一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:酷狗TOP_排行榜
2.爬取内容:酷狗TOP_排行榜的歌曲排名,歌曲名称和歌曲时间。
数据特征:数据包含面广,可以用分为多组数据进行分析比对。
3.实现思路:通过网站源代码找到要爬取的数据对象,将爬取到数据进行存储再进行绘图和分析。
技术难点:数据可视化,和建立回归方程。
二、主题页面的结构特征分析
1.将要爬取的网站页面如下:
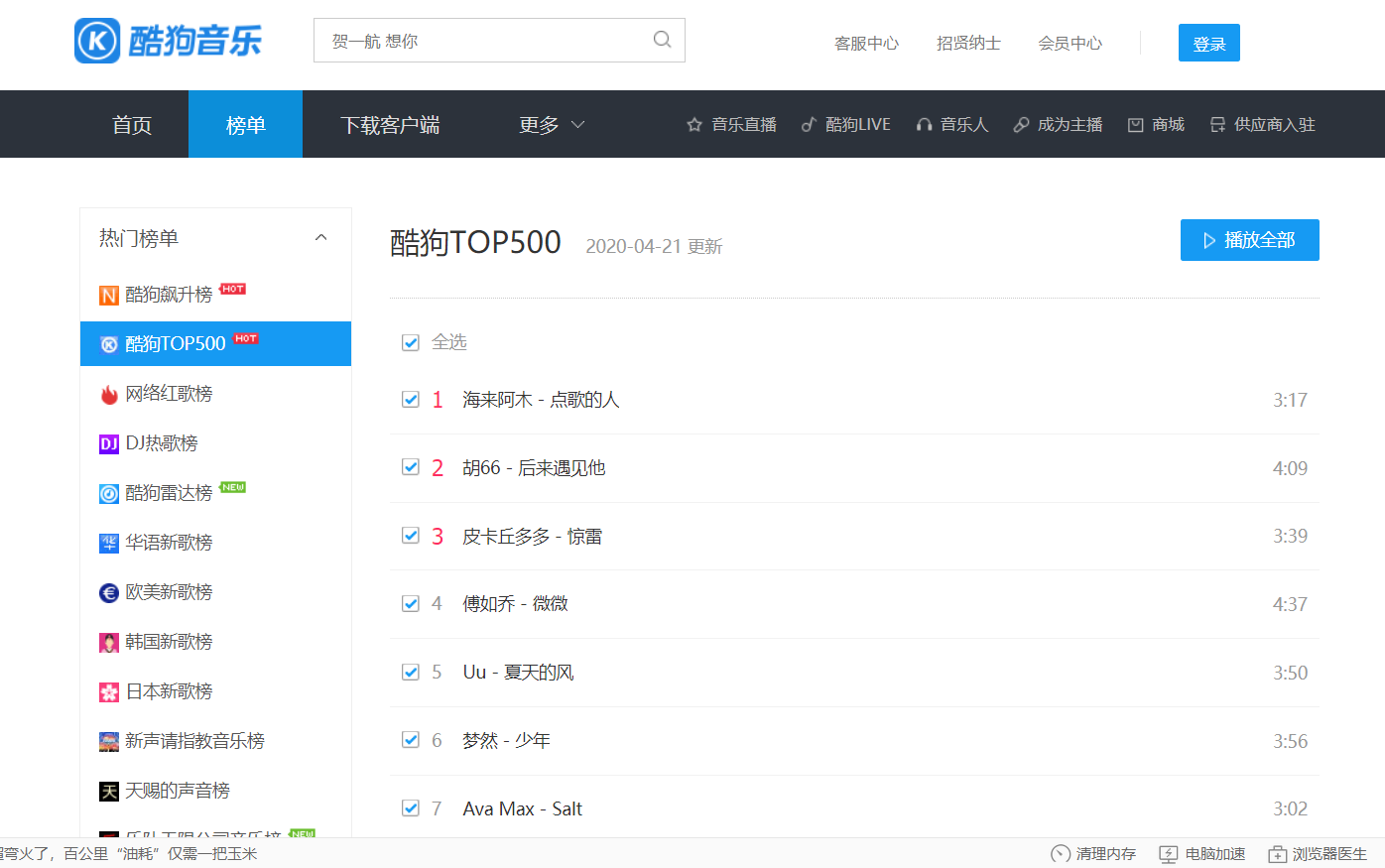
2.任意选择其中一首歌,然后“右键”——“审查元素”:
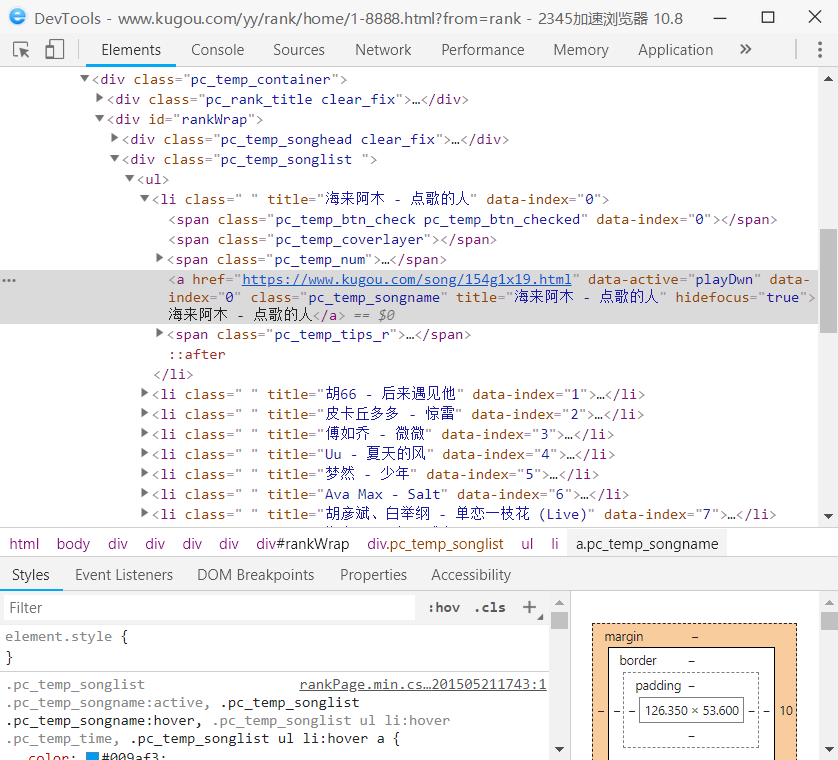
3.

三、网络爬虫程序设计
1.数据爬取与采集:
class Spider: def __init__(self): self.workbook, self.worksheet = self.create_excel() self.nums = 1 def create_excel(self): workbook = xlwt.Workbook(encoding='utf-8') worksheet = workbook.add_sheet('Sheet1') title = ['排名', '歌曲名称', '歌曲时间'] for index, title_data in enumerate(title): worksheet.write(0, index, title_data) return workbook, worksheet def get_html(self,url): #定义请求头,请求头可以使爬虫伪装成浏览器 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'} # 利用requests模块连接网络,它可以打开并读取从网络获取的对象 response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return '产生异常' def get_data(self,html): soup = BeautifulSoup(html, 'lxml') # 排名 ranks = soup.find_all('span', class_='pc_temp_num') # 歌名 name = soup.find_all('a', class_='pc_temp_songname') # 歌曲时间 time = soup.find_all('span', class_='pc_temp_time') #将名次,歌名,时间依次打印出来 for r, n, t in zip(ranks,name,time): r =r.get_text().replace('\n', '').replace('\t', '').replace('\r', '') n = n.get_text() t = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '') data = {'排名': r, '歌曲名称': n, '歌曲时间':t} self.worksheet.write(self.nums, 0, str(r)) self.worksheet.write(self.nums, 1, str(n)) self.worksheet.write(self.nums, 2, str(t)) self.nums += 1 def main(self,): urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1, 24)] for url in urls: print(url) html = self.get_html(url) self.get_data(html) # 暂停1S time.sleep(1) #保存文件,数据持久化 self.workbook.save('酷狗TOP_500排行榜.xls')
2.对数据进行清洗和处理:
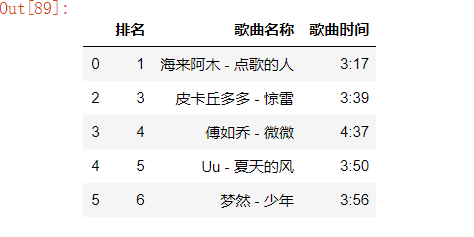
