一、哈希桶:
1、通过哈希函数计算桶号
(1)哈希桶的最佳状态,就是每个桶下面挂一个元素(动态的可以增容:表格中的元素和总的个数相等):解决了一个哈希桶下面挂多个元素的情况
(2)素数表泄露,则别人知道了增容方式,受到攻击。继续增容,导致插入相同元素的概率增加,一条表格下挂的元素增多,使性能下降。解决方法:
在下面挂一个红黑树,效率达到lgN
2、每个桶下面挂一个链表,链表采用头插,效率高(尾插效率低)
二、哈希桶的实现
HashBucket.h
1、通过哈希函数计算桶号
(1)哈希桶的最佳状态,就是每个桶下面挂一个元素(动态的可以增容:表格中的元素和总的个数相等):解决了一个哈希桶下面挂多个元素的情况
(2)素数表泄露,则别人知道了增容方式,受到攻击。继续增容,导致插入相同元素的概率增加,一条表格下挂的元素增多,使性能下降。解决方法:
在下面挂一个红黑树,效率达到lgN
2、每个桶下面挂一个链表,链表采用头插,效率高(尾插效率低)
二、哈希桶的实现
HashBucket.h
# pragma once
# include<stdio.h>
# include<assert.h>
# include<stdlib.h>
# include<malloc.h>
# include"Common.h"
typedef int DataType;
typedef struct HashNode
{
struct HashNode *_pNext;
DataType _data;//哈希表中存放的数据
}HashNode;
typedef struct HashBucket//哈希桶
{
HashNode **_table;//二级指针,表示哈希表格,指向哈希桶的空间(桶中存放指向链表的指针)
int _capacity;//容量
int _size;//哈希表格中有效元素的个数
}HashBucket;
//初始化
void HashBucketInit(HashBucket *ht,int capacity);
//元素不可以重复的插入
void HashBucketInsertUnique(HashBucket *ht, DataType data);
//元素可以重复的插入
void HashBucketInsertEqual(HashBucket *ht, DataType data);
//删除不可以重复的元素
void HashBucketDeleteUnique(HashBucket *ht, DataType data);
//删除可以重复的元素
void HashBucketDeleteEqual(HashBucket *ht, DataType data);
//查找
HashNode* HashBucketFind(HashBucket *ht, DataType data);
//哈系桶中有多少元素
int HashBucketSize(HashBucket *ht);
//哈希桶是不是空的
int HashBucketEmpty(HashBucket *ht);
//销毁哈希桶
void HashBucketDestory(HashBucket *ht);
HashBucket.c
# include"HashBucket.h"
# include"Common.h"
//哈希函数
int HashFunc(HashBucket *ht, DataType data)
{
return data%ht->_capacity;
}
void HashBucketInit(HashBucket *ht, int capacity, int IsLineDetetive)
{
int i = 0;
assert(ht);
//获取下一个元素,防止下一个元素不为素数
capacity = GetNextPrime(capacity);
//开辟哈希桶的空间
ht->_table = (HashNode**)malloc(sizeof(HashNode*)*capacity);
if (NULL == ht->_table)//如果开辟空间失败,返回空
{
assert(0);
return;
}
for (; i < capacity; ++i)//初始化空间的每一个位置为空
ht->_table[i] = NULL;
ht->_capacity = capacity;
ht->_size = 0;
}
void HashBucketInsertUnique(HashBucket *ht, DataType data)
{
HashNode *pNewNode = NULL;
//计算元素的桶号
int bucketNo = HashFunc(ht, data);
//检测元素是否在当前桶中(元素须唯一),遍历一遍
HashNode *pCur = ht->_table[bucketNo];//从bucketNo位置开始遍历
while (pCur)
{
if (data == pCur->_data)//若果存在则返回
return;
pCur = pCur->_pNext;//不存在,则继续往下走
}
//创建新节点,在哈希桶下的链表中插入元素
pNewNode = BuyHashNode(data);
//头插法
pNewNode->_pNext = ht->_table[bucketNo];
ht->_table[bucketNo] = pNewNode;
ht->_size++;
}
HashNode *BuyHashNode(DataType data)
{
HashNode *pNewNode = (HashNode*)malloc(sizeof(HashNode));
if (NULL == pNewNode)//新空间申请失败
{
assert(0);
return NULL;
}
//节点创建成功
pNewNode->_data = data;
pNewNode->_pNext = NULL;
return pNewNode;
}
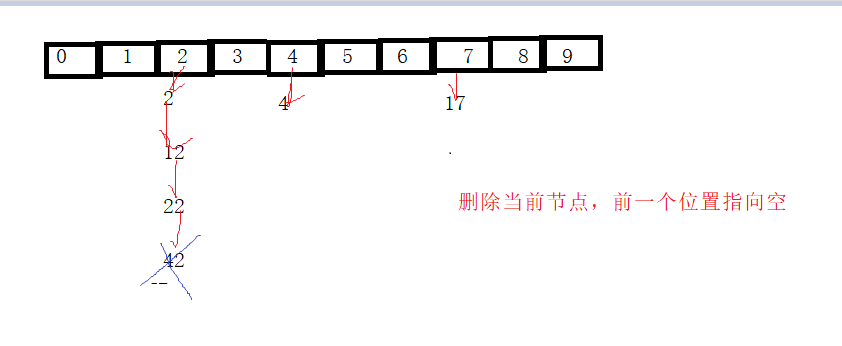
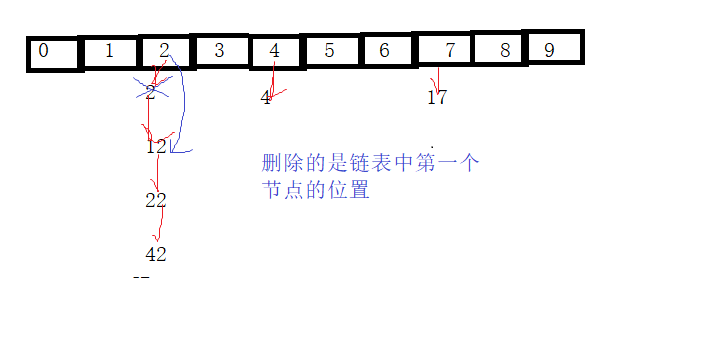
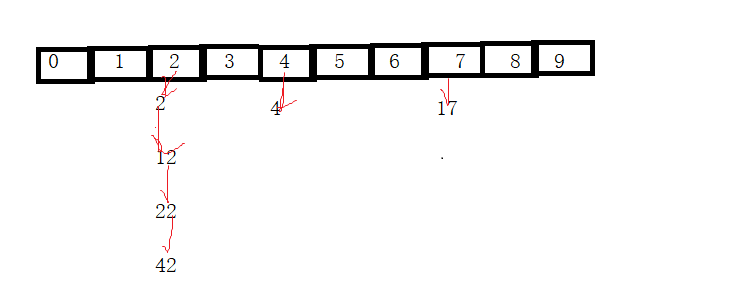
void HashBucketDeleteUnique(HashBucket *ht, DataType data)
{
//计算元素的桶号
int bucketNo = HashFunc(ht, data);
//检测元素是否在当前桶中
HashNode *pPre = NULL;
HashNode *pCur = ht->_table[bucketNo];//找到了桶的位置
while (pCur)
{
if (data == pCur->_data)//等于此位置
{
//删除链表中的第一个节点
if (pCur == ht->_table[bucketNo])//cur是链表中的第一个节点,
{
ht->_table[bucketNo] = pCur->_pNext;//哈希桶里直接放cur的下一个节点
}
//不是链表中的第一个节点
else
{
pPre->_pNext = pCur->_pNext;//前一个节点指向当前节点的下一个节点
}
free(pCur);
ht->_size--;
return;
}
pPre = pCur;//如果不是pPre记录下pCur
pCur = pCur->_pNext;//cur继续向后走
}
}
void HashBucketInsertEqual(HashBucket *ht, DataType data)
{
int bucketNo = HashFunc(ht, data);//计算桶号,通过哈希函数计算
//可以重复,不用检测链表中是否已经存在此元素,直接向链表中插入此元素即可
HashNode *pNewNode = BuyHashNode(data);//给定新节点
//头插
pNewNode->_pNext = ht->_table[bucketNo];//新节点连接原节点,原节点为桶位置
ht->_table[bucketNo] = pNewNode;//此时桶的位置为新节点的位置
ht->_size++;
}

void HashBucketDeleteEqual(HashBucket *ht, DataType data)
{
//在当前哈系桶中查找桶位置
int bucketNo = HashFunc(ht, data);
HashNode *pPre = NULL;
HashNode *pCur = ht->_table[bucketNo];
while (pCur)
{
if (data == pCur->_data)
{
if (pCur == ht->_table[bucketNo])//当前要删除元素元素是桶位置
{
ht->_table[bucketNo] = pCur->_pNext;
free(pCur);
pCur = ht->_table[bucketNo];//继续朝后走,后面有可能还有要删除位置
}
else//是要删除的节点,且在链表处,不在桶位置
{
pPre->_pNext = pCur->_pNext;
free(pCur);
pCur = pPre->_pNext;
}
}
else//不相等
{
pPre = pCur;
pCur = pCur->_pNext;
}
}
}
int HashBucketSize(HashBucket *ht)
{
return ht->_size;
}
int HashBucketEmpty(HashBucket *ht)
{
return 0 == ht->_size;
}
void HashBucketDestory(HashBucket *ht)
{
int i = 0;
for (; i < ht->_capacity; ++i)//i表示要删除的桶
{
HashNode *pCur = ht->_table[i];
while (pCur)//只要桶里面有节点
{
//删除链表中第一个节点的位置
ht->_table[i] = pCur->_pNext;
free(pCur);
pCur = ht->_table[i];//把当前节点放到链表中第一个节点的位置
}
}
free(ht->_table);
ht->_capacity = 0;
ht->_size = 0;
}
common.c
//闭散列用的少,因为浪费空间
# define _CRT_SECURE_NO_WARNINGS 1
# include"Common.h"
#define _PrimeSize 28//enum{_PrimeSize =28};
// 使用素数表对齐做哈希表的容量,降低哈希冲突
const unsigned long _PrimeList[_PrimeSize]=
{//可将long换为long long获取更大的素数
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457u,
1610612711ul, 3221225473ul, 4294967291ul
};
//获取比容量大的第一个素数
size_t GetNextPrime(size_t capacity)
{
int i = 0;
for (; i < _PrimeSize; ++i)
{
if (_PrimeList[i]>capacity)//容量小于素数,直接返回该素数
return _PrimeList[i];
}
return _PrimeList[_PrimeSize - 1];//容量太大了,返回最后一个素数
}
unsigned int StrToInt(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}