文章目录
python简介
python是什么?python能做什么?廖雪峰老师的python教程已经将的非常清楚。
python的安装很简单,此处也不再赘述。
查看python版本
# 查看python版本
python -V
# 进入到python解释器查看
import sys
print(sys.version_info)
print(sys.version)

python注释
单行注释 - 以#和空格开头的部分
多行注释 - 三个引号开头,三个引号结尾(引号可以是单引号也可以是双引号,但必须成对出现)
"""
第一个Python程序 - hello, world!
多行注释
"""
print('hello, world!')
# print("你好, 世界!")
python解释器
整个Python语言从规范到解释器都是开源的,我们需要Python解释器来执行编写的Python代码(以.py结尾的文件)。存在多种Python解释器,如CPython(官方提供的解释器,平时我们安装python其实就是安装官方提供的CPython解释器)、IPython(基于CPython的增强版交互式解释器,但是内核还是CPython)、PyPy、Jython、IronPython。用的最广泛的还是CPython,但是如果是交互式的话个人建议用IPython,IPython可以通过TAB键有提示的功能,交互性更强。
使用IPython
可以用python包管理工具pip安装IPython
pip安装(用哪个版本的 Python 运行安装脚本,pip 就被关联到哪个版本)
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 下载安装脚本
python get-pip.py # 运行安装脚本
执行pip install ipython进行安装。安装成功后执行ipython,如下图所示。
如果安装很慢可以参考vim笔记中关于pip配置部分配置pip的国内镜像源。

python基础
python变量类型
整形:任意大小的整数,如a=10
浮点型:小数,如a=10.6
字符串型: 单引号或者双引号,如s="hello", p='world'。当某一行代码太长,可以采用\的方式转接到下一行。也可以用"""来定义多行字符串
布尔型: True/False,如flag=True
复数型: 3+5j
s = "压缩,很多貌似无法压缩的词语或句子,被网友活生生地压缩了,像高大上不明觉厉等词。按照语文修辞学,这些词是不能这样压缩的,但是网友就这么压缩了,而且传播范围很广。\
反转,本来是一种修辞格,在网络时代,反转修辞格的大量涌现有目共睹,如撩字,大家都非常熟悉,撩的基本意思是撩逗,词性偏向于贬义,有轻薄的意思,但它被网络化以后,已经从贬义词转为中性词。"
print(s)
multi_s = """\
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
"""
print(multi_s)

python字符串与编码
所有的python文件首两行内容都应该如下所示
#!/usr/bin/python
# -*- coding: UTF-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。当然我们的python文件必须全部以utf8的格式去保存。
下面代码展示了在python里字符串如何编码(字符串按照某种格式编码成字节码)和解码(字节码按照某种格式解码成对应的字符串)。
s = "中文"
s_utf8_bytes = s.encode(encoding="utf8")
s_gbk_bytes = s.encode(encoding="gbk")
print("[{}]的utf8编码即变成字节码bytes是 {}".format(s,s_utf8_bytes))
print("[{}]的gbk编码即变成字节码bytes是 {}".format(s,s_gbk_bytes))
s_utf8 = s_utf8_bytes.decode(encoding="utf8")
s_gbk = s_gbk_bytes.decode(encoding="gbk")
print("字节码 {} 转换成utf8编码后是 [{}]".format(s_utf8_bytes, s_utf8))
print("字节码 {} 转换成gbk编码后是 [{}]".format(s_gbk_bytes, s_gbk))