#读取数据并输出 df = pd.DataFrame(pd.read_excel('酷狗TOP_500排行榜.xls')) df.head()

#删除无效列与行
#删除无效列与行 df = pd.DataFrame(pd.read_excel('酷狗TOP_500排行榜.xls')) df.head() df.drop(1,axis=0,inplace=True) df.head()
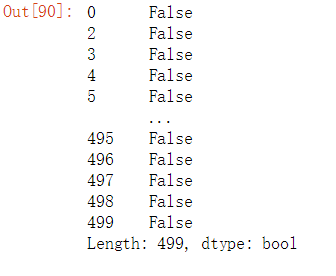
#检查是否有重复值
#检查是否有重复值 df.duplicated()
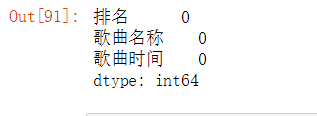
#空值处理
#空值处理 df.isnull().sum() #返回0,表示没有空值
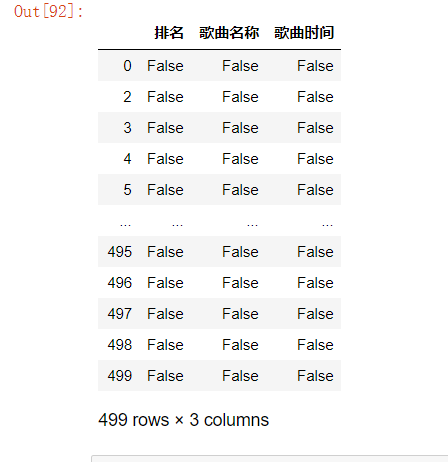
#缺失值处理
#缺失值处理 df.isnull()
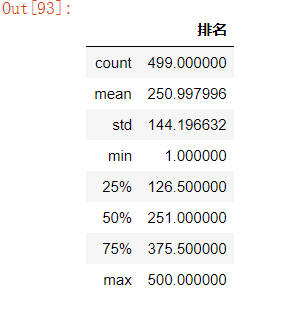
#用describe()命令显示描述性统计指标 df.describe()
3.数据分析和可视化:
让中文和负号能正常显示出来
#让中文和负号能正常显示出来
plt.rcParams['font.sans-serif']=['SimHei'] matplotlib.rcParams['axes.unicode_minus']=False
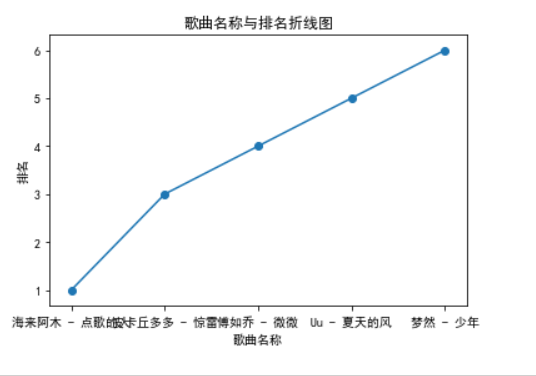
绘制折线图
#绘制折线图 def PlotData(): x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.xlabel('歌曲名称') plt.ylabel('排名') plt.plot(x,y) plt.scatter(x,y) plt.title("歌曲名称与排名折线图") plt.show() PlotData()
x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('酷狗TOP_500排行榜') plt.show()
绘制直方图
#绘制直方图 plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'],[1,3,4,5,6]) plt.legend() plt.xlabel("歌曲名称") plt.ylabel("排名") plt.title('酷狗TOP_500排行榜') plt.show()
4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元):
绘制散点图
#绘制散点图 x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.scatter(x,y,color='blue', s=25, marker="o") plt.xlabel("歌曲名称") plt.ylabel("排名") plt.title("歌曲名称与排名散点图") plt.show()

def func2(p,x): a,b = p return a*x+b #偏差函数 def error2(p,x,y): return func2(p,x)-y plt.scatter(df['排名'],df['排名']) X = df.排名 Y = df.排名 plt.figure(figsize=(8,6)) p0 = [0,15] para = leastsq(error2,p0,args=(X,Y)) a,b = para[0] print('a=',a,'b=',b) print("求解的拟合直线为:") print("y="+str(round(a,2))+"x+"+str(round(b,2))) plt.scatter(X,Y,color='green',label='样本数据',linewidth=2) x = np.linspace(0,25) y = a*x+b plt.plot(x,y,color='red',label='拟合曲线',linewidth=2) plt.legend() plt.title('') plt.grid() plt.show()
