向yarn去索要资源(container)和前面的启动AM一样,这时TM就会被启起来。
之后,RM会向找到TM告诉他:“你的slot被征用了!”,TM就会哭着向JM回复:“这些slot暂时归你了”并且把对应的slot标记为“正在使用”,这时候JM就可以把task Submit上去。
TM在收到task后,会为这个task启动一个新的线程,当全部的task都启起来之后多个task就可以使用flink的shuffle模块来交换数据,整个作业就可以跑起来了。
面试官听到这里惊呆了,通透而明亮的双眸向我投向钦佩的目光。当时我都觉得稳了,可没想到后来。。。
说了这么多我都口渴了,要么。。我们歇会再战?
下一章:房东太太
(不对,写错了。。。警察蜀黍听我解释。。。)
下一章:资源管理与作业调度
点关注,不迷路!
你知道的越多,你的头就会越秃
点个赞再走,球球啦!
原创不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
本博客仅发布于CSDN—一个帅到不能再帅的人 Mr_kidBK。转载请标明出处。
https://blog.csdn.net/Mr_kidBK
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
点赞!收藏!转发!!!么么哒!
————————————————

