自学Python3的日记
学习日记来自于《Python学习手册(第4版)》和 菜鸟教程
关于组建python构建环境和运行,本篇就不讲了!
该学习日记使用的环境和工具为
Python 3.6
JetBrains PyCharm Community Edition 2017.3.3 x64
数据类型
数字
- 类型
有整数型 int、浮点数型 float、 复数型 complex 等…
比如想要用十六进制
num = 0xaff
print(num) #结果为2815- 常用的算数方法
+加
-减
*乘
/除
**乘方
//相除之后向下取整
%求余
print(2 + 1) # 3
print(2 - 1) # 1
print(2 * 1) # 2
print(2 / 1) # 2.0
print(5 / 3) # 1.6666666666666667
print(2 ** 3) # 8 (2*2*2 = 8)
print(14 // 3) # 4 (用/结果为4.666666666666667)
print(14 % 4) # 2 (3*4=12 余2)- 常用数学函数
需要导入相应的math类和random类
| 函数 | 说明 |
|---|---|
| abs(x) | 取整数绝对值 |
| fabs(x) | 取浮点数绝对值 |
| ceil(x) | 小数向上取整 |
| floor(x) | 小数向下取整 |
| max(x1, x2,…) | 取最大值 |
| min(x1, x2,…) | 取最小值 |
| pow(x, y) | 乘方即 x ** y |
| sqrt(x) | 开根 |
| random() | 随即数 0-1 之间 |
import math
import random
print(abs(-5)) # 5
print(math.fabs(-5)) # 5.0
print(math.ceil(10.1)) # 11
print(math.floor(10.9)) # 10
print(max(3,5,12,7)) # 12
print(min(-5,6,0,8)) # -5
print(math.pow(2,3)) # 8.0
print(math.sqrt(3)) # 1.7320508075688772
print(random.random()) # 0.8919291602564556 (0-1之间的随机数 每次都不一样)字符串
- 声明
使用' ' " " """ """都是字符串类型
print('你好') # 你好
print("Python3") # Python3
print("""欢迎使用
字符串""")这边说下当使用""" """是可以直接分行的
print("""欢迎使用
字符串""")
#等于
print("欢迎使用\n字符串")
#或者
print('欢迎使用\n字符串')- 序列操作
在python中字符串是相当于一个数组的
例如
Str = '欢迎来到python3'
print(len(Str)) # 11
print(Str[0]) # 欢
print(Str[8]) # o而且数组的序列可以输入负数
print(Str[-1]) # 3
#等同于
print(Str[len(Str)-1]) # 3还可以截取一段字符串
Str = '欢迎来到python3'
print(Str[:]) # 欢迎来到python3
print(Str[0:4]) # 欢迎来到
print(Str[4:]) # python3
print(Str[:3]) # 欢迎来
print(Str[-1:]) # 3
print(Str[:-5]) # 欢迎来到py关于[:]追加为[::]
Str = '欢迎来到python3'
print(Str[0:4]) # 欢迎来到
print(Str[0:4:1]) # 欢迎来到
print(Str[0:4:2]) # 欢来
print(Str[0:4:3]) # 欢到
print(Str[0:4:4]) # 欢- 拼接字符串
Str = '欢迎来到python3'
print(Str + ' world') # 欢迎来到python3 world
print(Str * 3) # 欢迎来到python3欢迎来到python3欢迎来到python3
print('s' in Str) # False
print('s' not in Str) # True
print(r'\n nihao \t ceshi') # \n nihao \t ceshi
print('\n nihao \t ceshi') # nihao ceshi关于%的拼接方法使用
扫描二维码关注公众号,回复:
1105276 查看本文章

Str = '%s age is %d '
print(Str % ('Zhang',14)) # Zhang age is 14 - 字符串格式
| 符号 | 说明 |
|---|---|
| %c | 字符及其ASCII码 |
| %s | 字符串 |
| %d | 整数 |
| %u | 无符号整型 |
| %o | 无符号八进制数 |
| %x | 无符号十六进制数 |
| %X | 无符号十六进制数(大写) |
| %f | 浮点数字,可指定小数点后的精度 |
| %e | 浮点数 |
| %E | 同%e |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
| %p | 十六进制数格式化变量的地址 |
- 常用函数方法
| 函数 | 说明 |
|---|---|
| len(string) | 返回字符串长度 |
| replace(string,old,new) | 替换字符串,将old转换为new |
| lower() | 转换字符串中所有大写字符为小写 |
| upper() | 转换字符串中的小写字母为大写 |
| find(str, beg=0 end=len(string)) | 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在字符串中会报一个异常. |
| split(str=”“, num=string.count(str)) | num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串 |
| join(seq) | 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| count(str, beg= 0,end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| max(str) | 返回字符串 str 中最大的字母 |