python空值None
None是空值,是Python里一个特殊的值。不是0也不是空字符串
python变量命名规则
以python代码风格PEP8为参考
- 用小写字母拼写,多个单词用下划线连接(注意不是驼峰式命名规则)
- 类中受保护的实例属性,应该以一个下划线开头
- 类中私有的实例属性,应该以两个下划线开头
变量使用和类型转换
- type函数可对变量的类型进行检查,如
type(a) - 可以采用内置函数对变量类型进行强制转换
int():将一个数值或字符串转换成整数,可以指定进制int("num_str", base=10)将base进制的数(字符串表示,指定进制后必须是字符串)转换为十进制float():将一个数值或字符串转换成浮点数str():将指定的对象转换成字符串形式chr():将整数转换成该编码对应的字符串(一个字符)。参考java里的char和int的互换。ord():将字符串(一个字符)转换成对应的编码(整数)。参考java里的char和int的互换。hex():将十进制转换为十六进制(返回的是字符串)oct():将八进制转换为十六进制(返回的是字符串)bin():将十进制转化为二进制(返回的是字符串)
下面代码展示了类型转换的例子,其中以0x开头的表示十六进制,以0o开头的表示八进制,以0b开头的表示二进制
print(int("11")) # 11
print(int("11", base=2)) # 3
print(float("36.8")) # 36.8
print(str(12)) # 12
print(chr(65)) # A
print(ord('A')) # 65
print(hex(18)) # 0x12
print(oct(18)) # 0o22
print(bin(4)) # 0b100
输入和输出函数
input(): 输入函数,可通过设置参数来增加输入提示语句print(): 输出函数,可通过占位符的方式格式化输出,其中%s代表字符串,%d代表整数,%f代表小数,%%表示百分号(因为百分号代表了占位符)。当不清楚用%d还是用其他时,用%s总是会没错的。当然个人更倾向于使用string.format()函数来格式化输出,更详细的string.format()信息可参考python菜鸟教程-format函数。
name = input("输入你的名字: ")
age = int(input("输入你的年龄: "))
salary = float(input("输入你的月薪: "))
print("姓名是: %s\t年龄是: %d\t月薪是: %.2f\t" % (name, age, salary))
print("姓名是: {}\t年龄是: {}\t月薪是: {:.2f}\t".format(name, age, salary))
print("单独的%")
print("%s 使用了占位符, 显示%%" % (name))
# print("%s 使用了占位符, 显示%" % (name)) # ValueError: incomplete format

python运算符
这里是参考Github上的python100天教程,上面列的非常详细。
需要重点记忆的是 下标、切片、成员运算符、逻辑运算符、(复合)赋值运算符。
| 运算符 | 描述 |
|---|---|
[] [:] |
下标,切片 |
** |
指数 |
~ + - |
按位取反, 正负号 |
* / % // |
乘,除,模,整除 |
+ - |
加,减 |
>> << |
右移,左移 |
& |
按位与 |
^ \| |
按位异或,按位或 |
<= < > >= |
小于等于,小于,大于,大于等于 |
== != |
等于,不等于 |
is is not |
身份运算符 |
in not in |
成员运算符 |
not or and |
逻辑运算符 |
= += -= *= /= %= //= **= &= |= ^= >>= <<= |
(复合)赋值运算符 |
分支结构
语法很简单就是 if elif elif else
age = int(input("输入你的年龄: "))
if age < 18:
print("你还未成年")
elif age < 50:
print("你正值壮年")
elif age < 100:
print("你可以退休了")
else:
print("活宝一个")
循环结构
- 第一种是
for ... in ...循环
sum = 0
for x in range(11):
sum += x
print(sum) # 55
- 第二种是
while bool循环
i = 0
sum = 0
while i<11:
sum +=i
i+=1
print(sum) # 55
以上这两种循环都可以用break提前退出循环, continue结束本次循环进入到下个循环。
python字符串
我们在上面也提到了字符串的编码以及如何定义多行字符串。
字符串和整型及浮点型不同,字符串是结构化的,所以有内置的方法和属性。
我们知道转义字符\,但是我们可以在转义字符之前加r来取消转义字符。
name = "\u5927\u6570\u636e"
print(name) # 大数据
name = r"\u5927\u6570\u636e"
print(name) # \u5927\u6570\u636e