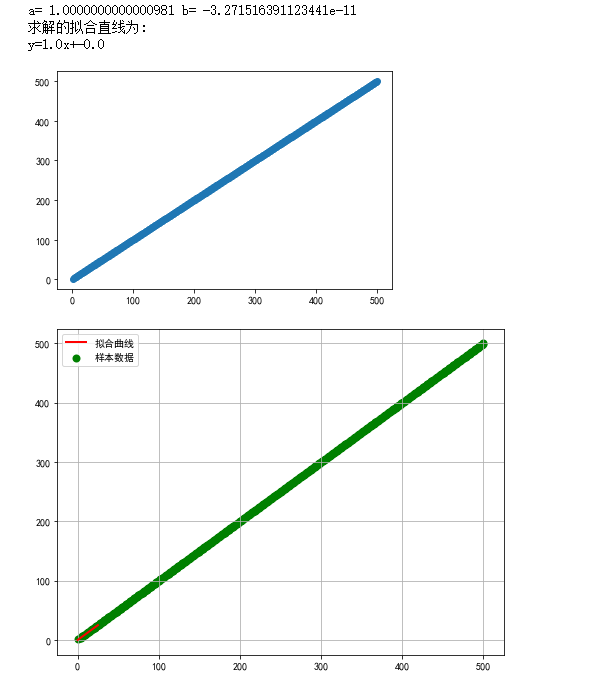
5.完整程序代码:
# 导入相关库 import requests import time import xlwt from bs4 import BeautifulSoup import pandas as pd import matplotlib.pyplot as plt import matplotlib import seaborn as sns import numpy as np from scipy.optimize import leastsq class Spider: def __init__(self): self.workbook, self.worksheet = self.create_excel() self.nums = 1 def create_excel(self): workbook = xlwt.Workbook(encoding='utf-8') worksheet = workbook.add_sheet('Sheet1') title = ['排名', '歌曲名称', '歌曲时间'] for index, title_data in enumerate(title): worksheet.write(0, index, title_data) return workbook, worksheet def get_html(self,url): #定义请求头,请求头可以使爬虫伪装成浏览器 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'} # 利用requests模块连接网络,它可以打开并读取从网络获取的对象 response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return '产生异常' # 数据爬取与清洗 def get_data(self,html): soup = BeautifulSoup(html, 'lxml') # 排名 ranks = soup.find_all('span', class_='pc_temp_num') # 歌名 name = soup.find_all('a', class_='pc_temp_songname') # 歌曲时间 time = soup.find_all('span', class_='pc_temp_time') #将名次,歌名,时间依次打印出来 for r, n, t in zip(ranks,name,time): r =r.get_text().replace('\n', '').replace('\t', '').replace('\r', '') n = n.get_text() t = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '') data = {'排名': r, '歌曲名称': n, '歌曲时间':t} self.worksheet.write(self.nums, 0, str(r)) self.worksheet.write(self.nums, 1, str(n)) self.worksheet.write(self.nums, 2, str(t)) self.nums += 1 def main(self,): urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1, 24)] for url in urls: print(url) html = self.get_html(url) self.get_data(html) # 暂停1S time.sleep(1) #保存文件,数据持久化 self.workbook.save('酷狗TOP_500排行榜.xls') '''数据清洗''' #读取数据并输出 df = pd.DataFrame(pd.read_excel('酷狗TOP_500排行榜.xls')) df.head() #删除无效列与行 