1、 赛题背景
日常生活中人们需要阅读大量的文本。很多情况下我们只需要从文本中查找某一些片段来解决我们的问题,这是并不需要阅读整篇文章。因此我们希望智能阅读技术能够在这方面提供一些帮助。
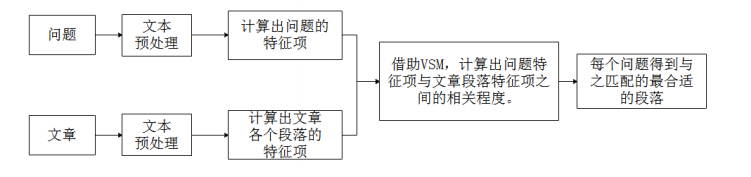
2、 系统流程图初步设计
3、面试问题
3.1 简单介绍一下文本预处理

文本预处理主要包括三个步骤:分词、停用词过滤以及词频统计。
首先是分词。分词即依据中文词汇表将各个词语单独提炼出来。例如将“我们在教室学习”分为“我们/在/教室/学习”四个词汇。我的项目采用的是机械分词法,利用jieba包对文本数据进行分词。原理就是将文本中相邻的字与包中的词语一一匹配,若有相同的词存在则进行分词。
然后是停用词过滤。停用词仅在文本结构上起着词汇联系的作用,如文本中的“了”、“的”、“然后”、“虽然”等。这类词汇在文本中有着较高的出现频率,但对于文本的语义表达没有任何贡献。对停用词进行过滤处理能有效减少噪音,提高文本挖掘的效果。我的项目用的是哈尔滨工业大学扩展停用词库表。
最后是词频统计。词频指的是单词在一篇文档中出现的频率,通过词频统计可以筛选出一些分词错误的词语,这类词语一般为较低词频的词。

3.2 如何计算出问题的特征项或者如何计算出文章的各个段落的特征项?
计算问题的特征项:
假定用户一次性输入一个问题到我设计的文本检索模型中。首先我用TF-IDF来计算问题中的每个词的特征值。然后大概设定一个阈值A,将特征值大于此阈值的若干词定为该词所在问题的特征项。小于此阈值的特征值置0。
计算文章的各个段落的特征项:
首先我用TF-IDF来计算段落中的每个词的特征值。然后大概设定一个阈值B,将特征值大于此阈值的若干词定为该词所在段落的特征项。小于此阈值的特征值置0。
3.3 上面提到的阈值怎么修正?
结合问题与段落的匹配结果,对两种阈值进行修正,然后进行多次试验,直至取到最好的匹配结果。
3.4 上面提到“假定用户一次性输入一个问题”,倘若用户一次输入若干个问题怎么办?可以得到结果吗?
同样可以得到结果。
3.5 TF-IDF是什么?
TF-IDF是一种统计方法,叫做词频-逆文档频率,可以用来评估一个词对一篇文章中的其中一份段落的重要程度。根据TF-IDF所得的特征值将随一个词在该词所在段落中出现的频率上升,随这个词在文章的其他段落中出现的频率下降。简单来说就是,如果某个词在整篇文章中比较少见,但是这个词在A段落中多次出现,那么这个词很可能就反应了A段落的特性。
TF-IDF的计算公式为词频乘以逆文档频率。其中,词频等于某个词在段落中出现的次数除以该段落的总词数。逆文档频率等于文章的段落总数除以包含该词的段落数。
举个例子:假如一个段落的总词数是100,而词语“家”出现了30次,那么“家”在该段落的词频就是0.3(30/100)。如果“家”这个词在整篇文章中的4个段落中出现过,而文章段落总数是10的话,“家”的逆文档频率就等于2.5(10/4)。所以“家”一词在该段落TF-IDF值,也即特征值为0.75(0.3*2.5)。
3.6 怎么计算问题特征项和文章段落特征项的相关程度?
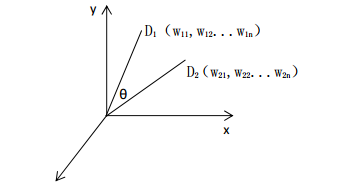
根据VSM,即空间向量模型,来计算问题特征项和文章段落特征项的相关程度。
首先定义一个二维矩阵,矩阵的行由文章的所有段落以及用户输入的若干个问题组成,矩阵的列由文章的所有词以及用户输入的所有词组成。然后将计算出的问题以及文章的各个段落的词的特征值填入矩阵中。然后分别计算各个问题的行向量和文章的各个段落的行向量的余弦值。此余弦值就代表了问题特征项和文章段落特征项的相关程度。

如果两个向量的关系越接近,则他们的余弦值就越大,也就代表问题和段落的相关程度越高。
3.7 最后如何得到匹配结果?
举例来说。有一个用户输入问题A,首先计算出文章的所有段落和这个问题A的相关程度,然后根据相关程度把文章的段落降序排列,此时排名越高说明这个段落和这个问题的相关程度越大。也即最佳的匹配结果有大概率出现在排位高的段落中。这就实现了文本检索模型的功能。

3.8 还有一些其他面试问题,请参照如下网址
https://blog.csdn.net/mahoon411/article/details/106109671
