Scrapy框架
Scrapy之所以是框架,而不是一个简单的库,区别就是它相比于普通的库有着更加强大的功能,而其中最常用的几个功能就是链接提取器(LinkExtractors)、自动登录和图片下载器。
链接提取器(LinkExtractors)
携带链接提取器的爬虫生成和我们常规的爬虫生成有所不同,需要多携带一些参数。
scrapy genspider -t crawl 爬虫名字 域名
如果你觉得每次创建和启动爬虫都比较麻烦,你可以像我一样建一个.py文件用来启动和创建爬虫

from scrapy import cmdline
class RunItem:
def __init__(self, name, url=None):
# 爬虫名字
self.name = name
# 域名
self.url = url
# 启动爬虫
def start_item(self):
command = ['scrapy', 'crawl', self.name]
print('爬虫已启动')
cmdline.execute(command)
# 新建爬虫
def new_item(self, auto_page=False):
# 创建自动翻页爬虫(此爬虫会自动提取网页中的连接)
if auto_page:
command = ['scrapy', 'genspider', '-t', 'crawl', self.name, self.url]
cmdline.execute(command)
# 创建正常爬虫
else:
command = ['scrapy', 'genspider', self.name, self.url]
cmdline.execute(command)
使用我上方的类即可,你也可以自己写一个更适合自己的。
这时候比如我像创建一个爬取阳光问政官网,带链接提取器的爬虫,只需要执行RunItem('yg', 'wz.sun0769.com').new_item(True)即可。
创建好后,我们发现携带链接提取器的爬虫与普通爬虫不同的地方有两处,一处是多了一个rules
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
另一处则是我们的方法从parse变成了parse_item。
注意: 我们使用携带链接提取器的爬虫不能创建def parse(self):方法,因为这个方法被用来写链接提取器了,如果使用会将链接提取器覆盖,导致无法自动提取链接。 除非你想重写链接提取器。
Rule与LinkExtractor
rules规定,从网站中提取那些有用的链接(LinkExtractor),并在提取后执行那些操作(Rule)。我们可以创建多个规则,让每个链接有不同的操作。
下面我们来简单介绍一下Rule与LinkExtractor中都有那些常用的属性
- 自动提取连接规则:
Rule(连接提取器, [callback,follow,process_links])- callback: 满足此条件的url回调的函数
- follow: 是否开启循环提取(从提取的页面中在此提取满足条件的网址)
- process_links: 从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
- 除了上述常用的之外,还有:cb_kwargs, process_request, errback。
- 连接提取器:
LinkExtractor()- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
- 除上述常用属性外还有:tags, attrs, canonicalize, unique, process_value, deny_extensions, restrict_css, strip, restrict_text
实战演示
Scrapy链接提取器有个很好用的地方就是我们通过控制台,可以看到这个网站的跳转链接并非是完整的链接,但我们的链接提取器会自动将其补全,变成完整的链接后在进行筛选!
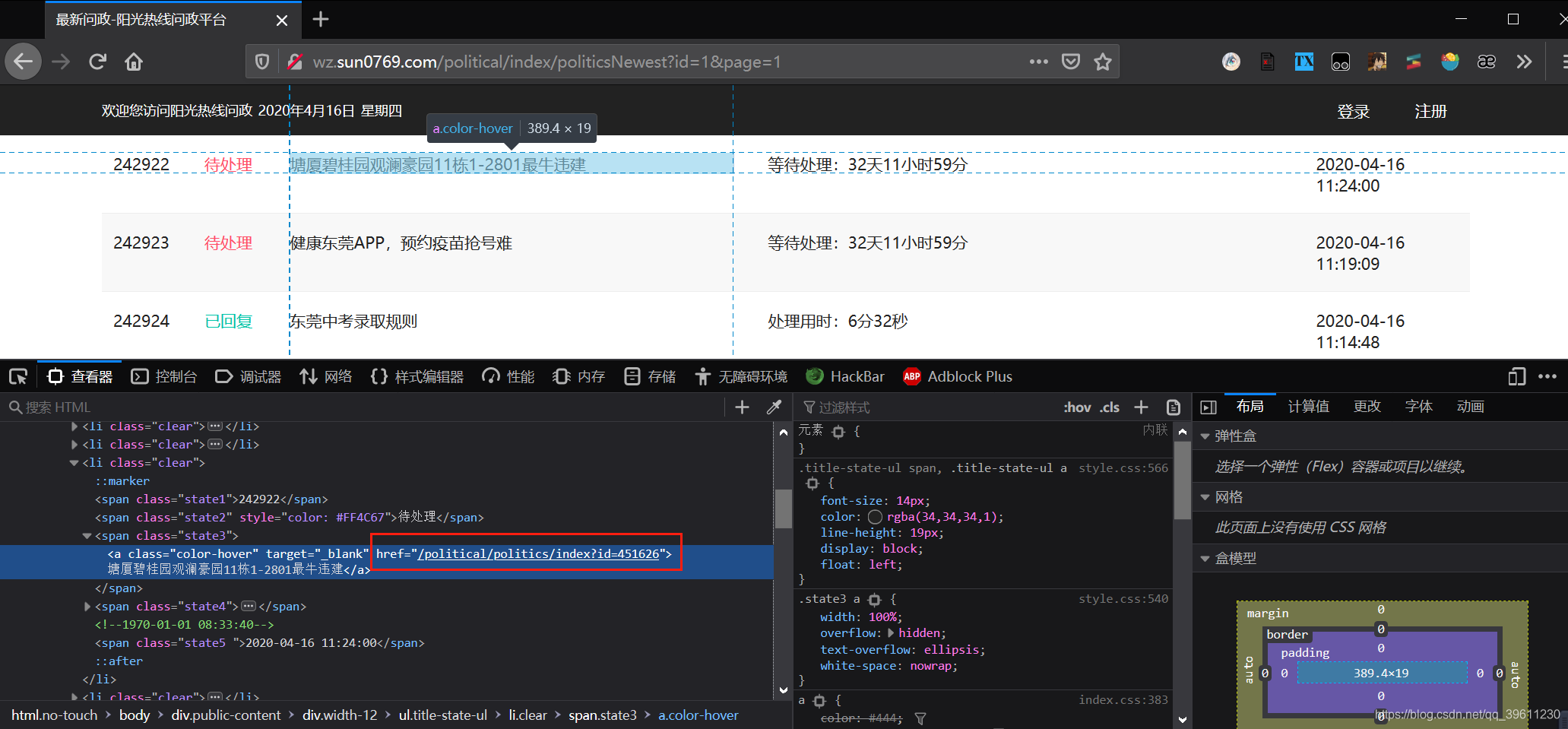
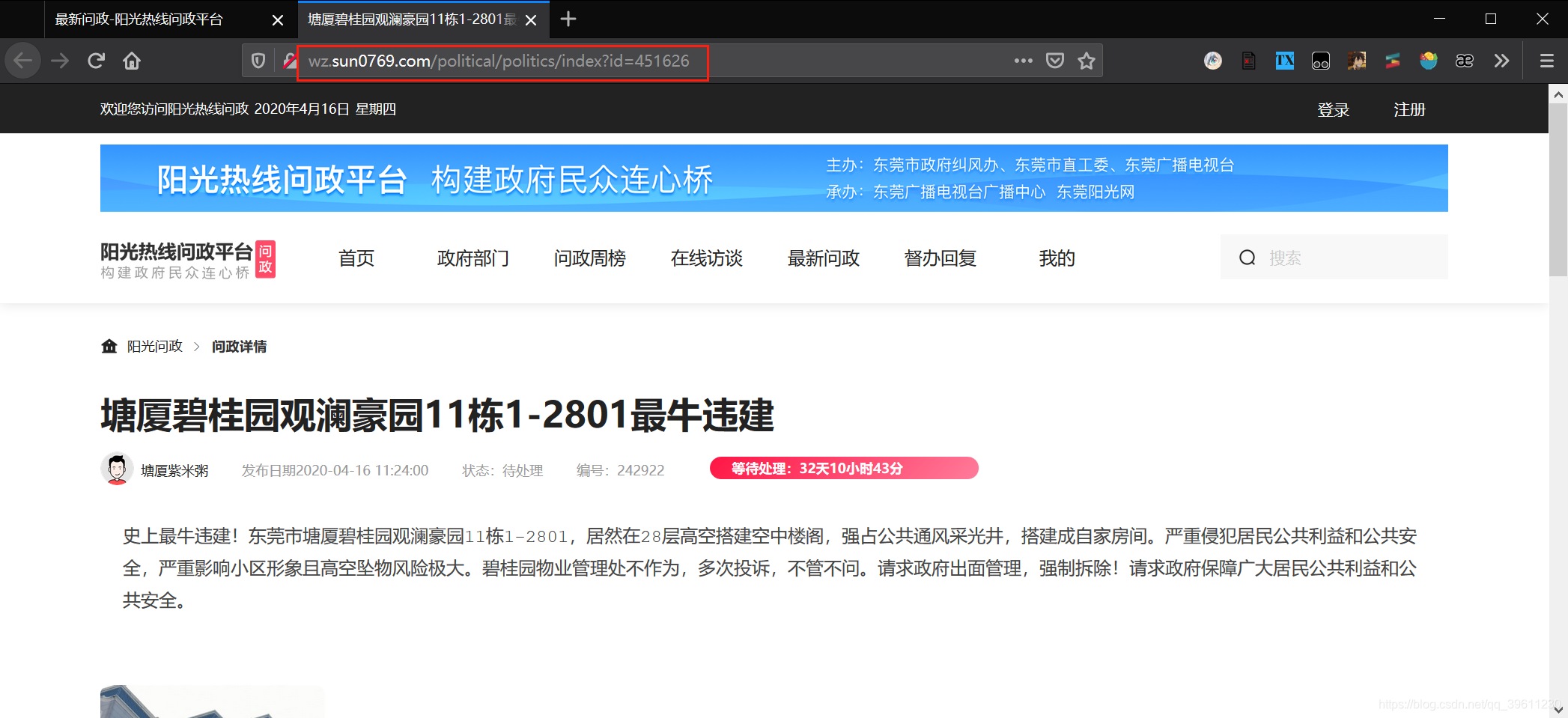
也就是我们放入链接提取器用于规则筛选的链接基于如下链接http://wz.sun0769.com/political/politics/index?id=451626进行改写就可以,打开多个页面,我们发现,只有id号会发生改变,那么我们只需在id出给\d+(正则中\d表示数字+表示一个以上,连起来就是’一个以上的数字’)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_text.items import Scrapy阳光问政Item
class YgSpider(CrawlSpider):
name = 'yg'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
rules = (
# 翻页链接提取(follow:用于重复提取,从提取的新页面中继续寻找符合当前要求的页面)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/index/politicsNewest\?id=1&page=\d+'), follow=True),
# 详情链接提取(callback:将提取到的详情页面传入parse_item方法进行处理)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/politics/index\?id=\d+'), callback='parse_item'),
)
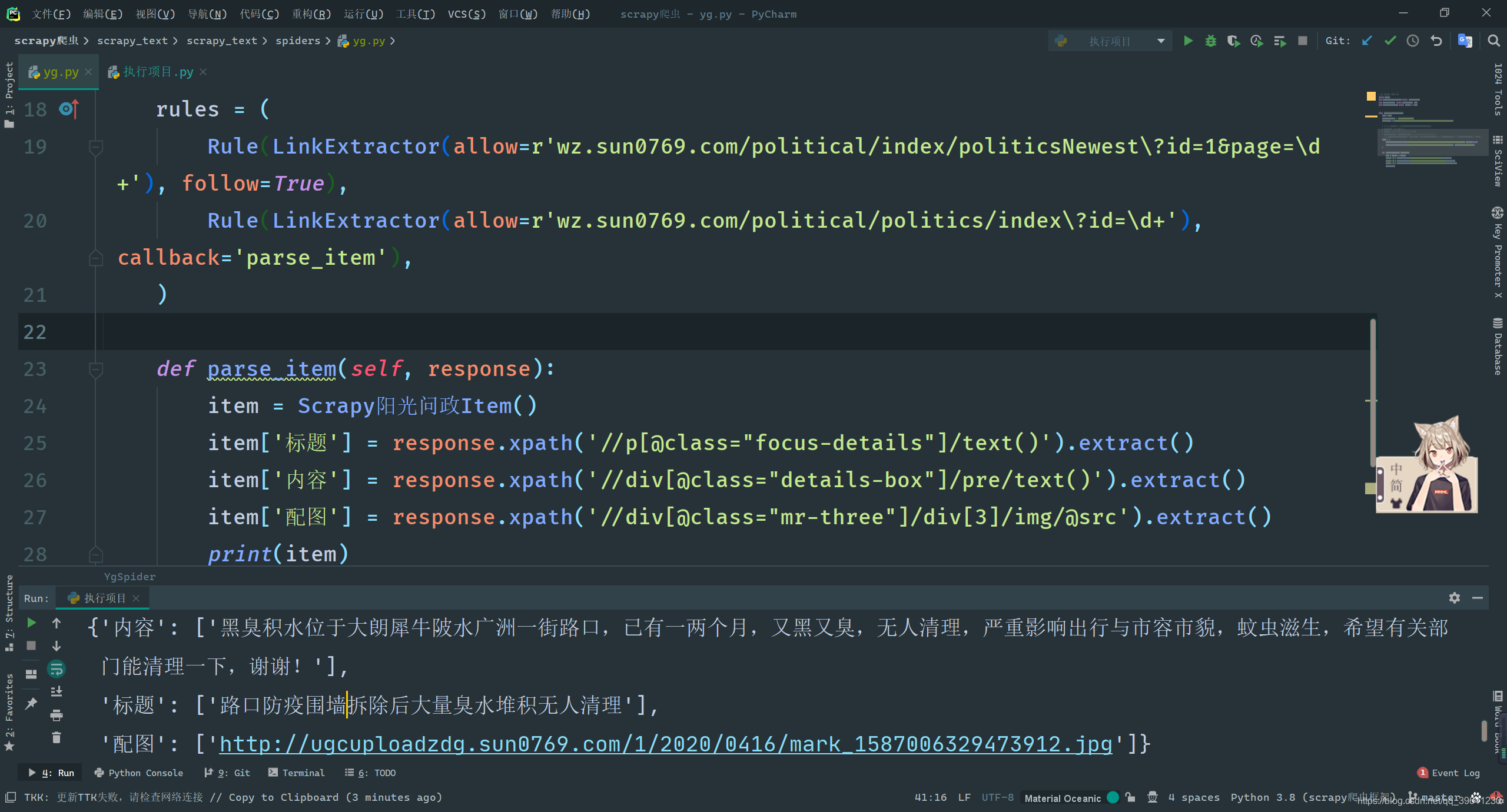
def parse_item(self, response):
item = Scrapy阳光问政Item()
item['标题'] = response.xpath('//p[@class="focus-details"]/text()').extract()
item['内容'] = response.xpath('//div[@class="details-box"]/pre/text()').extract()
item['配图'] = response.xpath('//div[@class="mr-three"]/div[3]/img/@src').extract()
print(item)
自动登录
常规request要实现网站登录,有两种方法,一种是找到用户登录的提交表单,模拟用户提交进行登录,而另一种则是携带已登录的cookie。
这两种方式Scrapy都可以使用,但除此之外,scrapy还可以自动寻找可能的登录框,我们输入账号密码后可以自动提交并且登录。下面我们就来用steam(https://steamcommunity.com/)登录页面,演示一下几种登录方式。
以防发生意外,我们先改一下请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.2,en;q=0.1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'
}
旧方法-携带cookie登录和模拟提交登录表单
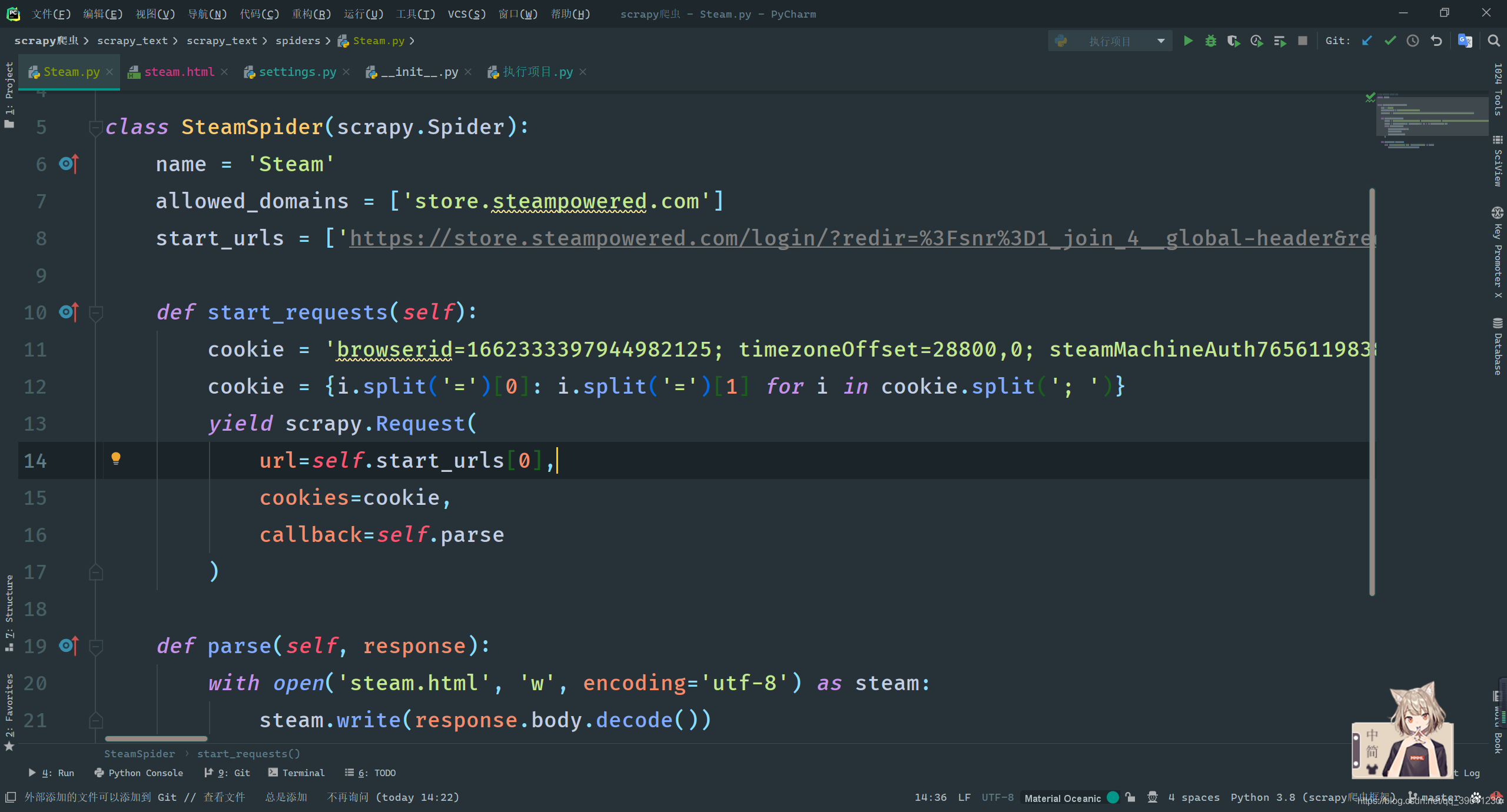
当前我们想要实现,对首个url页面发起请求的时候带上cookie登录,但是scrapy会自动对首个url发起请求,而这个请求时调用了staet_request()方法, 也就是说我们只要重写此方法就能达到携带cookie登录。
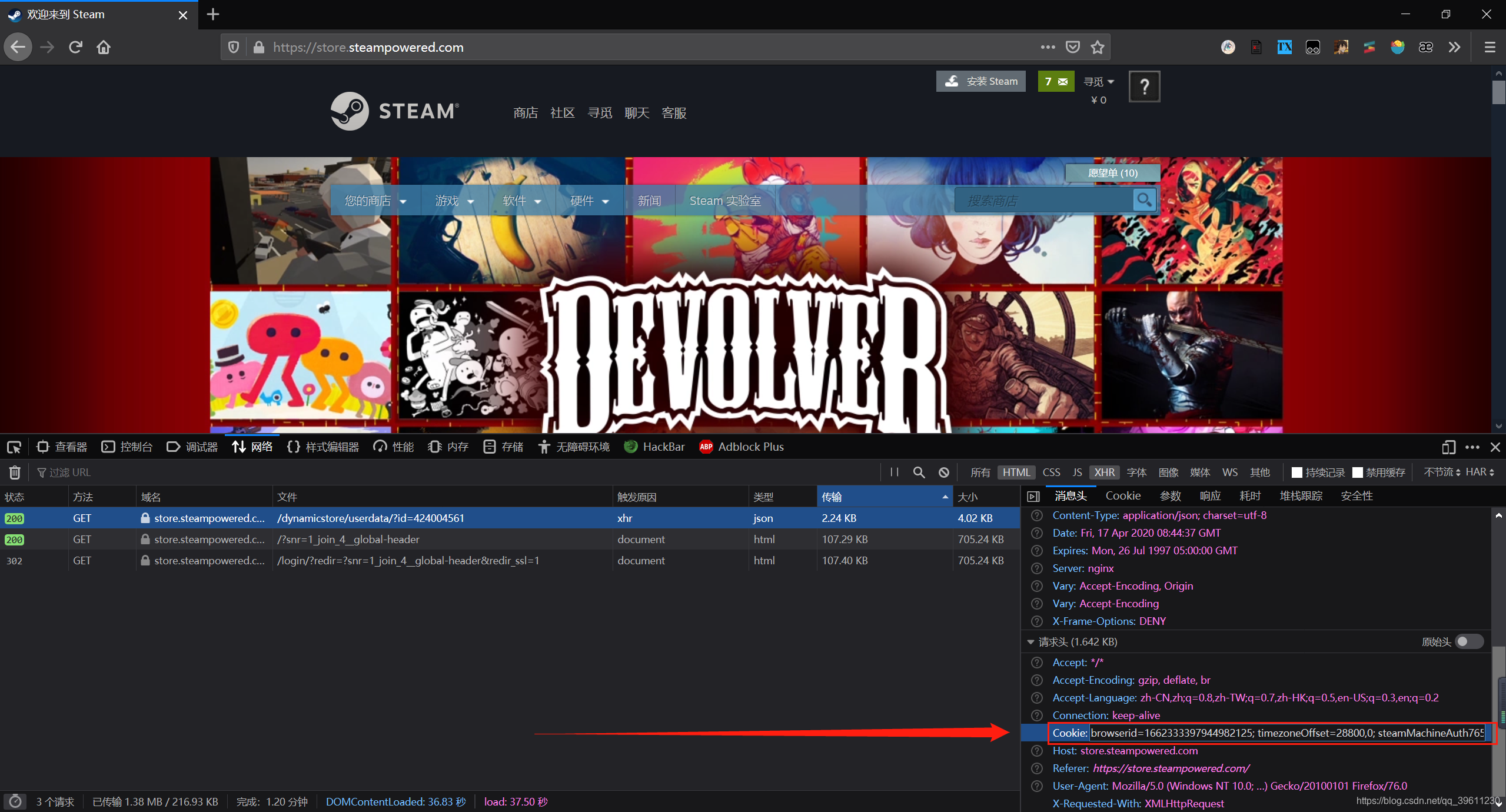
cookie直接复制此处的即可,无需任何处理cookie = {i.split('=')[0]: i.split('=')[1] for i in cookie.split('; ')}下列代码的此处会将cookie自动转化为需要的字典形式
# -*- coding: utf-8 -*-
import scrapy
class SteamSpider(scrapy.Spider):
name = 'Steam'
allowed_domains = ['store.steampowered.com']
start_urls = ['https://store.steampowered.com/login/?redir=%3Fsnr%3D1_join_4__global-header&redir_ssl=1']
def start_requests(self):
cookie = '把你的cookie复制到这里'
cookie = {i.split('=')[0]: i.split('=')[1] for i in cookie.split('; ')}
yield scrapy.Request(
url=self.start_urls[0],
cookies=cookie,
callback=self.parse
)
def parse(self, response):
with open('steam.html', 'w', encoding='utf-8') as steam:
steam.write(response.body.decode())
模拟提交登录表单思路就是先找到from表单,在根据信息进行提交。下面使用github来进行模拟。通过观察,我们发现提交表单的时候不仅要提交账号密码,还需要提交时间戳和秘钥等一些东西。
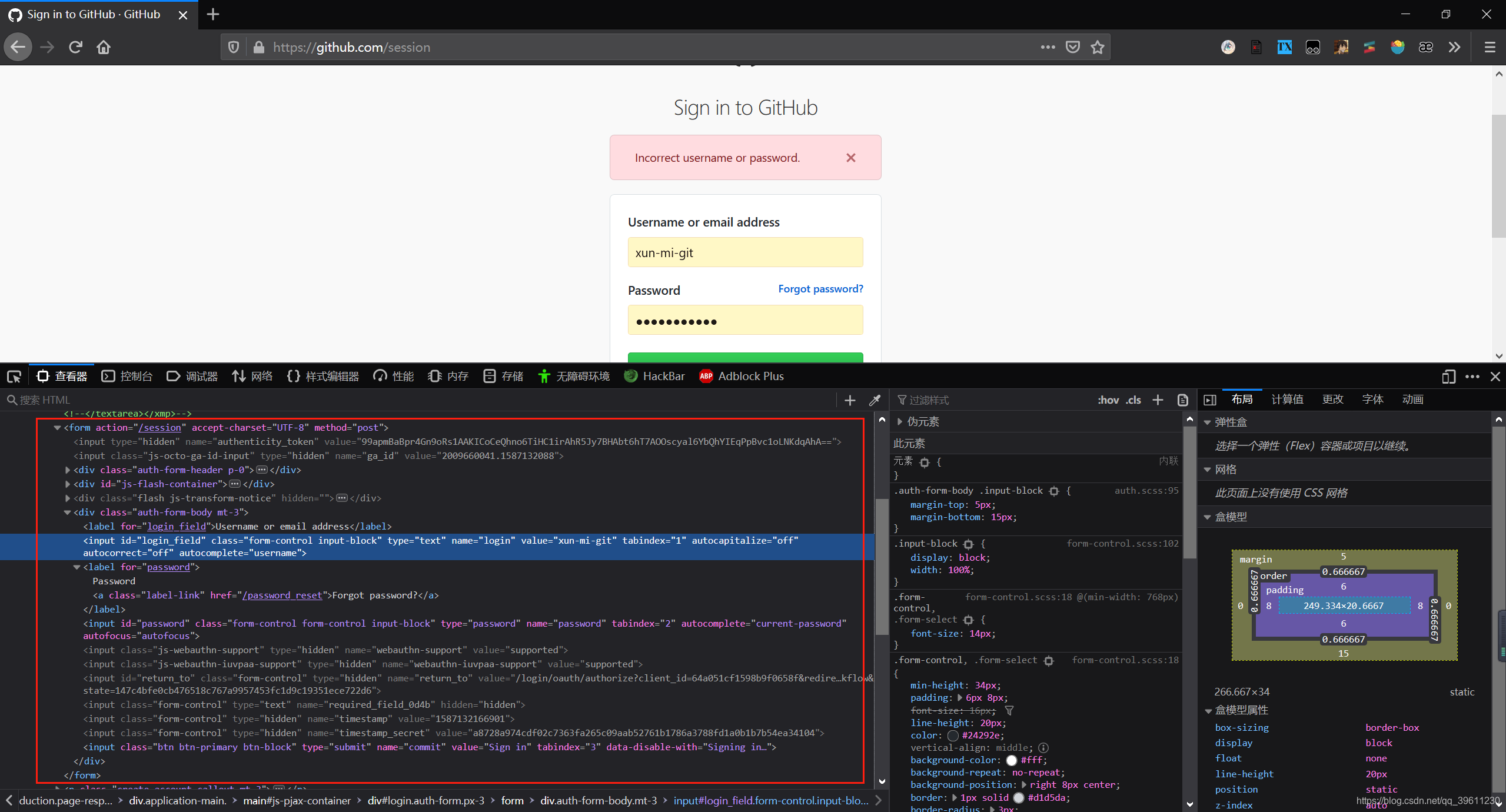
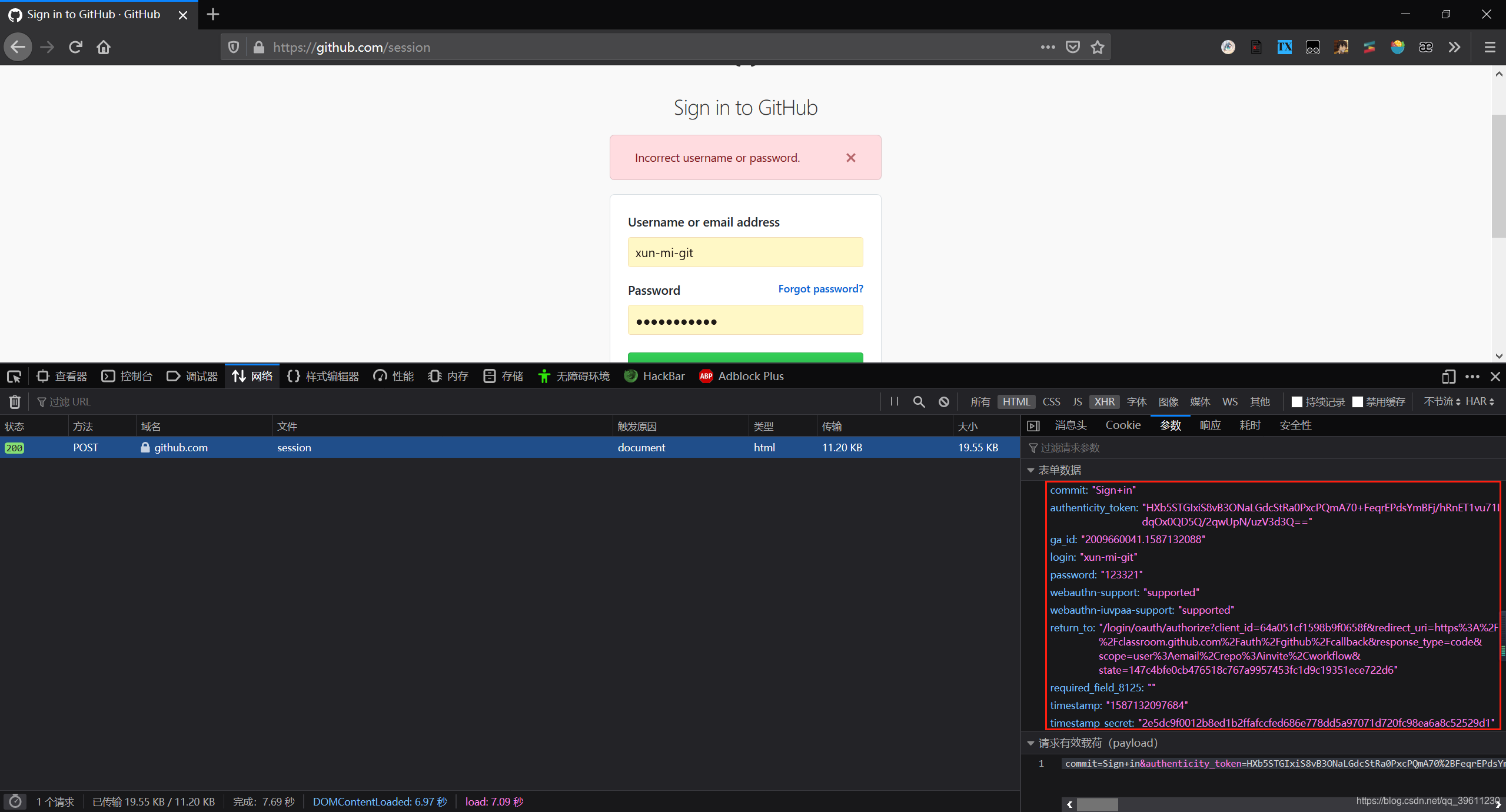