也可以考虑使用repr(obj)函数,将对象转化为供解释器读取的形式
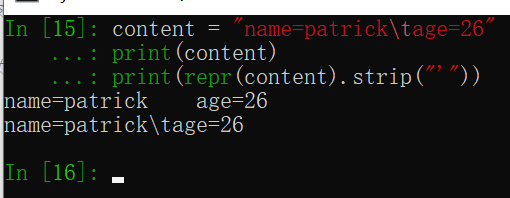
下面代码展示了字符串的一些常用操作。更详细的可参考python菜鸟教程-字符串。
s = "abcdefg"
print(s[0:4]) # abcd
print(s[:-1]) # abcdef
print(s[::-1]) # gfedcba
print(len(s)) # 7
print(s.upper()) # ABCDEFG
print(s.lower()) # abcdefg
print(s.find("def")) # 3
print(s.startswith("abc")) # True
print(s.endswith("fg")) # True
print(" abc \n".strip()) # abc
| 操作或函数 | 描述 |
|---|---|
| s[a:b] | 按照前闭后开的原则,去字符串s从下标为a开始到下标为b结束的子串 |
| s[:-1] | 取字符串开始到结尾的子串即除去最后一个字符的子串。这是因为字符串可以从0开始取第一个,也可以从-1开始取最后一个 |
| s[::-1] | 逆置字符串。等价于 ''.join(reversed("abcdefg")) 和 reduce(lambda x,y: y+x, "abcdefg") |
| len(s) | 获取字符串长度 |
| s.upper() | 将字符串全部变成大写,返回新字符串 |
| s.lower() | 将字符串全部变成小写,返回新字符串 |
| s.find(“def”) | 寻找子串所在字符串的位置,找不到返回-1 |
| s.startswith(“abc”) | 判断字符串是否以指定子串开始 |
| s.endswith(“fg”) | 判断字符串是否以指定子串结束 |
| s…strip() | 取消字符串前后空格和回车符 |
列表
- 列表初始化。用
[]表示,多个数据用逗号隔开如l = [1, 2, 3, 4, 5] - 获取列表长度。用
len(list) - 遍历列表。用
enumerate()函数同时获取下标和值 - 获取某个下标元素。用
list[index]即用下标的方式 - 在末尾添加元素。用
list.append(obj) - 删除元素。用
list.pop(index),默认index=-1即默认删除最后一个元素 - 反转列表。用
list.reverse() - 清空列表。用
l.clear() - 列表拼接。用
list1+list2 - 列表排序。用
list.sort()函数或者用new_list=sorted()函数生成一个新的列表。两者都需要一个key参数来排序。参数key是一个函数,该函数只有一个输入参数及列表的元素。
下面代码展示了列表的常用操作
# 初始化列表
l = [1, 2, 3, 4, 5]
# 获取列表长度
print(len(l))
# 获取指定下标的值
print(l[1])
# 遍历列表 同时获得下标和值
for i, v in enumerate(l):
print("下标是 {} 值是 {}".format(i, v))
# 在列表末尾添加一个元素
l.append(6)
# 删除一个元素, 默认参数是-1,即最后一个元素
l.pop()
# 反转列表
l.reverse()
# 清空列表
l.clear()
# 列表拼接
print([1, 2] + [3, 4, 5])
# 列表排序
tp_list = [("patrick",26,100),("mata",28,300),("uzi",22,300),("faker",20,400),("rookie",21,500)]
# 用列表自带方法排序
tp_list.sort(key=lambda x:x[1])
print(tp_list)
# 用内置方法sorted()函数给列表排序,生成新的有序列表,原来的列表顺序不变
new_sorted_tp_list = sorted(tp_list,key=lambda x:x[1],reverse=True)
print(new_sorted_tp_list)
# 根据多个字段进行排序
tp_list.sort(key=lambda x:(x[2],x[1]))
print(tp_list)
# 多字段多规则排序 可以在字段前添加+、-
tp_list.sort(key=lambda x:(-x[2],x[1]))
print(tp_list)
生成式和生成器
先说下python语法里的三元表达式 xx if bool_expression else yy ,当表达式为True时返回xx否则返回yy。
如下例所示。
res = "success" if 3 > 2 else "fail"
print(res) # success
res = "success" if 3 > 4 else "fail"
print(res) # fail
生成式创建列表创建的是collections.Iterable对象,生成器创建的是collections.Iterator对象。Iterator对象继承于Iterable,只不过Iterator对象多了一个next()方法,可以类比Java里的迭代器。从数目上看,Iterable对象的数目是固定可数的,Iterator是通过next()方法不断获取的即可能是无限的(直到发生StopIteration异常才知道遍历结束,当然可以通过for … in循环来避免该异常)。其中Iterable是可以多次遍历的即多次for循环,但是Iterator遍历一次之后就没有数据了,想再次查看只能重新生成新的Iterator对象。
可以采用help(Iterable)查看帮助文档
或者通过model.__file__查看模块所在源码路径查看源码。__file__是模块的内置属性,可以查看模块所在文件路径

判断一个对象是否可以迭代
from collections import Iterable
isinstance([1,2,3],Iterable)
生成式创建列表的方式是通过[],生成器创建列表的方式是通过()。而且由于生成器创建的是Iterator对象,它存储的是迭代方法,并没有完全存储所有的数据,故而生成器创建列表占用内存远小于生成式创建列表所占用的内存。可以通过sys.getsizeof(obj)查看对象占用内存大小。
# 生成式创建列表 前面的x就是新生成的列表的元素 if是过滤条件
f = [x for x in range(1, 11) if x % 2 == 0]
print(f) # [2, 4, 6, 8, 10]
print(sys.getsizeof(f)) # 128
# 这里构造两层for循环 x+Y就是新生成的列表的元素 if是过滤条件
f = [x + y for x in 'ABCDE' for y in '1234567' if x=='A' and y in ['2','4']]
print(f) # ['A2', 'A4']
print(sys.getsizeof(f)) # 96
# 生成器列表
f = (x for x in range(1, 11) if x % 2 == 0)
print(f) # <generator object <genexpr> at 0x0000015092FBB150>
print(sys.getsizeof(f)) # 88
for x in f:
print(x)