| min(str) | 返回字符串 str 中最小的字母 |
| swapcase() | 将字符串中大写转换为小写,小写转换为大写 |
| capitalize() | 将字符串的第一个字符转换为大写 |
| center(width, fillchar) | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格 |
| startswith(str, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查 |
| endswith(suffix, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False |
| title() | 返回”标题化”的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是8 |
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| isdigit() | 如果字符串只包含数字则返回 True 否则返回 False |
| islower() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| isspace() | 如果字符串中只包含空白,则返回 True,否则返回 False |
| istitle() | 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| isupper() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| ljust(width[, fillchar]) | 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格 |
| maketrans() | 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标 |
| replace(old, new [, max]) | 把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次 |
| rfind(str, beg=0,end=len(string)) | 类似于 find()函数,不过是从右边开始查找 |
| rindex( str, beg=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| rjust(width,[, fillchar]) | 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| lstrip() | 截掉字符串左边的空格或指定字符 |
| rstrip() | 删除字符串字符串末尾的空格 |
| strip([chars]) | 在字符串上执行 lstrip()和 rstrip() |
| splitlines([keepends]) | 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符 |
| translate(table, deletechars=”“) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| zfill (width) | 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| isdecimal() | 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false |
常用的使用
name = 'zhang san'
print(len(name)) # 9
print(name.__len__()) # 9
print(name.count('a')) # 2
print(name.replace('san','si')) # zhang si
print(name.title()) # Zhang San
print(name.upper()) # ZHANG SAN
print(name.lower()) # zhang san
print(name.split(' ')) # ['zhang', 'san']
print(name.find('a')) # 2
print(name.capitalize()) # Zhang san
print(name.center(15,'*')) # ***zhang san***
print(name.startswith('Zhang')) # False
print(name.endswith('san')) # True布尔类型
布尔类型就和其他的编程语言一样true和flase
列表
列表是最常用的Python数据类型 可以不需要设置相同类型的值
- 序列操作
list = ['hello','world',2018]
print(list) # ['hello', 'world', 2018]
print(list[0]) # hello
print(list[1:3]) # ['world', 2018]
print(list[:1]) # ['hello']
list[1] = 'python3'
print(list) # ['hello', 'python3', 2018]- 函数方法操作
| 函数 | 说明 |
|---|---|
| len(list) | 长度 |
| del list[x] | 删除数组中x的值 |
| max(list) | 取最大 |
| min(list) | 取最小 |
| list(seq) | 强转列表 |
| append(obj) | 在列表末尾添加新的对象 |
| count(obj) | 统计某个元素在列表中出现的次数 |
| extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| insert(index, obj) | 将对象插入列表 |
| pop(obj=list[-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| remove(obj) | 移除列表中某个值的第一个匹配项 |
| reverse() | 反向列表中元素 |
| sort([func]) | 对原列表进行排序 |
| clear() | 清空列表 |
| copy() | 复制列表 |
使用如下