提交post请求,使用的方法为scrapy.FormRequest()代码如下。
# -*- coding: utf-8 -*-
import scrapy
class GithubSpider(scrapy.Spider):
name = 'github'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
commit = 'Sign in'
authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract_first()
ga_id = response.xpath('//input[@name="ga_id"]/@value').extract_first()
login = ''
password = ''
timestamp = response.xpath('//input[@name="timestamp"]/@value').extract_first()
timestamp_secret = response.xpath('//input[@name="timestamp_secret"]/@value').extract_first()
post_data = {
'commit': commit,
'authenticity_token': authenticity_token,
# 'ga_id': ga_id,
'login': login,
'password': password,
'timestamp': timestamp,
'timestamp_secret': timestamp_secret,
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported'
}
# print(post_data)
# 发送post请求
yield scrapy.FormRequest(
url='https://github.com/session',
formdata=post_data,
callback=self.after_login
)
def after_login(self, response):
# print(response)
with open('github.html', 'w', encoding='utf-8') as f:
f.write(response.text)
新方法-自动登录
自动登录的好处是,scrapy会帮助我们自动找到from表单,然后自动将我们需要的只需填入需要填写的内容(账号密码)其他用于验证的我们无需处理即可实现登录
这里我们需要用到的方法是yield scrapy.FormRequest.from_response()
# -*- coding: utf-8 -*-
import scrapy
class GithubautoSpider(scrapy.Spider):
name = 'githubAuto'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
yield scrapy.FormRequest.from_response(
response=response,
formdata={"login": "", "password": ""},
callback=self.after_login
)
def after_login(self, response):
with open('github.html', 'w', encoding='utf-8') as f:
f.write(response.text)
.from_response()除了能自动登录外,他还可以作为表单提交的方法使用,比如说进行搜索的时候,就可以使用.from_response()进行表单提交。页面中有多个表单,可以使用其中的formname、formid、formxpath等属性来识别表单
图片(文件)下载器
图片下载器(Images Pipeline)、文件下载器(Files Pipeline)使用方式类似,只是个别方法名不同,下列只进行图片下载器的示例。
这次我们使用太平洋作为测试网站,爬取一个我比较喜欢的手机品牌的图片
还是老样子,我们先来不使用下载器,使用原始方式尝试下载:
虽然爬虫中看上代码量并不多,但我们在管道中还需要对图片进行保存处理
# -*- coding: utf-8 -*-
import scrapy
class PhoneSpider(scrapy.Spider):
name = 'phone'
allowed_domains = ['product.pconline.com.cn']
start_urls = ['https://product.pconline.com.cn/pdlib/1140887_picture_tag02.html']
