随机森林(RandomForest)
一、知识铺垫
1.1 决策树
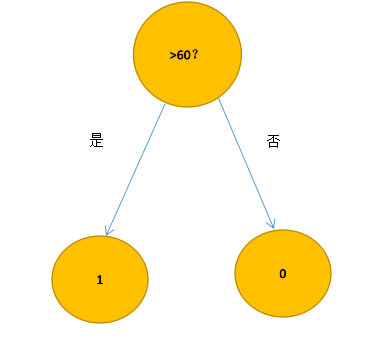
决策树是机器学习最基本的模型,在不考虑其他复杂情况下,我们可以用一句话来描述决策树:如果得分大于等于60分,那么你及格了。(if-then语句)
这是一个最最简单的决策树的模型,我们把及格和没及格分别附上标签,及格(1),没及格(0),那么得到的决策树是这样的
但是我们几乎不会让计算机做这么简单的工作,我们把情况变得复杂一点
引用别的文章的一个例子
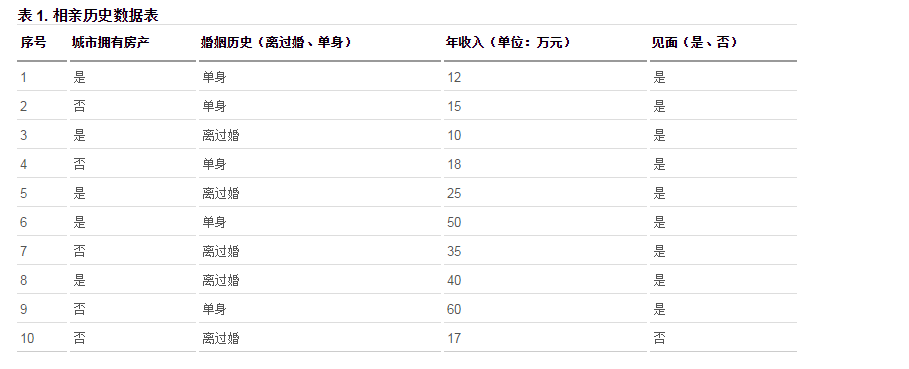
这是一张女孩对于不同条件的男性是否会选择见面的统计表,图中是否见面作为我们需要分类的结果,因此最后我们的结果无非就只是是和否两种情况。这是一个二分类的问题,但是需要判断的条件多了很多,现在不仅仅只是一个判断就能得出结果了,但是从上图我们找到了一个结果为否的记录,因此如果一个男性在城市无房产、年收入小于 17w 且离过婚,则可以预测女孩不会跟他见面。
那么问题就来了,在这种复杂的情况下,决策树怎么构建?
先通过城市是否拥有房产这条特征,把这10个人划分为2类
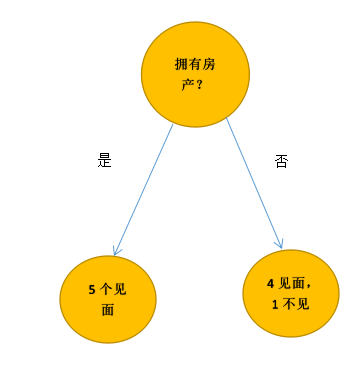
这个分类结果并不是很好,因为它没有将见面与不见面完全的分开,在算法中,当然不能凭我们的“感觉”去评价分类结果的好坏。我们需要用一个数去表示。
1.2 Gini不纯度
1、信息熵
这里介绍信息论中的信息量和信息熵的知识。
信息量:信息量是对信息的度量,就跟温度的度量是摄氏度一样,信息的大小跟随机事件的概率有关。
例如: 在哈尔滨的冬天,一条消息说:哈尔滨明天温度30摄氏度,这个事件肯定会引起轰动,因为它发生的概率很小(信息量大)。日过是夏天,“明天温度30摄氏度”可能没有人觉得是一个新闻,因为夏天温度30摄氏度太正常了,概率太大了(信息点太小了)
从这个例子中可以看出 一个随机事件的信息量的大小与其发生概率是成反相关的。
香农定义的一个事件的信息信息量为:I(X) = log2(1/p) 其中p为事件X发生的概率
信息熵:Entropy 一个随机变量 X 可以代表n个随机事件,对应的随机变为X=xi,那么熵的定义就是 X的加权信息量。
H(x) = p(x1)I(x1)+...+p(xn)I(x1)