还有一种通过yield关键字来使得一个函数变成一个生成器函数。可以将yield理解为return,下次迭代时就从yield语句后再执行。关于更详细的内容可以参考python菜鸟教程-yield解析
如下面代码所示,获取文件的每一行,然后通过生成器的方式去迭代返回,这样就不会把文件的所有行全部存储起来占用大量内存了。
def read_line_file(fpath):
with open(fpath, 'r', encoding="utf8") as f:
while True:
s = f.readline()
if s:
yield s
else:
return
for s in read_line_file("d:/a.txt"):
print(s.strip()) # 注意我这里使用了strip()函数消除掉了后面的回车符这样才能保证输出内容和文件内容一致
假设文件d:/a.txt内容如下,输出结果和文件内容一致
这是第一行
这是第二行
这是第三行
这是第四行
这是第五行
元组
类似于列表,只不过元组里的元素无法改变,一样可通过for in进行遍历。
可通过list(tuple)将元组变成list,也可以通过tuple(list)将列表变成tuple。
由于元组的不可修改特性,所以能用元组的地方就尽量用元组。
# 创建一个tuple
tp = ("patrick", 26)
# 根据tuple创建list
tp_list = list(tp)
print(tp_list) # ['patrick', 26]
# 根据list创建tuple
print(tuple([1,2,3])) # (1, 2, 3)
# 遍历tuple
for x in tp:
print(x)
集合
- 集合set中的元素是不能重复的。即元素需要是不可变对象。
- 创建集合使用
{}或set()方法,创建空集合必须使用set(),因为{}用来创建字典。 - 可以使用生成式生成集合。
{num for num in range(1, 100) if num % 30 == 0} - 添加元素。
s.add(x) - 删除元素。
s.discard(x) - 清空集合。
s.clear() - 集合交并差(
& | -)。运算符重载。
# 采用set()构造
s = set("abbccdefffg")
print(s) # 已去重
# 采用生成式创建集合
set4 = {num for num in range(1, 100) if num % 30 == 0}
# 添加元素
s.add('h')
# 删除元素
s.discard('a')
# 清空集合
s.clear()
字典
字典dict是由键值对组成,类似于Java里的HashMap。字典dict的key必须是不可变对象,这点尤其重要,一般都用字符串作为key。
- 可通过{}或dict()方法或zip函数或生成式创建字典
- 获取指定key值。
dict.get(key,default_value) - 更新指定key值。
dict[k]=v或dict.update(k1=v1, k2=v2) - 删除指定key值。
dict.pop(k,default_value) - 判断指定key是否在dict里。
key in dict - 遍历dict。
for k,v in dict.items()
# 采用{}创建dict
info = {"name": "patrick", "age": 26}
print(info) # {'name': 'patrick', 'age': 26}
# 采用dict()创建dict
info = dict(name="patrick", age=26)
print(info) # {'name': 'patrick', 'age': 26}
# 通过zip函数将两个序列压成字典(zip函数生成的是个迭代器对象)
info = dict(zip(["patrick","marry","jeffery"],[26,27,28]))
print(info) # {'patrick': 26, 'marry': 27, 'jeffery': 28}
# 通过生成式的方式创建dict
items3 = {num: num ** 2 for num in range(1, 5)}
print(items3) # {1: 1, 2: 4, 3: 9, 4: 16}
# 获取指定key对应的值,获取不到返回默认值
print(info.get("patrick",11)) # 26
# 更新指定key值
info["patrick"]=99
print(info.get("patrick",11)) # 99
# 更新指定键值对
info.update(patrick=18, marry=19)
print(info) # {'patrick': 18, 'marry': 19, 'jeffery': 28}
# 删除指定key,并返回key对应的值,如找不到key则返回默认值
print(info.pop("patrick",100)) # 18
# 判定key是否在dict里
print("marry" in info)
# 遍历dict
for k,v in info.items():
print("key={} value={}".format(k,v))
和list比较,dict有以下几个特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
而list相反:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
究其原因还是因为在底层实现上list是由链表实现的,dict是由哈希表实现的。
不可变对象与可变对象
Python 在 heap 中分配的对象分成两类:可变对象和不可变对象。所谓可变对象是指,对象的内容是可变的,例如 list、dict等。而不可变的对象则相反,表示其内容不可变,如int、float、string、tuple。
- 不可变对象。由于 Python 中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。

