本文基于cs224n课程的Machine Translation部分和Michael Collins NLP的Machine Translation部分。从Tranditional MT介绍到SMT(statistical Machine Translation),再到Sequence to Sequence 、Attention,并结合其中的几篇经典论文阐释,同时考虑到15年Google Brain提出的Pointer network也是一种seq2seq模型,且在自动文摘应用较多,一起介绍。
Early Machine Translation(1950s)
早期的机器翻译系统几乎都是基于规则,利用双语词典完成直接的机器翻译。由于身处冷战的背景,当时的机器翻译基本都是俄语向英语的转化。(System were mostly Rule-Based,using a bilingual dictionary to map Russia words to their English counterparts.)
上述的方式是一种直接的机器翻译(Direct MT)方式,没有利用句法分析等方法,因此出现了基于转移的方法(Transfer-Based Approach)。比如利用句法分析结果可以解决部分语序的问题。
其核心思想即将原始语句转化为句法分析树,再将原始语句的句法分析树转化为目标语句的句法分析树,再将目标语句的句法分析树转化为输出语句,利用句法分析树这个中间过程生成目标语句。

当然也有提出一种称为基于中间语句的方法(Interlingua-Based Approach)

虽然看起来十分精妙,将原始语句转化为一种独立的中间语句,再转化为目标语句,但是根本无从知道这种中间语句的样子,也便是空中楼阁了。
Statistical Machine Translation(1990s-2010s)
在统计机器翻译中,一般会应用到贝叶斯规则,并将整个翻译系统分解为翻译模型(Translation Model) 和 语言模型(Language Model)。
下图所示将法语(French)翻译为英语(English),通过贝叶斯规则分别得到翻译模型和语言模型
和
。

对于Target language的语言模型
,可以参考之前博客,利用N-gram LM或者RNN-LM都能处理,但是翻译模型就比较复杂了,在Translation Model中,最重要的是找到双语语料库并在其中找到Alignment,可以参考IBM model1和IBM model2。
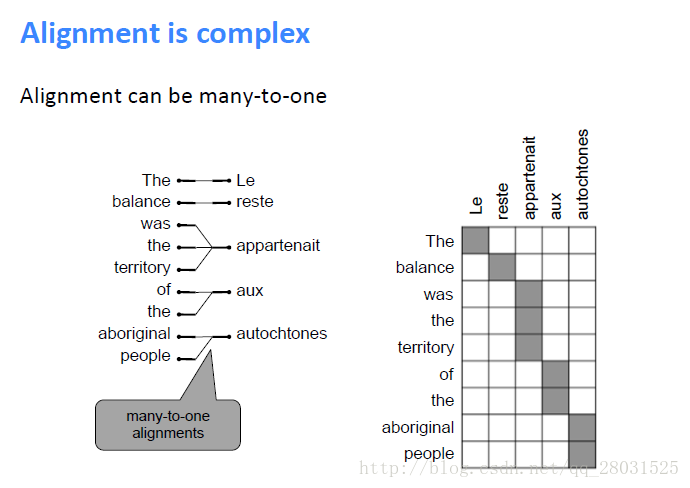
对于Translation Model,第一步是Alignment,所谓Alignment,既是找到原文中哪个句子或者短语翻译到译文中的哪个句子或短语。但是Alignment存在不同语言之间多对一(many-to-one)、一对多(one-to-many)甚至没有匹配(no counterpart)的情况,如下翻译系统中的多对一情况:
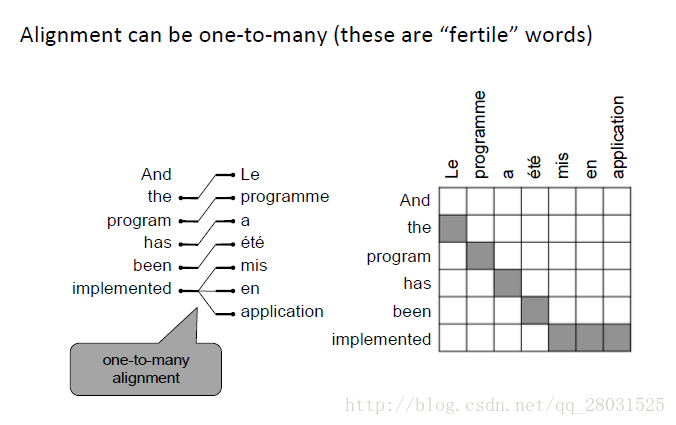
一对多(one-to-many):
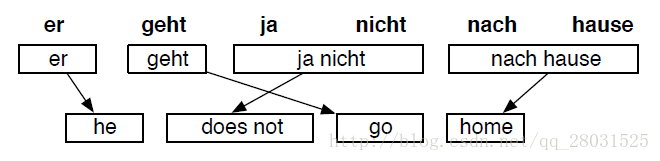
当然不仅需要考虑Alignment,还需要考虑到重新排序(reordering)等其他情况。如在日文中,谓语动词一般位于宾语之后,这就和英文中的主谓宾结构不同了。如下是法语和英文之间的翻译:
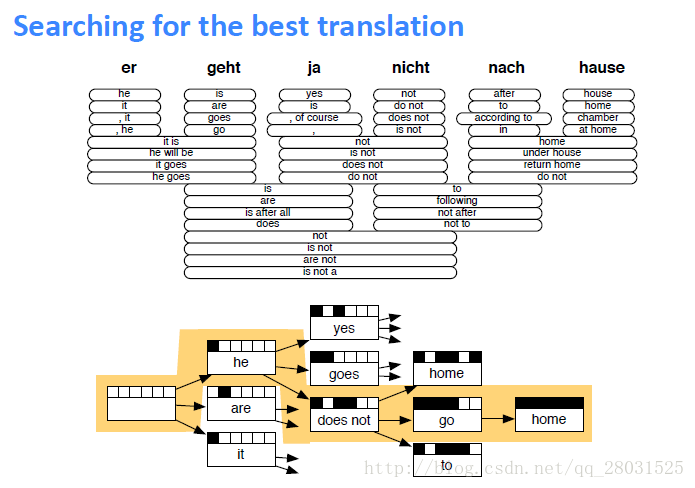
之后就需要寻找最好的翻译语句了,可能会用到语言模型或者Beam Search等方式。
以上仅是对SMT一种处理方式的介绍,且简化了很多复杂的过程。如在IBM模型中,Alignment的计算是很复杂的,需要引入一些中间变量,并利用复杂的算法进行参数估计。通过以上的流程,可以看出统计机器翻译存在诸多不足:

Neural Machine Translation(NMT) (2014-)
在上述的SMT中,将整个翻译系统拆分为不同的子系统并分别进行优化,这种方式并不一定能得到最优解且系统设计十分复杂,因此考虑将所有的这些步骤都放入一个统一的系统,于是设计出NMT(Neural Machine Translation)。
sequence-to-sequence
在一个简单的神经网络中完成机器翻译的方式称为NMT,这个神经网络也被称作sequence-to-sequence,在早期的系统中,这个神经网络采用了两个RNNs。当然在之后的系统中,已经将RNNs换做LSTMs并且做了很多优化设计(如采用Deep LSTMs)。这里为了方便介绍,还以RNNs为例。
利用深度学习,我们只学习一个统一的模型,一个统一的最终目标函数。在优化目标函数的过程中,得到end-to-end 的joint模型。
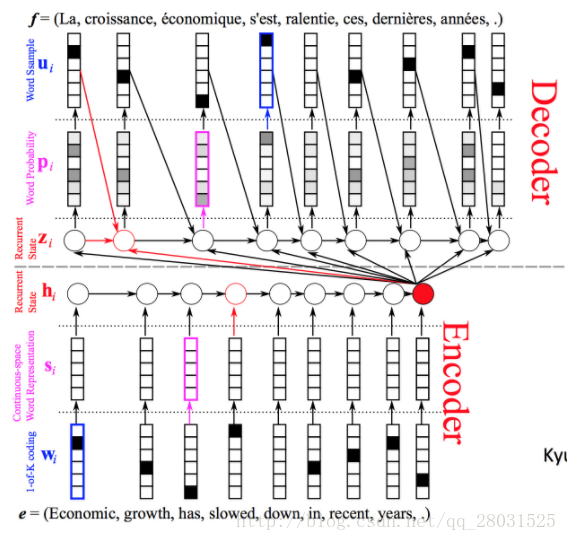
其中,
Encoder端:
代表单词的one-hot encoding,
代表词向量(word vector),
是标准RNN中的隐藏层状态,其中最后的红色圆圈代表前面整个句子的语义(summary of the whole input sentence)。
Decoder端:
代表解码过程中的隐藏层,其中隐藏层的输入来自三个方面:
1. 前一个状态的隐藏层;
2. 前一个预测结果
(Language Model);
3. Encoder端整个句子的语义概述(也可无此条)
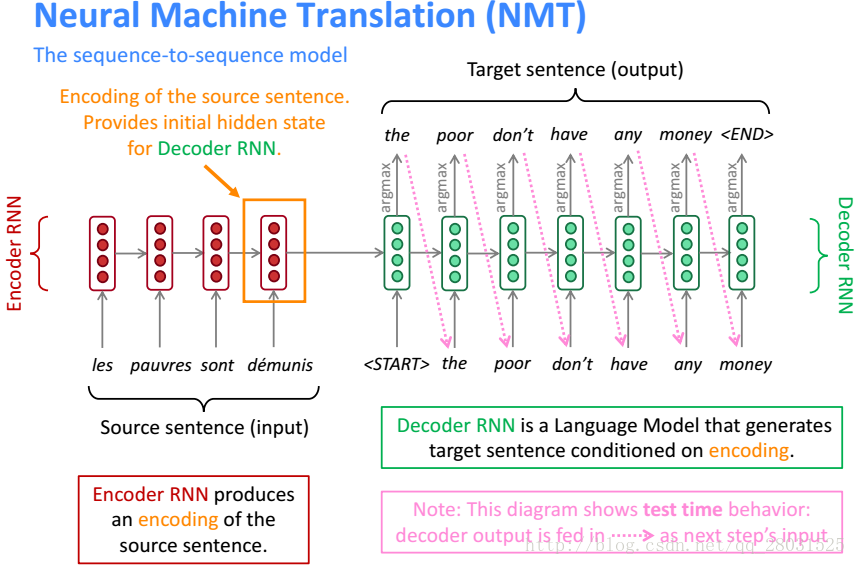
sequence-to-sequence模型是条件语言模型(Conditional Language Model)的一种,在于在Decoder端的语言模型中,条件概率的计算源于Encoder端的原始句子x和之前的输出。