= p(x1)log2(1/p(x1)) +.....+p(xn)log2(1/p(xn))
= -p(x1)log2(p(x1)) - ........-p(xn)log2(p(xn))
其中p(xi)代表xi发生的概率
例如有32个足球队比赛,每一个队的实力相当,那么每一个对胜出的概率都是1/32
那么 要猜对哪个足球队胜出 非常困难,这个时候的熵H(x) = 32 * (1/32)log(1/(1/32)) = 5熵也可以作为一个系统的混乱程度的标准。
试想如果32个队中有一个是ac米兰,另外31个对是北邮计算机1班队,2班,...31班那么几乎只有一个可能 ac米兰胜利的概率是100%,其他的都是0%,这个系统的熵
就是 1*log(1/1) = 0. 这个系统其实是有序的,熵很小,而前面熵为5 系统处于无序状态。
2、基尼不纯度
基尼不纯度的大概意思是 一个随机事件变成它的对立事件的概率
例如 一个随机事件X ,P(X=0) = 0.5 ,P(X=1)=0.5
那么基尼不纯度就为 P(X=0)*(1 - P(X=0)) + P(X=1)*(1 - P(X=1)) = 0.5
一个随机事件Y ,P(Y=0) = 0.1 ,P(Y=1)=0.9
那么基尼不纯度就为P(Y=0)*(1 - P(Y=0)) + P(Y=1)*(1 - P(Y=1)) = 0.18
很明显 X比Y更混乱,因为两个都为0.5 很难判断哪个发生。而Y就确定得多,Y=0发生的概率很大。而基尼不纯度也就越小。
所以基尼不纯度也可以作为 衡量系统混乱程度的标准
Gini不纯度是对分类结果好坏的度量标准
他的值是:1-每个标签占总数的比例的平方和。即1–∑mi=1fi2
对于上述的结果来讲,总的集合D被分为两个集合D1,D2,假设见面为1,不见面为0。
那么D1的不纯度为1-f1^2-f0^2,总数为5,见面的占了全部,则f1=1,f0=0,结果为0
D2的不纯度为1-f1^2-f0^2,f1=0.8,f0=0.2,结果为0.32
ok,那么整个分类结果的Gini不纯度就是D1/D与0的乘积 加上 D2/D与0.32的乘积,为0.16
Gini值代表了某一个分类结果的“纯度”,我们希望结果的纯度很高,这样就不需要对这一结果进行处理了。
从以上分析可以看出,Gini值越小,纯度越高,结果越好。