list = ['hello','world',2018,111]
list2 = ['你好','世界',2018]
list3 = [1,7,4,9]
del list[3]
print(list) # ['hello', 'world', 2018]
print(len(list)) # 3
list.append('hello')
print(list) # ['hello', 'world', 2018, 'hello']
print(list.count('hello')) # 2
list.extend(list2)
print(list) # ['hello', 'world', 2018, 'hello', '你好', '世界', 2018]
list.insert(1,'123')
print(list) # ['hello', '123', 'world', 2018, 'hello', '你好', '世界', 2018]
list.pop()
print(list) # ['hello', '123', 'world', 2018, 'hello', '你好', '世界']
list3.sort()
print(list3) # [1, 4, 7, 9]
list3.reverse()
print(list3) # [9, 7, 4, 1]
list2 = list.copy()
print(list2) # ['hello', '123', 'world', 2018, 'hello', '你好', '世界']
list3.clear()
print(list3) # []- 列表遍历
正常遍历
list = ['hello','world',2018]
for x in list:
print(x)
#结果如下
hello
world
2018特殊遍历
list = [[1,2,3],[4,5,6],[7,8,9]]
print(list[0]) # [1, 2, 3]
print(list[1][2]) # 6
col = [row[1] for row in list]
print(col) # [2, 5, 8]
col2 = [row[1] + 1 for row in list]
print(col2) # [3, 6, 9]
col3 = [row[1] for row in list if row[1] % 2 == 0]
print(col3) # [2, 8]发现python的列表其实可以直接在for循环的时候加入判断的
以上的3个col其实是
col = [row[1] for row in list]
print(col)
col = []
for row in list:
col.append(row[1])
print(col)
col2 = [row[1] + 1 for row in list]
print(col2)
col2 = []
for row in list:
col2.append(row[1] + 1)
print(col2)
col3 = [row[1] for row in list if row[1] % 2 == 0]
print(col3)
col3 = []
for row in list:
if row[1] % 2 == 0:
col3.append(row[1])
print(col3)结果是一模一样的
字典
字典是另一种可变容器模型,且可存储任意类型对象
有点像java中的Map 又不需要设置相同的类型作为键值对
- 映射操作
dict = {1:'hello' , 3:'world' , '你好':2018}
print(dict) # {1: 'hello', 3: 'world', '你好': 2018}
print(dict[1]) # hello
print(dict[3]) # world
print(dict['你好']) # 2018
dict[3] = 'python3'
print(dict) # {1: 'hello', 3: 'python3', '你好': 2018}
dict = {}
dict[1] = 2018
dict[2] = 2020
dict[3] = 2200
print(dict) # {1: 2018, 2: 2020, 3: 2200}
del dict[2]
print(dict) # {1: 2018, 3: 2200}
dict.clear()
print(dict) # {}
del dict
print(dict) # <class 'dict'>- 多重嵌套
dict = {}
dict['name'] = 'zhang san'
dict['age'] = 17
dict['phone'] = [180123456789,177123456789]
print(dict) # {'name': 'zhang san', 'age': 17, 'phone': [180123456789, 177123456789]}
- 函数方法操作
| 函数 | 说明 |
|---|---|
| len(dict) | 计算字典元素个数,即键的总数 |
| str(dict) | 输出字典,以可打印的字符串表示 |
| clear() | 删除字典内所有元素 |
| copy() | 返回一个字典的浅复制 |
| fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| items() | 以列表返回可遍历的(键, 值) 元组数组 |
| keys() | 以列表返回一个字典所有的键 |
| setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| update(dict2) | 把字典dict2的键/值对更新到dict里 |
| values() | 以列表返回字典中的所有值 |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值 |
| popitem() | 随机返回并删除字典中的一对键和值(一般删除末尾对) |
dict = {}
dict[1] = 2018
dict[2] = '你好'
dict[3] = 'python3'
dict2 = {}
dict2[2] = "hello"
dict2['test'] = 123
print(len(dict)) # 3
dict3 ={}
print(dict3.fromkeys((5,6),)) # {5: None, 6: None}
print(dict3.fromkeys((5,6),'ss')) # {5: 'ss', 6: 'ss'}