- 可变对象。其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。

python里的函数
python用def关键字来定义函数,包括函数名、函数参数,使用return关键字来返回函数值,如果没有显示调用return,那么该函数的返回值就是None。
如下自定义一个绝对值函数my_abs。
def my_abs(x):
if x >= 0:
return x
else:
return -x
空函数
可以通过pass关键字来充当一个占位符先保证语法正确。后面再补上完整的函数实现。同样的,pass关键字也可以用在其他如if或者for或者while结构里。
def nop():
pass
函数参数
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数(即位置参数)外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
值得注意的是参数设置顺序:必选参数在前,默认参数在后,否则Python的解释器会报错(这也很好理解,如果两个参数,第一个参数是默认参数,第二个参数是必选参数,但是我在调用时只填写一个参数,那么这个参数到底是必选参数还是默认参数呢)。
默认参数
默认参数的一个问题:默认参数必须要设置成不可变对象。为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
参考下面的代码,展示了如何定义函数(带有默认参数),以及默认参数不是不可变对象的疑惑解释。
def enroll(name, gender, age=6, city='Beijing'):
print("name={}\tgender={}\tage={}\tcity={}".format(name, gender, age, city))
# 使用默认参数city
enroll("patrick","boy",age=18) # name=patrick gender=boy age=18 city=Beijing
# 调用函数
enroll("marry","girl",age=19,city="ShenZhen") # name=marry gender=girl age=19 city=ShenZhen
# 可以通过名字匹配的方式不用强制保证默认参数的调用次序
enroll("jackie","boy",city="WuHan",age=20) # name=jackie gender=boy age=20 city=WuHan
# 此处函数的默认参数是不可变对象list
def add_end(l=[]):
l.append("END")
return l
# 第一次调用会给list增加一个"END"
print(add_end()) # ['END']
# 第二次调用会给list再增加一个"END" 所以就是两个END"
print(add_end()) # ['END', 'END']
# 上面的例子就违背了初衷, 应该按照如下设计
# None是不可变对象
def add_end(l=None):
if not l:
l = []
l.append("END")
return l
print(add_end()) # ['END']
print(add_end()) # ['END']
可选参数
可选参数就是将多个参数变成一个元组tuple的形式传入给函数,用*args表示可选参数。
下面代码就展示了用可选参数的方式累计求和
# 定义可选参数, 用*args表示,args就是一个tuple
def sum_all(*args):
print(type(args)) # <class 'tuple'>
sum = 0
for x in args:
sum += x
return sum
# 传入多个参数作为可选参数
print(sum_all(1, 2, 3, 4)) # 10
l = [1, 2, 3, 4, 5]
# 用列表的形式传入作为可选参数,注意添加* 因为list可以转为tuple
print(sum_all(*l)) # 15
# 用tuple的形式传入作为可选参数,注意添加*
t = (1, 2, 3, 4, 5)
print(sum_all(*t)) # 15
关键字参数
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
用**kwargs来定义关键字参数。
下面代码展示了关键字参数函数的定义及调用
# 定义关键字参数 通过**kwargs来定义
def person(name, gender, **kwargs):
print(type(kwargs)) # <class 'dict'>
print("name={}\tgender={}\tother={}".format(name, gender, kwargs))
# 通过k=v来设置关键字参数
person("patirck", "boy", age=20, city="shenzhen")
info = {"age": 26, "city": "shenzhen"}
# 通过字典来设置关键字参数, 注意调用的时候在dict前加上**
person("patirck", "boy", **info)
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。如果要限制关键字参数的名字,就可以用命名关键字参数。
注意命名关键字的参数必须要全部填写否则会报错,有默认值的除外。
可通过在位置参数后添加一个* 来创建命名关键字参数,或者是已经有可选参数,后面的都是关键字参数。
下面的代码就展示了命名关键字参数的使用。
# 通过命名关键字参数限制关键字参数的名字,即在位置参数后添加一个* , *后面的参数被视为命名关键字参数
# 注意命名关键字参数必须要全部填写内容,否则会报错,有默认值的除外
def person(name, gender, *, city, job):
print(name, gender, city, job)
# 没有填写job所以报错
# person("patirck", "boy", city="shenzhen") # TypeError: person() missing 1 required keyword-only argument: 'job'
person("patirck", "boy", job="码农", city="shenzhen")
d = {"job":"码农", "city":"shenzhen"}
# 一样可以通过dict来设置关键字参数
person("patirck", "boy", **d)
# person("patirck", "boy", age=20, city="shenzhen") # TypeError: person() got an unexpected keyword argument 'age'
# 已经有可选参数了,所以就没有必要按照上面的再添加* 可选参数后的就是命名关键字参数
def person(name, gender, *args, city, job):