三、决策树的生成
在第一个例子中“如果得分大于等于60分,那么你及格了”中,生成决策树步骤是首先选择特征,“得分”,然后确定临界值,“>=60”
1.复杂的情况下也是一样,对于每一个特征,找到一个使得Gini值最小的分割点(这个分割点可以是>,<,>=这样的判断,也可以是=,!=),然后比较每个特征之间最小的Gini值,作为当前最优的特征的最优分割点(这实际上涉及到了两个步骤,选择最优特征以及选择最优分割点)。
2.在第一步完成后,会生成两个叶节点,我们对这两个叶节点做判断,计算它的Gini值是否足够小(若是,就将其作为叶子不再分类)
3.将上步得到的叶节点作为新的集合,进行步骤1的分类,延伸出两个新的叶子节点(当然此时该节点变成了父节点)
4.循环迭代至不再有Gini值不符合标准的叶节点
四、决策树的缺陷
我们用决策树把一个平面上的众多点分为两类,每一个点都有(x1,x2)两个特征,下面展示分类的过程
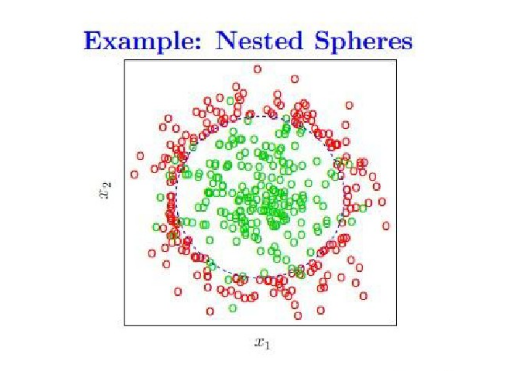
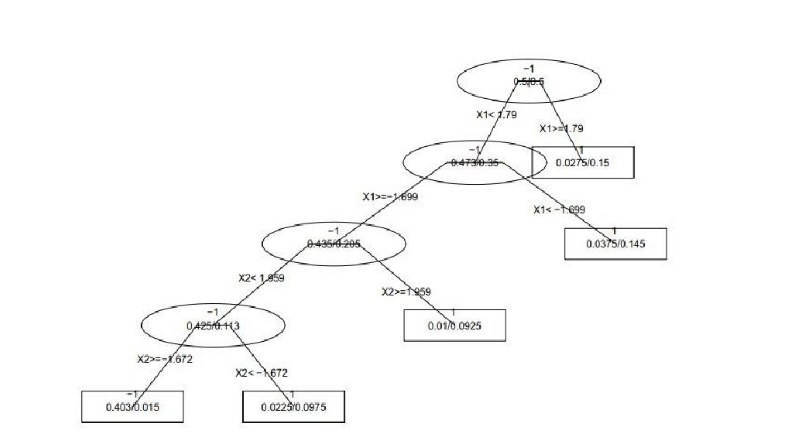
最后生成的决策树,取了四个分割点,在图上的显示如下,只要是落在中央矩形区域内默认是绿色,否则为红色
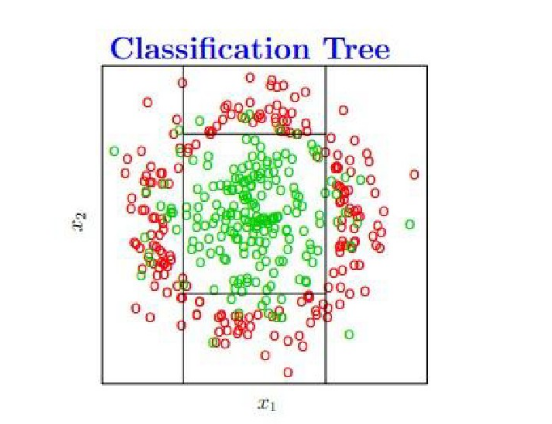
不过这种情况是分类参数选择比较合理的情况(它不介意某些绿色的点落在外围),但是当我们在训练的时候需要将所有的绿点无差错的分出来(即参数选择不是很合理的情况),决策树会产生过拟合的现象,导致泛化能力变弱。
五、随机森林
鉴于决策树容易过拟合的缺点,随机森林采用多个决策树的投票机制来改善决策树,我们假设随机森林使用了m棵决策树,那么就需要产生m个一定数量的样本集来训练每一棵树,如果用全样本去训练m棵决策树显然是不可取的,全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的
产生n个样本的方法采用Bootstraping法,这是一种有放回的抽样方法,产生n个样本
而最终结果采用Bagging的策略来获得,即多数投票机制
随机森林的生成方法:
1.从样本集中通过重采样的方式产生n个样本
2.假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
