#RnadomForest(sklearn学习)
在sklearn中是这样形容随机森林的:==通过在分类器构造中引入随机性来创建多样化的分类器集。各个分类器的平均预测作为输出的预测结果。==这是在说随机森林会在大样本中多几次随机抽取相同数量的数据作为训练数据,每一次抽取的数据生成一个分类器,并生成预测的结果。当所有的分类器都给出预测后,进行类似投票的形式合并结果(比如100个分类器有90个给出了预测为1,,10个预测为0,那么预测的结果即为1,也可以说是通过概率的大小得出结果)
随机森林的随机性的目的是减少森林估计量的方差。实际上,单个决策树往往会表现出较高的方差并且倾向于过度拟合。随机森林对大样本的随机多次的抽取的训练数据基本上包含了大样本的所有数据(多次抽取默认100次),这样就可以减少异常值造成的影响。最终的预测为每个分类器中预测的众数,这样减小了预测的误差(因为同样使异常值造成的影响减小了),使预测更加的准确。
随机森林的主要参数:
n_estimators:森林中决策树的个数,默认100
criterion:分类的标准 默认Gini(基尼),其公式为:
可选entropy(熵),其公式为:
max_depth:最大深度
max_features:划分时考虑的特征数,默认是全选的
n_jobs:运行的进程数
class_weight:给字典,给每个类权重
。。。。。还有很多参数,请参考官方文档
随机森林是基于决策树而产生的,接下来必须了解一下决策树的意义。
决策树(Decesion Tree)是一种基本的分类与回归方法。即即可用于分类,也可用于回归。
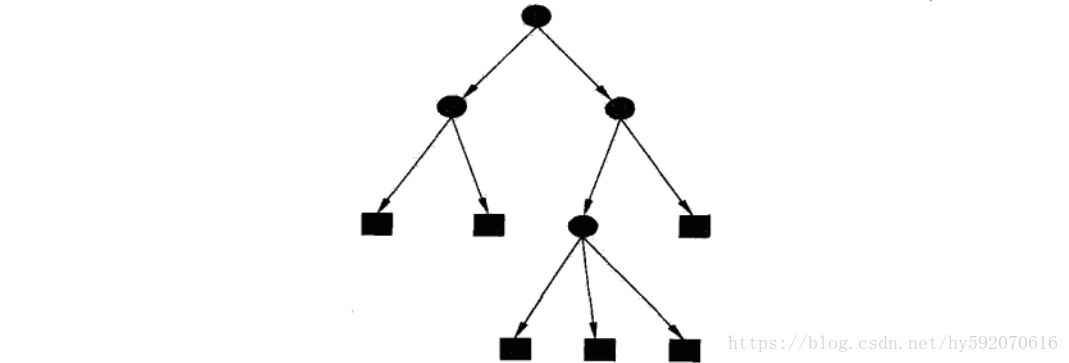
决策树有结点和有向边组成。结点有俩种类型:内部结点和叶子结点,其中内部结点表示一个特征或属性(分类的特征),叶子结点表示一个类(即决策的结果)。
在下图中,圆和方框分别表示内部结点和叶结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
决策树分类的标准:entropy熵
决策树ID3算法的工作原理:
1.确定分类的标准
决策树通过对各个特征分类后对应的信息增益来确定以哪个特征对样本进行分类。(这样可以更快的减小样本的熵)
信息增益是:样本分类前的熵 - 按某个特征分类后的熵,信息增益越大,意味着样本的不确定性下降的越大,特征分类能力越强,就要优先选取这个特征进行分类。
熵:是对数据不确定性的度量,值越大越无序
公式如下p(xi)表示概率
ID3算法的局限性
1.不支持连续的特征
2.不支持缺失值的处理
3.容易过拟合
4.采用信息增益大的特征作为优先决策点存在问题:因为在相同的条件下,取值比较多的特征比取值比较少的特征信息增益大
C4.5算法的改进:
C4.5采用信息增益率来作为划分标准:即在信息增益的基础上除以对应特征的个数。在决策树构造的同时进行剪枝操作;避免了树的过度拟合情况;可以对不完整属性和连续型数据进行处理;使用k交叉验证降低了计算复杂度;针对数据构成形式,提升了算法的普适性。
现在使用的CRAT算法:
CRAT算法采用Gini基尼系数来代替信息增益比,因为基尼系数免去了对数运算,计算起来更加的简单快速。基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低。
公式为:
