检索: 文本匹配
搜索: 基于对查询的真实语义理解以及上下文、位置、时间、用户的先前短期和长期浏览活动来获得搜索结果。
Query分析
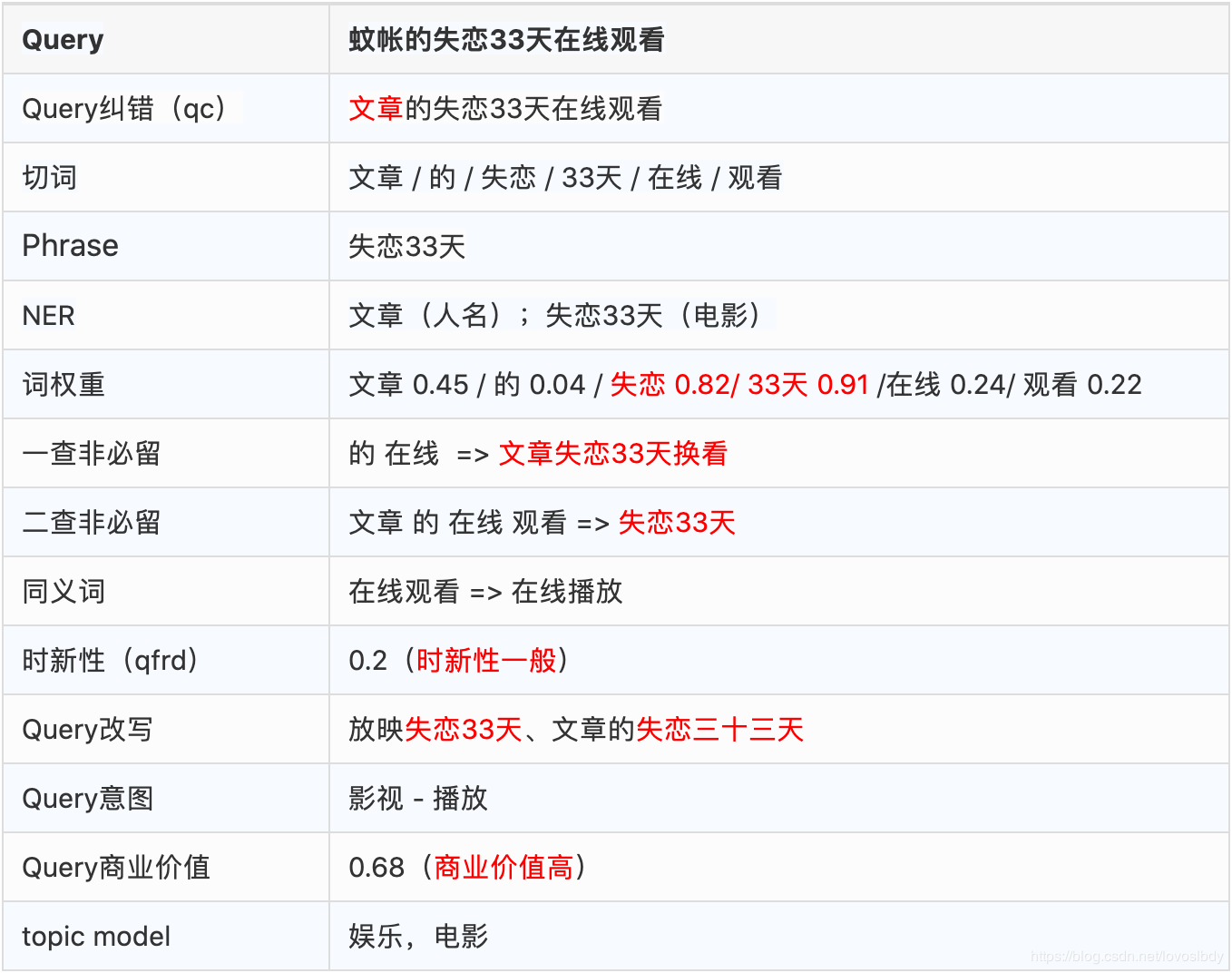

Query切分
别名库
分词(新词发现)
命名实体识别
Query意图识别
直接使用query进行查询可能导致结果与用户预期不一致。
用户query的预期结果不完全体现在term的匹配上。比如用户搜索“北京到上海的火车票”,doc“北京到上海的火车票的乘车体验”,虽然query完全紧邻命中doc,但用户要找的是火车票购买,并不是该doc。
用户query是包含歧义的。当用户搜索苹果时,是要找水果还是要找苹果手机?
所以
词表穷举法
规则解析法
机器学习方法
Query处理
query处理主要是为了解决下一阶段召回问题。直接使用用户Query查询可能导致召回结果与用户预期不一致等问题。
query纠错
规则法:采用一些人为定义的规则进行错误的查找和纠正。可以利用"错误/正确词典",拼音特征等进行纠错
统计法:采用语言模型(LM)计算字词出现概率的方法。依赖大规模无监督语料计算语言模型,优点是无需人工标注,缺点是准确率可能不尽如人意。
机器学习方法:使用人工标注的数据进行训练和纠正。依赖数据。
query丢弃
query中包含过多的无关term会导致召回doc数量很少。
query扩展
短query的召回很多,但是可能并不能解决用户的需求。另外也为了提高系统搜索结果的多样性。
query改写
用户Query可能与Doc的描述不一致,因此将query改写为doc标准。
同义词替换。
在传统搜索里,一个 query 进来需要做多个子任务的处理。假如每个任务只能做到90%,那么积累起来的损失会非常大。我们需要一个方法一次性完成多个任务去减小损失,比如把 “苹果手机价格多少” 直接改写为 “苹果手机售价”。
query词语权重:
基于语料统计 IDF IMP,DIMP
基于点击日志
基于模型学习
召回
1.基于倒排索引求交得到候选集
TF-IDF BM25
分解模型: 将doc和query映射到同一低维空间
转换模型: 将doc映射到query空间,然后做匹配
索引粒度 当以词为粒度,粒度较细,召回的文章的数目较多,可能把部分结果截断;当以更大的phrase粒度,粒度较粗,召回的文章相对更相关,但也容易造成召回的结果过少。
保证有一定的召回文章数
结果的多样性 尤其是对于短query,短query往往是一些实体,召回doc数往往不是用户关心的问题,另外用户也希望有一些惊喜的结果,避免搜索结构都是一些类似或重复结果。
2.基于embedding的方法
representation-based 学习出query和doc的语义向量表示,然后用两个向量做简单的cosine(或者接MLP也可以),重点是学习语义表示(representation learning)
重点是学习文本的句子表示;可以提前把文本的语义向量计算好,在线预测时,不用实时计算。
在学习出句子向量之前,两者没有任何交互,细粒度的匹配信号丢失。学习出来的向量可能是两个不同向量空间的东西,通过上层的融合层和loss,强制性的拉近两个向量。
**interaction based **不直接学习query和doc的语义表示向量,而是在底层,就让query和doc提前交互,建立一些基础的匹配信号(例如term和term层面的匹配),再想办法把这些基础的匹配信号融合成一个匹配分。
有细粒度、精细化的匹配信号,上层进行更大粒度的匹配模式的提取;可解释性好
在线计算代价大。
Query-Document Relevance Matching
Based on global distribution of matching strengths,基于全局的匹配信号。对于query中的每个term,直接求解它和整个文档的匹配信号。
Based on local context of matched terms,基于局部的term级别的匹配信号。对于query中的每个term:1.找出它要匹配的doc的局部上下文 2.匹配query和doc的局部上下文 3.累计每一个term的匹配信号
排序
文本相似度计算
编辑距离
向量空间模型(TF-IFDF)
LDA主题模型
simhash(文本长度较长)
基于词语向量的方法:
词向量平均。
词移距离。两文本之间的词移距离指的是文本一种中所有单词与文本二中的单词之间最小累计距离
SIF算法。 根据加权平均(用α和词频的运算,频率越高,权重越低,抑制高频率词)得到初步句子向量,之后减去所有句子向量的共性(表现为句子向量-句子向量在主成分上的投影),增强句子向量的独立性,增强鲁棒性.
预训练编码器。预训练句子编码器以来自然语言推理等任务,来学习句子嵌入,以便用于今后的迁移任务。
排序学习
CTR点击率预测
lR+特征
————————————————
原文:https://blog.csdn.net/lovoslbdy/article/details/104860662