print(dict3.fromkeys((5,6),[11,22])) # {5: [11, 22], 6: [11, 22]}
print(dict.get(1)) # 2018
print(dict.items()) # dict_items([(1, 2018), (2, '你好'), (3, 'python3')])
print(dict.keys()) # dict_keys([1, 2, 3])
print(dict.values()) # dict_values([2018, '你好', 'python3'])
print(dict.setdefault(2)) # 你好
print(dict.setdefault(4,'test')) # test
dict.update(dict2)
print(dict) # {1: 2018, 2: 'hello', 3: 'python3', 4: 'test', 'test': 123}
print(dict2) # {2: 'hello', 'test': 123}
dict.pop('test')
print(dict) # {1: 2018, 2: 'hello', 3: 'python3', 4: 'test'}
dict.popitem()
print(dict) # {1: 2018, 2: 'hello', 3: 'python3'}- 字典的循环
dict = {
'北京':
{
'朝阳': ['朝阳A', '朝阳B', '朝阳C', '朝阳D', '朝阳F'],
'海淀': ['海淀A', '海淀B', '海淀C', '海淀D'],
'昌平': ['昌平A', '昌平B', '昌平C', ]
},
'河北':
{
'石家庄': ['石家庄A', '石家庄B', '石家庄C', '石家庄D', '石家庄E'],
'张家口': ['张家口A', '张家口B', '张家口C'],
}
}
for x in dict:
print(x)
# 北京
# 河北
for x in dict['北京']:
print(x)
# 朝阳
# 海淀
# 昌平
for x in dict['北京']['昌平']:
print(x)
# 昌平A
# 昌平B
# 昌平C元组
元组与列表类似,不同之处在于元组的元素不能修改
- 序列操作
T = (1,2,4,6,6)
print(T) # (1, 2, 4, 6, 6)
Y = '11', 23, 89
print(Y) # ('11', 23, 89)
T = T + (['s','t','r'],'hello')
print(T) # (1, 2, 4, 6, 6, ['s', 't', 'r'], 'hello')
#检索值索引
print(T.index(6)) # 3
print(T.index('hello')) # 6
#计算出现的次数
print(T.count(6)) # 2
print(T.count(3)) # 0
print(T.count(1)) # 1- 函数方法
| 函数 | 说明 |
|---|---|
| len(tuple) | 计算元组元素个数 |
| tuple(seq) | 将列表转换为元组 |
list = [1,'2',3]
T = tuple(list)
print(list) # [1, '2', 3]
print(len(T)) # 3
print(T) # (1, '2', 3)
文件
详细的os操作 Python3 OS 文件/目录方法
- 基本操作
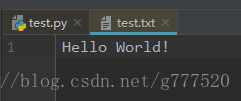
f = open('test.txt', 'w')
f.write('Hello ')
f.write('World!')
f.close()
f = open('test.txt')
t = f.read()
print(t) # Hello World!
print(t.split()) # ['Hello', 'World!']这将会在和python同级目录下如果没有test.txt就创建一个在写入
- 函数方法
| 函数 | 说明 |
|---|---|
| close() | 关闭文件。关闭后文件不能再进行读写操作 |
| flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入 |
| fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上 |
| isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False |
| next() | 返回文件下一行 |
| read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有 |
| readline([size]) | 读取整行,包括 “\n” 字符 |
| readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区 |
| seek(offset[, whence]) | 设置文件当前位置 |
| tell() | 返回文件当前位置 |
| truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后 V 后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小 |
| write(str) | 将字符串写入文件,没有返回值 |
| writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符 |
用户自定义类
自定义一个类也是使用class
class Worker:
def __init__(self,name,age):
self.name = name
self.age = age
def firstName(self):
return self.name.split(' ')[0]
def lastName(self):
return self.name.split(' ')[-1]
ZhangSan = Worker('Zhang San',17)
LiSi = Worker('Li Si',24)
print(ZhangSan.firstName()) # Zhang
print(ZhangSan.lastName()) # San
print(ZhangSan.name) # Zhang San
print(ZhangSan.age) # 17
print(LiSi.name) # Li Si
print(LiSi.age) # 24