def parse(self, response):
ul = response.xpath('//div[@id="area-pics"]/div/div/ul/li/a/img')
for li in ul:
item = {'图片': li.xpath('./@src').extract_first()}
item['图片'] = 'https:' + item['图片']
yield item
import os
from urllib import request
class Scrapy图片下载Pipeline(object):
def process_item(self, item, spider):
path = os.path.join(os.path.dirname(__file__), '图片')
name = item['图片'].split('/')[-1]
print(name, item['图片'])
request.urlretrieve(item['图片'], path + "/" + name)
return item
使用图片下载器 Images Pipeline
如果使用了scrapy的下载器,可以:
- 避免重新下载最近已经下载过的数据
- 可以方便的指定文件存储的路径
- 可以将下载的图片转换成通用的格式。如:png,jpg
- 可以方便的生成缩略图
- 可以方便的检测图片的宽和高,确保他们满足最小限制
- 异步下载,效率非常高
使用images pipeline下载文件步骤:
- 定义好一个Item,然后在这个item中定义两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的文件的url链接,需要给一个列表

- 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中。如下载路径、下载的url和图片校验码等
- 在配置文件settings.py中配置IMAGES_STORE,这个配置用来设置文件下载路径
- 启动pipeline:在ITEM_PIPELINES中设置’scrapy.pipelines.images.ImagesPipeline’: 1
将上述配置完成后,执行下述代码即可实现图片爬取
# -*- coding: utf-8 -*-
import scrapy
from scrapy_text.items import Scrapy图片下载Item