3.重复m次,产生m棵决策树
4.多数投票机制来进行预测
(需要注意的一点是,这里m是指循环的次数,n是指样本的数目,n个样本构成训练的样本集,而m次循环中又会产生m个这样的样本集)
六、随机森林实战
数据集:
我们的数据集是来自一个著名的数据挖掘竞赛网站,是一个关于泰坦尼克号,游客生存情况的调查。可以从这里下载:https://www.kaggle.com/c/titanic/data
1.读入数据
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
train = pd.read_csv("E:/train.csv", dtype={"Age": np.float64},)
train.head(10)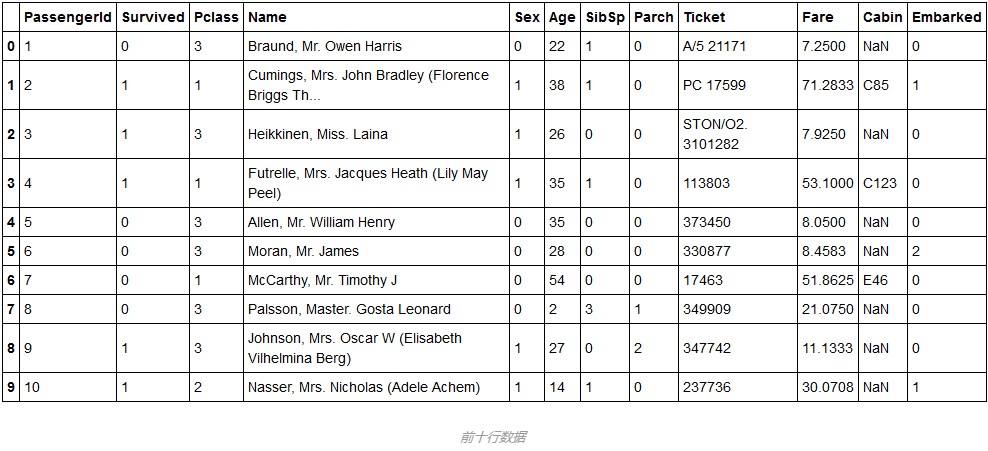
稍微分析一下,我们就可以筛选出对一个游客的生存与否有关的变量:Pclass, Sex, Age, SibSp,Parch,Fare, Embarked. 一般来说,游客的名字,买的船票号码对其的生存情况应该影响很小。
len(train_data)
out:891
我们共有891条数据,将近900条,我们使用600条作为训练数据,剩下的291条作为测试数据,通过对随机森林的参数不断调优,找出在测试结果上,预测最为精确的随机森林模型。
在具体的实验之前,我们看一下使用随机森林模型,需要注意哪几个变量:
在 sklearn中,随机森林的函数模型是:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
参数分析
A. max_features:
随机森林允许单个决策树使用特征的最大数量。 Python为最大特征数提供了多个可选项。 下面是其中的几个:
Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。
sqrt :此选项是每颗子树可以利用总特征数的平方根个。 例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
0.2:此选项允许每个随机森林的子树可以利用变量(特征)数的20%。如果想考察的特征x%的作用, 我们可以使用“0.X”的格式。
max_features如何影响性能和速度?