print(name, gender, args, city, job)
person("patirck", "boy", "11",12,job="码农", city="shenzhen") # patirck boy ('11', 12) shenzhen 码农
# 没有填写必要的命名关键字参数所以报错
# person("patirck", "boy", "11",12) # TypeError: person() missing 2 required keyword-only arguments: 'city' and 'job'
参数组合
参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
重要的结论:对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。这也是后面装饰函数的前提条件。
参数组合更详细的内容可以参考廖雪峰老师的python教程–函数的参数。
函数的参数总结
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
函数的参数检查
数据类型检查可以用内置函数isinstance()实现。
如下所示,检查参数是否是整型或者浮点型,不是的话通过raise抛出异常TypeError并附上异常提示语句。
def my_abs(x):
# 对传入的参数进行类型检查
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x
print(my_abs(-10)) # 10
# print(my_abs("abc")) # TypeError: bad operand type
函数返回多个值
在python里函数返回多个值其实是一个假象,返回的其实是一个tuple对象。
下面的代码就很好地展示出了函数返回多个值的情况。
# 返回一个十进制数的十六进制、八进制、二进制 形式
def get_hex_oct_bin(x):
if not isinstance(x, int):
raise TypeError("参数类型必须是int")
return hex(x), oct(x), bin(x)
# 分别用多个变量接收多个返回值
s1, s2, s3 = get_hex_oct_bin(18)
print(s1, s2, s3) # 0x12 0o22 0b10010
# 用变量接收返回值tuple
t = get_hex_oct_bin(18)
print(type(t)) # <class 'tuple'>
print(t) # ('0x12', '0o22', '0b10010')
python函数进阶
匿名函数
python的匿名函数语法是 lambda [arg1 [,arg2,.....argn]]:expression。其中expression的值就是该匿名函数的返回值。
如果一个非常简单的函数如求两个数的和,没有必要通过def去定义一个函数,可以直接用匿名函数来实现。
下面代码就展示了匿名函数的定义及其使用。
# 将tuple变成str
print(str((3,4))) # (3, 4)
# 通过变量str来接收匿名函数
str = lambda x, y: x + y
# 同时原先的内置函数str就被我们定义的匿名函数替代了
print(str(3, 4)) # 7
其实函数名也就是变量名,这也就是为什么变量的命令不能和python的关键字冲突的缘故。
函数在python里也是一种变量(深刻理解这句话),是可以作为函数参数和返回值的。
map/reduce/filter/sorted函数
可以联想大数据MapReduce框架中的map方法和reduce方法。
map(func, *iterables) --> map object : 对Iterable中的每个元素使用func。如果可选参数的n个Iterable对象,那么func的参数就是n个。
reduce(function, sequence[, initial]) -> value:对sequence中每个元素聚合,function的参数是2个,返回值是1个。
filter(function or None, iterable) --> filter object:对Iterable中的元素用function进行过滤。如果function是None则返回是True的元素。function的入参就是Iterable中的元素,返回值就是布尔值。
sorted(iterable, key=None, reverse=False):排序函数在上面讲列表的时候用过,此处不再赘述。
# 采用map将Iterable里的数据平方
m = map(lambda x:x**2, [1,2,3])
# map返回的是Iterator对象
print(isinstance(m, collections.Iterator)) # True
print(list(m)) # [1, 4, 9]
# 如果是多个Iterable的话,则一一对应去取值作为func的参数
l = list(map(lambda x,y:x+y, [1,2,3], [4,5,6]))
print(l) # [5, 7, 9]
# 采用reduce对Iterable里的数据累积
from functools import reduce
r = reduce(lambda x,y:x*y, [1,2,3,4])
print(r) # 24
# 采用filter过滤Iterable里的数据 只有偶数才符合
f = filter(lambda x:x%2==0, range(1,11))
# map返回的是Iterator对象
print(isinstance(f, collections.Iterator)) # True
print(list(f)) # [2, 4, 6, 8, 10]
# 如果filter的函数是None的返回,则返回那些是True的元素
l = [ x for x in filter(None, [-1,0,1,2,3,"","abc"]) ]
print(l) # [-1, 1, 2, 3, 'abc']
关于filter函数有个很实际的例子就是,运用埃氏筛法求素数。通过filter函数不断地取过滤。
# -*- coding: UTF-8 -*-
def odd_iter():
'''
生成一个从3开始的奇数Iterator
:return: Iterator
'''
n = 1
while True:
n += 2
yield n
# 返回一个函数,判断传入函数的参数是否能被n整除
def filter_iter_by_prime_num(n):
return lambda x: x % n != 0
def prime_iter():
yield 2
