一、损失函数、代价函数和目标函数
- 损失函数:单个样本误差
- 代价函数:所有样本误差平均值
- 目标函数:代价函数+正则项
二、各模型的损失函数
1.线性回归:平方损失函数
误差符合正态分布
利用“最小二乘法”使点到线的距离和最短
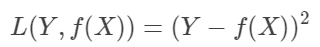
2.逻辑回归:对数损失函数
极大似然估计的思想
误差符合sigmoid伯努利分布
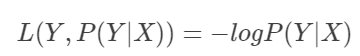
其中yi表示正样本的概率
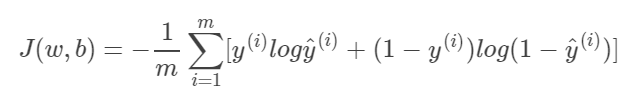
softmax损失函数是逻辑回归损失函数的一种推广(误差服从指数分布)
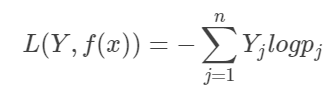
3.SVM:Hinge损失函数
- 当分类正确时,不惩罚(t≥1)
- 当分类不完全正确时,进行部分惩罚(0<t<1)
- 主要集中分类错误部分,(t<0)
- 从而极大化分类间隔
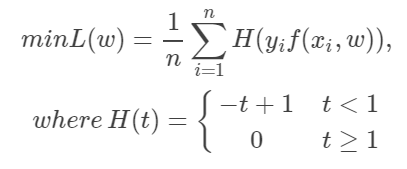
4.Adaboost:指数损失函数
yi使标签值,取值范围是(-1,1)
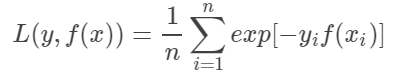
5.感知机
(1)优点:稳定的分类面
(2)缺点:二阶不可导,有时候不存在唯一解
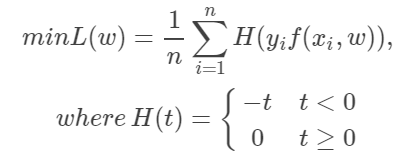
6.决策树

-
∣T∣:误差大小
-
α:模型的复杂度,用叶节点数目表示,防止过拟化
-
Ht(T)表示叶子节点t的熵的期望,决策树的叶子节点集合为T
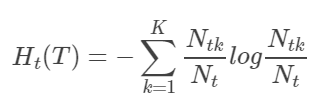
-
t叶子节点总的熵是Nt*Ht(T)