对于如何训练NMT系统,方法可以和RNN-LM一样,在输出端的每个时刻计算交叉熵损失函数,并且在整个句子上做平均。
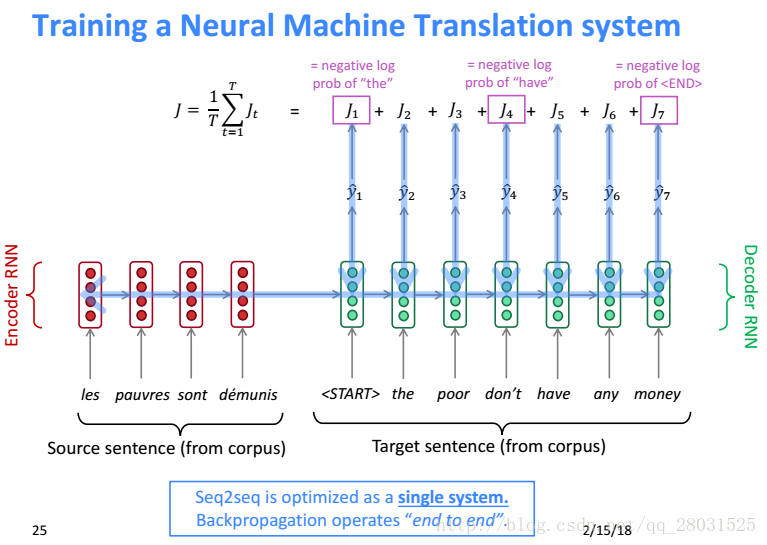
Decode端用Beam Search寻找最佳输出,由于在整个句子上计算复杂度太高,因此分拆为在Decode的每一步计算K个最大值(最有可能的值),但是问题是采用Beam Search不能保证最终选择最优解。

通过以上介绍,可以看到SMT和NMT存在很大的区别,其中NMT的优缺点如下:


Attention
sequene-to-sequence中,在Encoder端的结尾是对整个句子的概述,它需要包含整个句子的信息,但是这时候随着句子的变长,想要包含整个句子的信息往往是很困难的,特别当需要翻译的句子比训练集中的句子还长的时候。
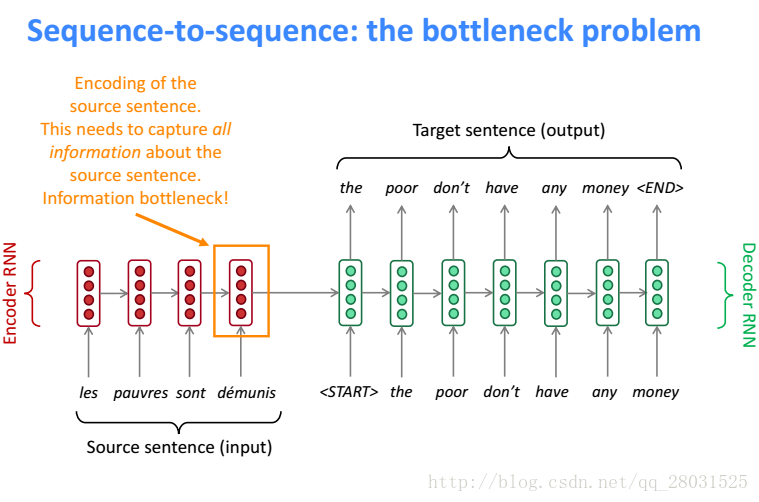
因此Attention采用的方法就是,在Decoder端的每一步,都会选择Encoder端的某一部分组成context vector,然后在输出每一步的结果。(Allowing the model to automatically search for parts of a source sentence that relevant to predicting a target word,without to form these parts as a hard segment explicitly)。

