安装:
1、pip install wheel 安装wheel
2、安装Twisted
a.访问 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载Twisted-17.9.0-cp36-cp36m-win_amd64.whl
b.进入文件所在目录 pip install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3、pip3 install scrapy 安装scrapy
使用:
1、scrapy startprojec 项目名称 创建项目
2、 cd 项目名称 进入项目目录
3、scrapy genspider xxx xxx.com 创建爬虫文件 例如,要创建oppo爬虫文件,则scrapy genspider oppo www.oppo.cn
4、scrapy crawl xxx 运行爬虫文件 在当前目录下,运行oppo爬虫 scrapy crawl oppo
5、scrapy crawl xxx -o file.json 运行爬虫,并把文件存放到指定文件中,多用来调试!
注意事项:去settings .py 中注释掉 ROBOTSTXT_OBEY = True (如项目无其他侵权功能,则可以注释“鉴别是否允许爬取”)
域名有www 则需要加上www, 如果当前页面添加ssl加密传输,则需要去oppo.py中修改http为https
调试方法:
scrapy shell 域名
scrapy shell -s USER_AGENT="Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" 域名 注意: 调试中增加请求头,USER_AGENT=后面必须是英文状态下的双引号,单引号会报错
scrapy shell https://www.oppo.cn
scrapy shell https://www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856
域名后面&换行后无法连接成整个域名,则可: scrapy shell "www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856" 去掉"https://"
CSS选择器使用
response.css("#ID dt::text") 提取文本信息
response.css('.class p::attr(href)').extract() 提取属性信息 显示所有
response.css('.class p::attr(href)').extract_first() 提取属性信息 显示第一条
Spider 注意事项:
allowed_domains = ['qiushibaike.com'] 这是正确匹配规则,
错误示范:
1 、allowed_domains = ['www.qiushibaike.com'] 主域名前面添加 www
2 、allowed_domains = ['qiushibaike.com/text'] 主域名后面添加多余页码
创建crawl_spider
1、scrapy startproject 项目名称
2、cd 项目名称
3、scrapy genspider xxx -t crawl xxx '域名'
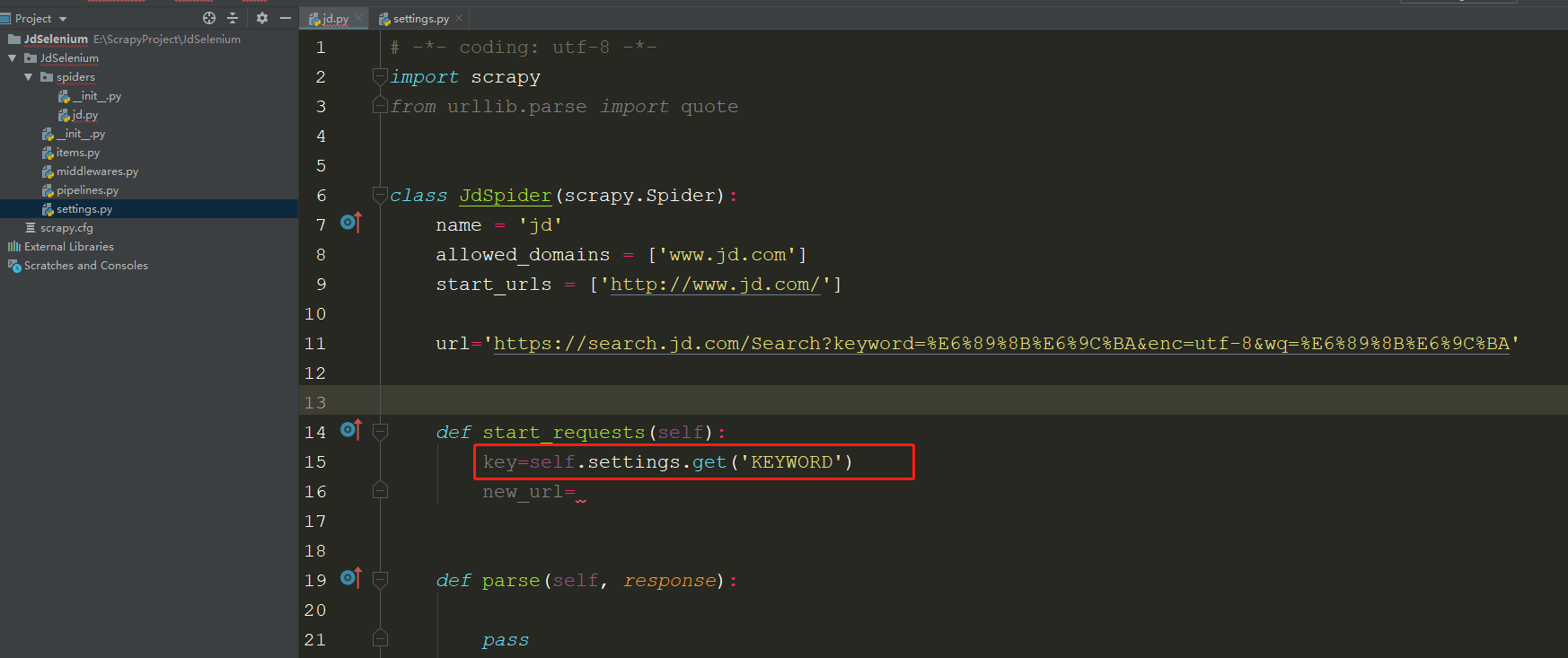
关于settings调用到方法:
在spider.py文件中,可以直接使用 self.settings.get('XXX') 获取