增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。
B. n_estimators:
在利用最大投票数或平均值来预测之前,你想要建立子树的数量。 较多的子树可以让模型有更好的性能,但同时让你的代码变慢。 你应该选择尽可能高的值,只要你的处理器能够承受的住,因为这使你的预测更好更稳定。
C. min_sample_leaf:
如果您以前编写过一个决策树,你能体会到最小样本叶片大小的重要性。 叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。
下面我们对上面提到的三个参数,进行调优,首先参数A,由于在我们的这个数据中,数据段总共只有七八个,所以我们就简单的选取所有的特征,所以我们只需要对剩下的两个变量进行调优。
在sklearn自带的随机森林算法中,输入的值必须是整数或者浮点数,所以我们需要对数据进行预处理,将字符串转化成整数或者浮点数:
def harmonize_data(titanic):
# 填充空数据 和 把string数据转成integer表示
# 对于年龄字段发生缺失,我们用所有年龄的均值替代
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
# 性别男: 用0替代
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
# 性别女: 用1替代
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
titanic["Embarked"] = titanic["Embarked"].fillna("S")
titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0
titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1
titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2
titanic["Fare"] = titanic["Fare"].fillna(titanic["Fare"].median())
return titanic
train_data = harmonize_data(train)上面的代码是对原始数据进行清洗,填补缺失数据, 把string类型数据转化成int数据
下面的工作,我们开始划分训练数据和测试数据,总的数据有891个,我们用600个训练数据集,剩下的291个作为测试数据集。
# 列出对生存结果有影响的字段
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# 存放不同参数取值,以及对应的精度,每一个元素都是一个三元组(a, b, c)
results = []
# 最小叶子结点的参数取值
sample_leaf_options = list(range(1, 500, 3))
# 决策树个数参数取值
n_estimators_options = list(range(1, 1000, 5))
groud_truth = train_data['Survived'][601:]
for leaf_size in sample_leaf_options:
for n_estimators_size in n_estimators_options:
alg = RandomForestClassifier(min_samples_leaf=leaf_size, n_estimators=n_estimators_size, random_state=50)
alg.fit(train_data[predictors][:600], train_data['Survived'][:600])
predict = alg.predict(train_data[predictors][601:])
# 用一个三元组,分别记录当前的 min_samples_leaf,n_estimators, 和在测试数据集上的精度
results.append((leaf_size, n_estimators_size, (groud_truth == predict).mean()))
# 真实结果和预测结果进行比较,计算准确率
print((groud_truth == predict).mean())
# 打印精度最大的那一个三元组
print(max(results, key=lambda x: x[2]))总的来说,调参对随机森林来说,不会发生很大的波动,相比神经网络来说,随机森林即使使用默认的参数,也可以达到良好的结果。在我们的例子中,通过粗略的调参,可以在测试集上达到84%的预测准确率.
附上全部代码:(运行时间比较久)
__author__ = 'Administrator'
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
train = pd.read_csv("E:/train.csv", dtype={"Age": np.float64},)
def harmonize_data(titanic):
# 填充空数据 和 把string数据转成integer表示
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
titanic["Embarked"] = titanic["Embarked"].fillna("S")
titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0
titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1
titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2
titanic["Fare"] = titanic["Fare"].fillna(titanic["Fare"].median())
return titanic
train_data = harmonize_data(train)
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
results = []
sample_leaf_options = list(range(1, 500, 3))
n_estimators_options = list(range(1, 1000, 5))
groud_truth = train_data['Survived'][601:]
for leaf_size in sample_leaf_options:
for n_estimators_size in n_estimators_options:
alg = RandomForestClassifier(min_samples_leaf=leaf_size, n_estimators=n_estimators_size, random_state=50)
alg.fit(train_data[predictors][:600], train_data['Survived'][:600])
predict = alg.predict(train_data[predictors][601:])
# 用一个三元组,分别记录当前的 min_samples_leaf,n_estimators, 和在测试数据集上的精度
results.append((leaf_size, n_estimators_size, (groud_truth == predict).mean()))
# 真实结果和预测结果进行比较,计算准确率
print((groud_truth == predict).mean())
# 打印精度最大的那一个三元组
print(max(results, key=lambda x: x[2]))七、随机森林模型的总结
随机森林是一个比较优秀的模型,在我的项目的使用效果上来看,它对于多维特征的数据集分类有很高的效率,还可以做特征重要性的选择。运行效率和准确率较高,实现起来也比较简单。但是在数据噪音比较大的情况下会过拟合,过拟合的缺点对于随机森林来说还是较为致命的。
参考链接
[1]https://blog.csdn.net/mao_xiao_feng/article/details/52728164