Python 内置的 difflib库为计算文本差异, 对比一致性的辅助工具
写个小样
# -*- coding: utf-8 -*-
from pprint import pprint
from difflib import Differ, SequenceMatcher, HtmlDiff
def diff_compare(in_lines1: list, in_lines2: list):
"""Diff结果中符号说明
'- ' 行为序列 1 所独有
'+ ' 行为序列 2 所独有
' ' 行在两序列中相同
'? ' 行不存在于任一输入序列
:param in_lines1:
:param in_lines2:
:return:
"""
d = Differ()
rst = list(d.compare(in_lines1, in_lines2))
pprint(rst)
def seque_match(in_lines1: list, in_lines2: list, max_ratio=1.0, flag=None):
"""
:param in_lines1:
:param in_lines2:
:param max_ratio:
:param flag:
:return:
"""
for index, item in enumerate(in_lines1):
s = SequenceMatcher(flag, item, in_lines2[index])
rst = s.ratio()
if rst > max_ratio:
print(item)
else:
print(rst)
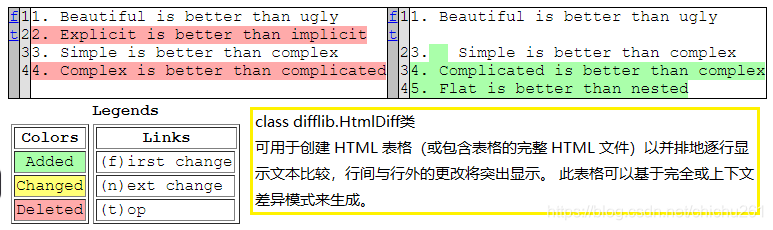
def html_comp(in_lines1: list, in_lines2: list, out_file: str):
"""
:param in_lines1:
:param in_lines2:
:param out_file:
:return:
"""
d = HtmlDiff()
result = d.make_file(in_lines1, in_lines2)
with open(out_file, 'w') as f:
f.writelines(result)
if __name__ == '__main__':
txt_lines1 = [
'1. Beautiful is better than ugly',
'2. Explicit is better than implicit',
'3. Simple is better than complex',
'4. Complex is better than complicated',
]
txt_lines2 = [
'1. Beautiful is better than ugly',
'3. Simple is better than complex',
'4. Complicated is better than complex',
'5. Flat is better than nested',
]
diff_compare(txt_lines1, txt_lines2)
print('*' * 50)
seque_match(txt_lines1, txt_lines2, max_ratio=0.7)
print('*' * 50)
html_comp(txt_lines1, txt_lines2, 'comp.html')
代码结果显示, 用***** 进行分割
[' 1. Beautiful is better than ugly',
'- 2. Explicit is better than implicit',
'- 3. Simple is better than complex',
'+ 3. Simple is better than complex',
'? ++\n',
'- 4. Complex is better than complicated',
'? ^ ---- ^\n',
'+ 4. Complicated is better than complex',
'? ++++ ^ ^\n',
'+ 5. Flat is better than nested']
**************************************************
1. Beautiful is better than ugly
0.6666666666666666
3. Simple is better than complex
0.6666666666666666
**************************************************
html结果页面截图
附:
difflib库
