最近我在尝试存储知识图谱的过程中,对Neo4j图数据库有了一个新的认知,这里我摘取了一段Neo4j的简介:
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
我开始着手把三元组数据存储进neo4j的数据库中,用的是python的py2neo库,我的思路是:读取文件,将每行的实体抽取出来,在图中查找是否有该(两个)实体节点,如果不存在就插入节点用的刚刚开始是cypher语句的create后来是merge,目的是在数据写入之前去重。然后插入该行三元组表示的边(用的create unique)。是在安装在自己电脑上的Neo4j 运行操作。
后来为了方便其他同事可以使用数据需要找到公司运维帮忙在服务器上开通运行neo4j,还是用的之前的方法和思路写数据。但是需要安装neo4j-driver这个库来运行。
但是这样做的效率很低,因为现有数据量是457万多的三元组集合至少连续半个多月才能存完。我分析了一下,原因在于:每次插入实体节点都需要先查询图中是否存在该实体节点,随着图的增大,查询所需的时延也越来越长。前面大部分时间做铺垫了。留给我的时间就只有从10月28号开始操作了。
在查了官方文档以后,我发现一个高效率的导入数据的方法–neo4j的import工具。后面在苏杭西子的帮助下完成如下的工作(下面有几个neo4j 写入数据方法对比图)
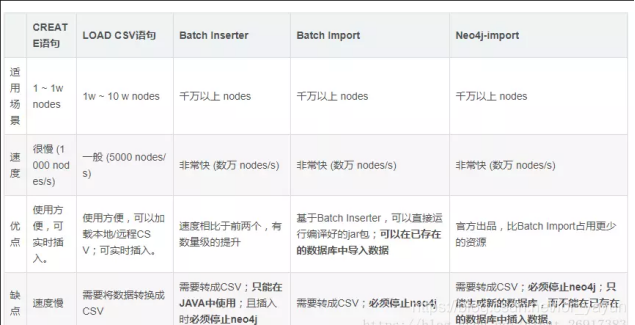
导入方法
import工具命令为如下格式:
neo4j-admin import [–mode=csv] [–database=]
[–additional-config=]
[–report-file=]
[–nodes[:Label1:Label2]=<“file1,file2,…”>]
[–relationships[:RELATIONSHIP_TYPE]=<“file1,file2,…”>]
[–id-type=<STRING|INTEGER|ACTUAL>]
[–input-encoding=]
[–ignore-extra-columns[=<true|false>]]
[–ignore-duplicate-nodes[=<true|false>]]
[–ignore-missing-nodes[=<true|false>]]
[–multiline-fields[=<true|false>]]
[–delimiter=]
[–array-delimiter=]
[–quote=]
[–max-memory=]
[–f=]
[–high-io=<true/false>]
或:
neo4j-admin import --mode=database [–database=]
[–additional-config=]
[–from=]
方括号内为可以选择的参数,其中我们常用的是第一种格式,即从独立的文件里导入图数据,常用参数为–nodes和–relationships,分别用来引入节点的CSV文件和边的CSV文件。
举个例子:
bin/neo4j-admin import --nodes --relationships
- 生成CSV文件
Neo4j的import工具要求数据使用CSV文件保存,因此在导入数据前需要将数据转乘CSV文件。节点和关系需要不同的文件,一种节点的CSV文件可以分为多个文件储存,传递参数的时候需要按顺序加上所有文件的文件名(绝对路径),工具读取第一个文件的表头作为节点/边的属性名,该文件剩下所有行以及后续文件的所有行作为属性值。多种节点(如包含不同属性集合)的导入需要分别为每一种节点分别引入(即使用多次–node参数)。
在我的需求中,节点和边都只包含一个名称(数据格式每行为\t\t .),因此我将节点和边分别仅用一个CSV文件储存,使用python的csv库,csv库写csv文件的方法为(以下代码不可执行):
import csv
csvf = open(filepath,‘w’,newline=’’,encoding=‘utf-8’)
w = csv.writer(csvf)
w.writerow((column_name_1, column_name_2, …))#写入表头
for i in some_range:
w.writerow((column_1, column_2, …))#写入行
csvf.close()
注意,writerow传入的参数为含有多个字符串的tuple,而不是多个字符串。
生成的CSV文件表头结构如下示例:
node.csv: name:ID(node), :LABEL
rel.csv: :START_ID(node), :END_ID(node), :TYPE,name
在这个其中:
name:ID 表示该列的属性名为name,ID
表示该属性是唯一标示一个实体的属性(类似关系型数据库中的主码),括号表示一个id-group,即表示该ID唯一表示括号内种类的实体,而不是所有实体;
:LABEL 表示节点的标签;
START_ID 和END_ID 表示边的起点和终点的ID,可以加上它们各自的id-group;
:TYPE 表示该边的种类,注意种类个数不应超过65535。
2.在使用import指令导入之前我协调运维帮我们开通一台虚拟机并且部署安装neo4j。打开查看neo4j 安装的目录如下图:
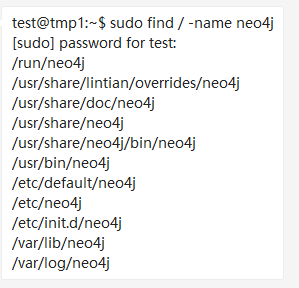
找到bin目录,import 和 data 文件夹所在的目录。
在CSV文件准备就绪以后,然后开始准备好在虚拟机上bin下面执行的代码:

3.运行neo4j-admin import指令,注意:
在此之前应当保证在Neo4j的目录下的data/databases/graph.db 下没有文件,即该指令要求数据库为空;
Neo4j应当关闭,处于stopped状态(关闭方法:终端在Neo4j的根目录执行./bin/neo4j stop),
–nodes 和–relationships 后的文件名应当是绝对路径。后面我们执行了很多次上图代码,都是报错,原因是引用值有问题。经过排查和修改。在10月30号下午4:23分 将所有数据全部一次性导入用时46秒。如下图:

总结&注意事项
1.传入文件名的时候务必使用绝对路径,否则将会抛出以下错误:
2.使用neo4j-admin import指令导入之前先将原数据库从neo4j_home/data/databases/graph.db/中移除,即指令要求目录下不含数据库,否则指令无法执行;
3.在执行指令之前务必保证Neo4j处于关闭状态,如果不确定可以在Neo4j根目录下运行./bin/neo4j status 查看当前状态。如果数据库未关闭,可能会导致数据库即使成功导入,也无法查询到
4.写CSV文件的时候务必确保所有的节点的CSV文件的ID fileds的值都唯一、不重复(类似SQL中的primary key),并且确保所有的边的CSV文件的START_ID 和 END_ID都包含在节点CSV文件中(参考SQL中的referential integrity constraint);