it = odd_iter()
while True:
num = next(it)
yield num
it = filter(filter_iter_by_prime_num(num), it)
if __name__ == '__main__':
ct=0
for i in prime_iter():
if i > 100:
break
# print(i)
ct+=1
print("total count is {}".format(ct))
函数作为返回值与闭包
首先我们应该对python中的变量有如下了解
- python中的变量不需要声明,变量的赋值操作即是变量声明和定义的过程
- 如果变量没有赋值,则python认为该变量不存在
- 在函数之外定义的变量都可以称为全局变量。全局变量可以被文件内部的任何函数和外部文件访问
- 全局变量建议在文件的开头定义
- 也可以把全局变量放到一个专门的文件中,然后通过import来引用
- 也可以定义自己的常量类
- 局部变量可以粗糙地理解为函数方法里的变量
查看下面的例子,lazy_sum的返回值就是函数sum,且函数sum引用了局部变量。
这些局部变量都保存在返回的函数中,这就是闭包。
# 将sum函数作为lazy_sum函数的返回值
# 内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f1 = lazy_sum(1, 2, 3, 4)
# 返回的函数f1并没有立刻执行, 只有主动调用f1后才会执行
print(f1()) # 10
f2 = lazy_sum(1, 2, 3, 4)
print(f2()) # 10
# 每次调用都会产生一个新的函数,所以两者不相等
print(f1 == f2) # False
print(type(f1)) # <class 'function'>
看看下面这个闭包的例子,是一个非常经典的例子。返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
# 返回的函数中引用了循环变量
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
# 返回的结果并不是想象中的 1 4 9 这是因为闭包引用了循环变量i
# 由于主动调用时才会执行,但是此时所有的循环变量i都已经变成了3
print(f1(), f2(), f3()) # 9 9 9
如果一定要引用循环变量,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值。
def count():
def f(j):
def g():
return j*j
return g
# return lambda :j*j
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
f1, f2, f3 = count()
print(f1(), f2(), f3()) # 1 4 9
用闭包实现一个计数器函数,每次调用一次,返回值就加一。
实现如下,闭包引用了列表(其实引用的是列表的地址可类比为C++的指针),此处列表的引用是没有变化的。
def create_counter():
l = [0]
def counter():
l[0] = l[0] + 1
return l[0]
return counter
cc = create_counter()
print(cc()) # 1
print(cc()) # 2
print(cc()) # 3
python中的偏函数
偏函数是functools模块提供的一个功能。当一个函数的参数太多时,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
下面的代码就展示了偏函数的使用方法。创建一个将二进制数转化为十进制的方法。
当然也可以将自定义函数的某些参数值固定。
import functools
print(int("1110", base=2)) # 14
# 通过偏函数固定原先的int函数中的base参数值为2
int2 = functools.partial(int, base=2)
print(int2("1110")) # 14
python中的装饰器
装饰器是为了在不改变源代码的前提下增强函数功能的。它就是一个高阶函数,以函数作为入参,且以函数作为返回值。
我们以上面写的返回一个十进制数的十六进制、八进制、二进制 形式的函数get_hex_oct_bin为例,来对该函数进行增强,譬如在日志里打印该函数的执行时间、返回结果、以及该函数的运行时间。
定义好装饰器函数log后,在需要增强的函数上面添加@log即可完成对该函数的增强。
下面的@functools.wraps(func)是为了解决函数的内置属性__name__不会被log函数的返回值wrapper替代。如果不加这个执行print(get_hex_oct_bin.__name__)就会看到打印的是wrapper。
import datetime
import time
import functools
def log(func):
# 必须要添加该配置,否则被log装饰的方法的__name__就是wrapper而不是原本方法名
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 以秒为单位
start = time.perf_counter()
# 获取格式化的当前时间
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} start call {} ".format(current_time, func.__name__))
res = func(*args,**kwargs)
print("{} result value is {}".format(func.__name__, res))
end = time.perf_counter()
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} end call {} ".format(current_time, func.__name__))
print("{} run time {} seconds".format(func.__name__, (end-start)))
return res
return wrapper
# 返回一个十进制数的十六进制、八进制、二进制 形式
@log
def get_hex_oct_bin(x):
if not isinstance(x, int):
raise TypeError("参数类型必须是int")
# 睡眠5秒
time.sleep(5)
return hex(x), oct(x), bin(x)
print(get_hex_oct_bin.__name__) # get_hex_oct_bin
get_hex_oct_bin(18)
增强后的结果如下图所示

