一.爬取酷狗飙升榜,把歌手与他的歌曲和时长做成表格
思路:爬取和解析页面信息,制作excel表格
技术难点:解析源代码
二.1.url=https://www.kugou.com/yy/rank/home/1-6666.html?from=rank
2.找到源代码里面歌手,歌曲名,时长对应的标签,用find_all进行遍历
三1..代码:
from bs4 import BeautifulSoup import requests import time import xlwt #创建Excel存储数据 class Spider: def __init__(self): self.workbook, self.worksheet = self.create_excel() self.nums = 1 def create_excel(self): workbook = xlwt.Workbook(encoding='utf-8') worksheet = workbook.add_sheet('Sheet1') title = ['排名', '歌手和歌名', '播放时间'] for index, title_data in enumerate(title): worksheet.write(0, index, title_data) return workbook, worksheet def get_html(self,url): headers = {'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} # 爬虫请求头信息 response = requests.get(url) if response.status_code == 200: # 如果请求状态值为200,则输出 return response.text else: return '产生异常' def get_data(self,html): soup = BeautifulSoup(html, 'lxml') # 用BeautifulSuop库解析网页 ranks = soup.find_all('span',class_="pc_temp_num") # 排名 names = soup.find_all('a',class_="pc_temp_songname") # 歌手和歌名 times = soup.find_all('span',class_="pc_temp_time") # 播放时间 # 打印信息 for r, n, t in zip(ranks, names, times): # 用zip函数 r = r.get_text().replace('\n', '').replace('\t', '').replace('\r', '') n = n.get_text() t = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '') data = {'排名': r, '歌名-歌手': n, '播放时间': t} self.worksheet.write(self.nums, 0, str(r)) self.worksheet.write(self.nums, 1, str(n)) self.worksheet.write(self.nums, 2, str(t)) self.nums += 1 def main(self,): urls = ['https://www.kugou.com/yy/rank/home/1-6666.html?from=rank'.format(str(i)) for i in range(1, 24)] # 用for循环 for url in urls: print(url) html = self.get_html(url) self.get_data(html) time.sleep(1) # 暂停1S self.workbook.save('data.xls')#存入所有信息后保存为data.xls if __name__ == '__main__': # 程序执行时调用主程序main() spider = Spider() spider.main()
输出结果:
对应的excel表格:
2.对数据进行清洗和处理:(1)表格里面的行列均无无效行列,略过此步.
(2)重复值处理
import pandas as pd biaosheng=pd.DataFrame(pd.read_excel('data.xls')) biaosheng.duplicated()
结果:
因为存在重复值,所以采用drop_duplicates的方法删除重复值
import pandas as pd biaosheng=pd.DataFrame(pd.read_excel('data.xls')) biaosheng=biaosheng.drop_duplicates() biaosheng
结果: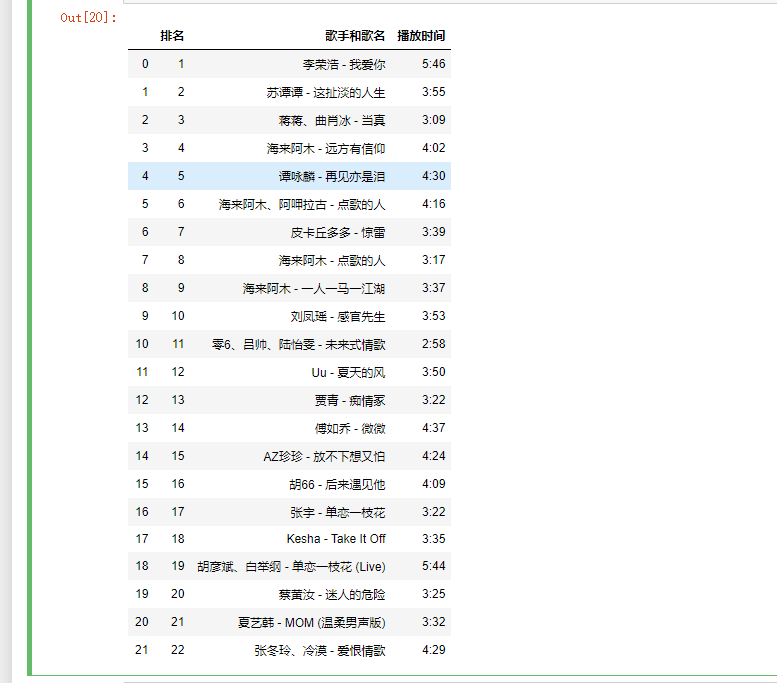
(3)无空值与缺失值,略过此步
(4)空值处理(格式一致,无空格影响数据,略过此步)
(5)异常值处理(歌曲时长相近,略过此步)
3.文本分析(不会)
4.数据分析及可视化:由于数据过多,这里取榜单前五名分析。分析前五名歌手所唱的歌的时长(以秒为单位显示)与排名的关系,以柱状图的方式体现
import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar([346,235,189,242,250],[1,2,3,4,5]) plt.legend() plt.show()
结果: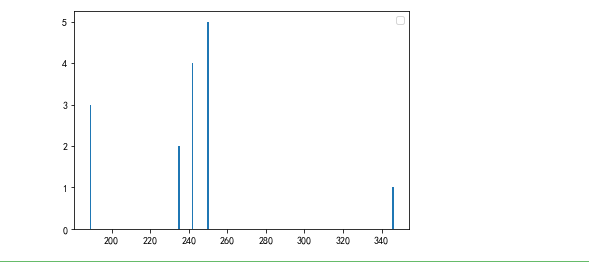
5.分析相关系数
import pandas as pd import scipy.stats as stats x=[346,235,189,242,250] y=[1,2,3,4,5] stats.pearsonr(x, y)
结果: 此处的第一个数为相关系数。
此处的第一个数为相关系数。
画图
import seaborn as sns biaosheng=pd.DataFrame(pd.read_excel('data.xls')) sns.regplot(biaosheng.播放时间,biaosheng.排名)
结果:
6.数据持久化(没学过)
四.1.歌曲时长和排名并无特别联系。
2.这次数据分析整合了python数据分析.python数据可视化.网络爬虫等多个部分,内容较多,因为不熟练,得不停翻书来完成这项任务,而且其中还有许多部分书本没有的,从百度上找了好久才找到如何去用代码实现一些功能。经过这次的练习,我明白了python的深奥,我会更加努力学习python,争取让自己变得更强。