class PhoneautoSpider(scrapy.Spider):
name = 'phoneAuto'
allowed_domains = ['product.pconline.com.cn']
start_urls = ['https://product.pconline.com.cn/pdlib/1140887_picture_tag02.html']
def parse(self, response):
ul = response.xpath('//div[@id="area-pics"]/div/div/ul/li/a/img')
for li in ul:
item = Scrapy图片下载Item()
item['image_urls'] = li.xpath('./@src').extract_first()
item['image_urls'] = ['https:' + item['image_urls']]
yield item
图片下载器的源码在from scrapy.pipelines.images import ImagesPipeline处,如果你感兴趣可以自行查看
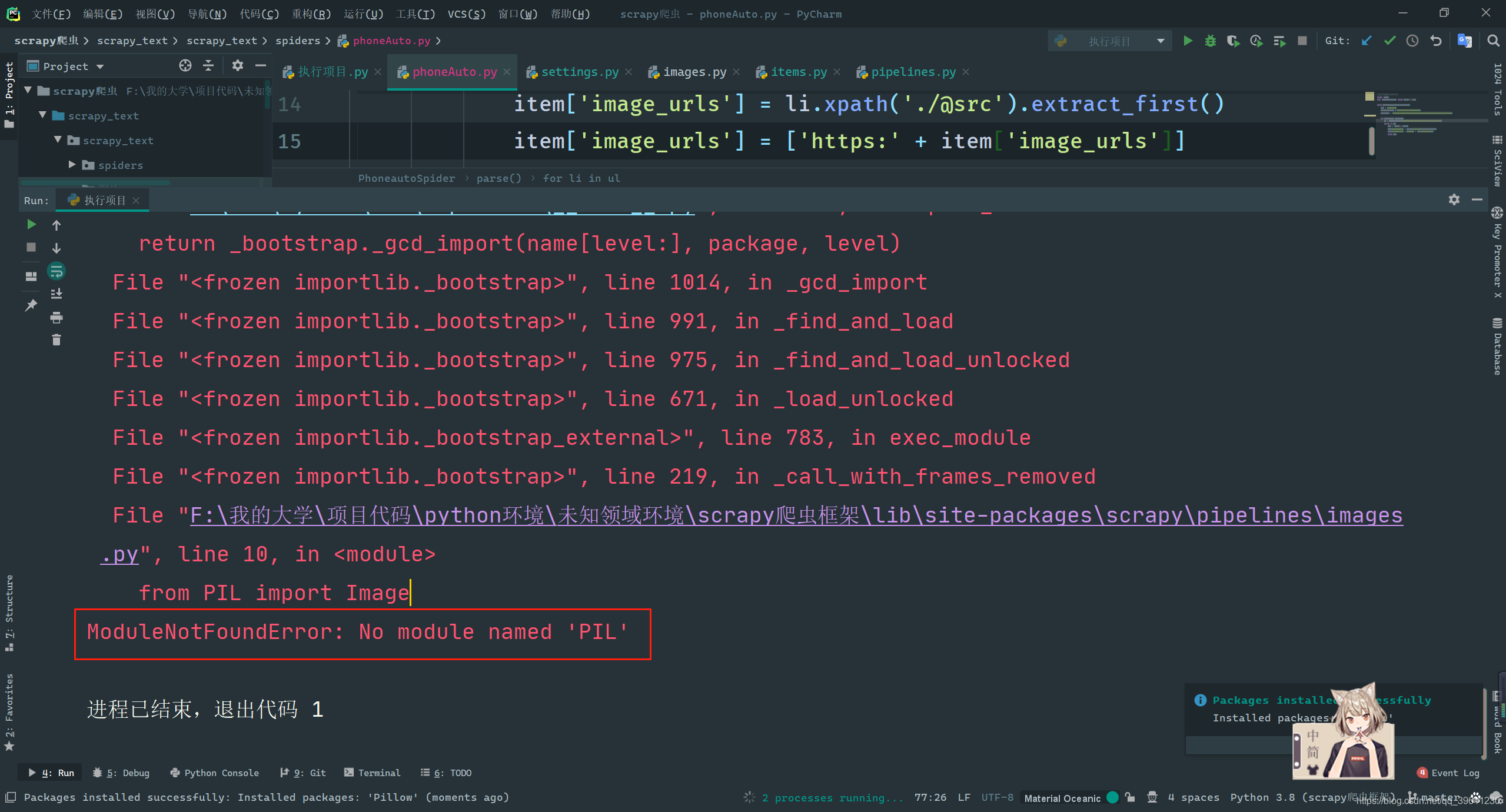
图片下载器提示 ModuleNotFoundError: No module named ‘PIL’ 报错解决
虽然报错为缺少PIL库,但因为此库没有Python3版本,已经被弃用,所以我们需要安装此库的Python版本Pillow即可
pip install pillow
使用文件下载器 Files Pipeline
- 定义好一个Item,然后在这个item中定义两个属性,分别为file_urls以及files。files_urls是用来存储需要下载的文件的url链接,需要给一个列表
- 当文件下载完成后,会把文件下载的相关信息存储到item的files属性中。如下载路径、下载的url和文件校验码等
- 在配置文件settings.py中配置FILES_STORE,这个配置用来设置文件下载路径
- 启动pipeline:在ITEM_PIPELINES中设置’scrapy.piplines.files.FilesPipeline’: 1
源码位于from scrapy.pipelines.files import FilesPipeline,使用和上述的图片下载器类似,这里就不在演示了。