类比Java里的注解,我们可以在装饰器里添加参数。只是在上面的装饰器函数基础上在嵌套一层函数即可。
def enhance_log(**text):
def dec(func):
# 必须要添加该配置,否则被log装饰的方法的__name__就是wrapper而不是原本方法名
@functools.wraps(func)
def wrapper(*args, **kwargs):
print("text dict on [{}] is {}".format(func.__name__, text))
# 以秒为单位
start = time.perf_counter()
# 获取格式化的当前时间
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} start call {} ".format(current_time, func.__name__))
res = func(*args, **kwargs)
print("{} result value is {}".format(func.__name__, res))
end = time.perf_counter()
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("{} end call {} ".format(current_time, func.__name__))
print("{} run time {} seconds".format(func.__name__, (end - start)))
return res
return wrapper
return dec
@enhance_log(desc="求和函数", version="v1.0")
def func1(x,y):
print("{}+{}={}".format(x,y,x+y))
return x+y
@enhance_log()
def func2(x,y):
print("{}-{}={}".format(x,y,x-y))
return x - y
func1(3,2)
func2(3,2)
运行结果如下所示。func1上的装饰器上添加了参数,func2的装饰器上没有添加参数。

python模块(module)与包(package)
在Python中,一个.py文件就称之为一个模块(Module)。
为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
值得注意的是,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。
__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是mycompany(以下面的目录结构为例)。
文件www.py的模块名就是mycompany.web.www,两个文件utils.py的模块名分别是mycompany.utils和mycompany.web.utils。
mycompany
├─ web
│ ├─ __init__.py
│ ├─ utils.py
│ └─ www.py
├─ __init__.py
├─ abc.py
└─ utils.py
自己创建模块时要注意命名,不能和Python自带的模块名称冲突。
python文件模板
下面是.py文件的模板。
第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;可以使用module.__doc__访问该模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;
倒数第二行if __name__=='__main__':只有在运行该模块文件的时候才会为True,才会执行test()方法,当要导入该模块的时候该表达式为False。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Michael Liao'
import sys
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()
作用域
在python中,为了让某些函数或者变量不被外界访问或者说是将其变为私有的(类比Java的private),是用_来实现的,实际上这是一种编程习惯。因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
类似__xx__这样的变量是特殊变量,如__author__、__name__、__doc__等,有特殊的用途,可以被直接访问。但是我们不应该去定义这样的变量,如果要定义私有变量,可以使用如_salary或__salary的方式。
如下面的例子,_private_1和_private_2都是私有函数,可以通过调用公有函数greeting来访问。这是一种非常有用的代码封装和抽象的方法。
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
安装第三方模块
参考上面安装IPython的方式通过pip去安装第三方模块。当然也可以选择用Anaconda去安装,但是这个比较麻烦,后面学到机器学习再去深究这个。
模块搜索路径
python模块搜索的路径顺序是:程序主目录、PYTHONPATH目录、python的内置模块和第三方库。
可以通过sys.path能够看到模块搜索的路径。

如果想添加自己的搜索目录,有如下两种方法
- 通过
sys.path.append("d:/test")添加自己的目录,不过这种方法只在运行时有效,运行结束后就失效。如下图所示,我的d:/test目录下有一个prime.py文件,在添加目录后能正确导入我的模块。

- 通过设置
PYTHONPATH环境变量。当然如果在linux环境下如果想永久有效的话可以将PYTHONPATH环境变量配置在如/etc/profile文件里
# Windows环境下
# 获取环境变量值
set PYTHONPATH
# 设置环境变量值
set PYTHONPATH=$PYTHONPATH;d:/test

这里列出如何查看、删除和更新环境变量的值。其实从代码里可以看出环境变量os.environ可以像字典那样获取和更新数据。只不过类型不是字典。
import os
from collections import Iterable
env_dict = os.environ
# 设置环境变量
env_dict.update(demo="Hello Wolrd")
# 获取环境变量值
print(env_dict.get("demo")) # Hello Wolrd
# 删除环境变量
print(env_dict.pop("demo")) # Hello Wolrd
print(env_dict.get("demo", "Nothing")) # Nothing
print(isinstance(env_dict, Iterable)) # True
# 遍历打印环境变量值
for k, v in os.environ.items():
print("{}={}".format(k, v))
参考网址
廖雪峰老师的python教程
Github上的python100天教程
python菜鸟教程–关于可变对象与不可变对象
为什么python对象相同但是id却不同
python如何定义常量类