df = pd.DataFrame(pd.read_excel('酷狗TOP_500排行榜.xls')) df.head() df.drop(1,axis=0,inplace=True) df.head() #检查是否有重复值 df.duplicated() #空值处理 df.isnull().sum() #返回0,表示没有空值 #缺失值处理 df.isnull() #用describe()命令显示描述性统计指标 df.describe() '''数据可视化''' #让中文和负号能正常显示出来 plt.rcParams['font.sans-serif']=['SimHei'] matplotlib.rcParams['axes.unicode_minus']=False #绘制折线图 def PlotData(): x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.xlabel('歌曲名称') plt.ylabel('排名') plt.plot(x,y) plt.scatter(x,y) plt.title("歌曲名称与排名折线图") plt.show() PlotData() #绘制直方图 plt.rcParams['font.family']=['sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.bar(['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'],[1,3,4,5,6]) plt.legend() plt.xlabel("歌曲名称") plt.ylabel("排名") plt.title('酷狗TOP_500排行榜') plt.show() # x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title('酷狗TOP_500排行榜') plt.show() '''画出散点图和建立回归方程''' #绘制散点图 x = ['海来阿木 - 点歌的人','皮卡丘多多 - 惊雷','傅如乔 - 微微','Uu - 夏天的风','梦然 - 少年'] y = [1,3,4,5,6] plt.scatter(x,y,color='blue', s=25, marker="o") plt.xlabel("歌曲名称") plt.ylabel("排名") plt.title("歌曲名称与排名散点图") plt.show() def func2(p,x): a,b = p return a*x+b #偏差函数 def error2(p,x,y): return func2(p,x)-y plt.scatter(df['排名'],df['排名']) X = df.排名 Y = df.排名 plt.figure(figsize=(8,6)) p0 = [0,15] para = leastsq(error2,p0,args=(X,Y)) a,b = para[0] print('a=',a,'b=',b) print("求解的拟合直线为:") print("y="+str(round(a,2))+"x+"+str(round(b,2))) plt.scatter(X,Y,color='green',label='样本数据',linewidth=2) x = np.linspace(0,25) y = a*x+b plt.plot(x,y,color='red',label='拟合曲线',linewidth=2) plt.legend() plt.title('') plt.grid() plt.show() #执行主函数 if __name__ == '__main__': spider = Spider() spider.main()
四、结论
1.本次程序设计作业完成的情况小结 : 通过这次作业,让我深刻了解到了python这门语言强大的功能,同时也让我发现这身存在的问题,知识掌握得不牢固。在今后中要加倍的努力学习,不断的是实践,让自己获得更多的收获。