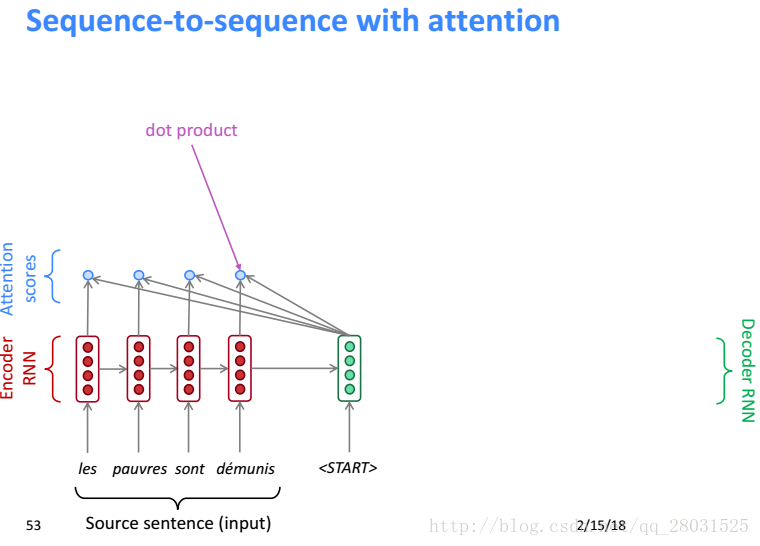
具体的步骤如下
首先利用Decoder端隐藏层和Encoder端每个时刻的隐藏层求内积得到Attention Score(利用内积是一种Vanilla方式,更好的是Bahdanau,下篇博客会介绍),然后利用softmax得到Attention score的概率分布,接着使用Attention distribute对所有的Encoder端的隐藏层加权,这样Attention Output就会包含隐藏层中值得被关注的信息称为context vector,将其和Decode端的隐藏层状态串联(concatenation)作为计算Decode端的输出。
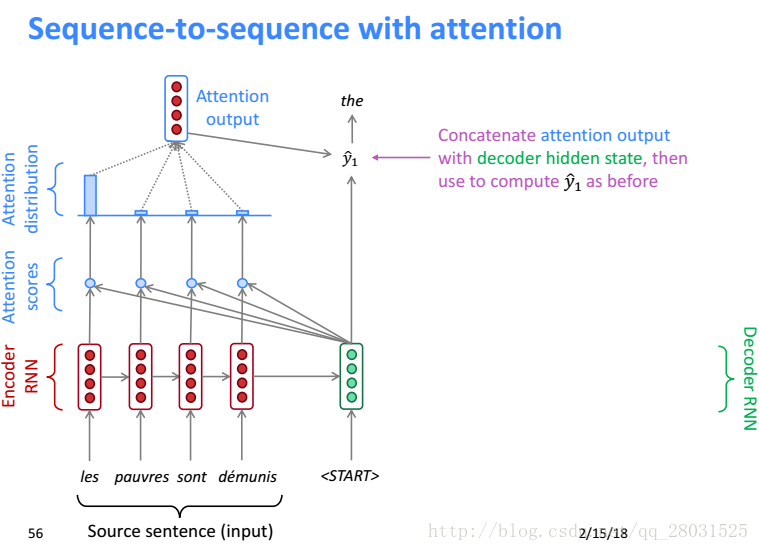
具体从公式角度理解Attention

对于Attention而言,每个时刻的输出都在Encoder端寻找了最有可能的输入,因此可以被认为是内在的发现了生成的翻译和原始语句之间的对应关系,也即Alignment。(Attention provide an intuitive way to inspect the alignment between the words in a generated translation and those in a source sentence.)

Attention Variants
除上述计算的Attention Score方法之外,还有其他的计算方式,使用较多的是Multiplicative attention(Luong)和Additive Attention(Bahdanau)两种,根据论文《Massive Exploration of Neural Machine Translation》4.5节的比较,在其他结构设计相同的情况下,采用Bahdanau的效果会由于Luong,也即下面的第三中计算方式。

Pointer Network(prt network)
未完待续
参考资料
- cs224n:Natural Language Processing with Deep Learning
- Michael Collins NLP课程
- 《Sequence to Sequence Learning with Neural Network》
- 《Massive Exploration of Neural Machine Translation》
- 《Neural Machine Translation by Joint Learning to align and Translate》