什么是压缩
想办法让源文件变得更小并能还原。
为什么要进行文件压缩
- 文件太大,节省空间
- 提高数据再网络上传输的效率
- 对数据有保护作用—加密
文件压缩的分类
- 无损压缩
- 源文件被压缩后,通过解压缩能够还原成和源文件完全相同的格式
- 有损压缩
- 解压缩之后不能将其还原成与源文件完全相同的格式–解压缩之后的文件再识别其内容时基本没有影响
GZIP压缩
LZ77变形:
原理将重复出现得语句用尽可能短得标记来替换
字符串的压缩
LZ77可以消除文件中重复出现的语句,但还存在字节方面的重复
基于Huffman编码得压缩
基于字节的压缩
1个字节—>8个bit位,如果对于每个字节如果能够找到一个更短的编码,来重新改写原3数据,可以起到压缩的目的
Huffman树的概念
从二叉树的根结点到二叉树中所有叶结点的路径长度与相应权值的乘积之和为该二叉树的带权路径长度WPL。
把带权路径最小的二叉树称为Huffman树
Huffman树的概念
用户提供一组权值信息
- 以每个权值为结点创建N棵二叉树的森林
- 如果二叉树森林中有超过两个树,进行以下操作
- 从二叉树森林中取出根结点权值最小的两棵二叉树
- 以该两棵二叉树作为某个结点的左右子树创建一颗新的二叉树,新二叉树中的权值为其左右子树权值之和
- 将新创建的二叉树插入到森林中
创建好之后的二叉树森林中的每棵树可以采用堆(priority_queue)保存
Huffman树的创建
Huffman树的结点定义
struct HuffManTreeNode
{
HuffManTreeNode(const W& weight = W())
:_pLeft(nullptr)
, _pRight(nullptr)
, _pParent(nullptr)
, _weight(weight)
{}
HuffManTreeNode<W>* _pLeft;
HuffManTreeNode<W>* _pRight;
HuffManTreeNode<W>* _pParent;//加上双亲指针域
W _weight; //结点的权值
};
Huffman树的类
template<class W>
class HuffManTree
{
typedef HuffManTreeNode<W> Node;
public:
HuffManTree()
:_pRoot(nullptr)
{}
HuffManTree(const vector<W>& vWeight, const W& invaild)
{
//进行建树操作
CreatHuffManTree(vWeight,invaild);
}
~HuffManTree()
{
_DestroyTree(_pRoot);
}
Node* GetRoot()
{
return _pRoot;
}
void CreatHuffManTree(const vector<W>& vWeight,const W& invaild)
{
//1.构建森林
//底层为优先级队列
priority_queue<Node*,vector<Node*>,Less<W>> q;
for (auto e : vWeight)
{
//默认插入的数据没有重复
if (e == invaild)//如果是无效的权值,就不放了
continue;
q.push(new Node(e));//创建新的结点,树就有了
}
//2.看森林里面有没有超过两个树
while (q.size() > 1)
{
//取根结点权值最小的两颗树
Node* pLeft = q.top();
q.pop();
Node* pRight = q.top();
q.pop();
// 以该两棵二叉树作为某个结点的左右子树创建一颗新的二叉树,
//新二叉树中的权值为其左右子树权值之和
Node* pParent = new Node(pLeft->_weight + pRight->_weight);
pParent->_pLeft = pLeft;
pParent->_pRight = pRight;
//将新数插入到Huffman树中
pLeft->_pParent = pParent; //更新双亲
pRight->_pParent = pParent;
q.push(pParent);
}
//3.森林里只有一棵树了,就是哈夫曼树
_pRoot = q.top();
}
private:
//销毁二叉树,只能用后序遍历的方式进行销毁
void _DestroyTree(Node*& pRoot)
{
if (pRoot)
{
_DestroyTree(pRoot->_pLeft);
_DestroyTree(pRoot->_pRight);
delete pRoot;
//要改指针本身,要么传二级指针,要么一级指针的引用
pRoot = nullptr;
}
}
private:
Node * _pRoot;
};
基于Huffman编码的压缩和解压缩
压缩
- 统计源文件中每个字节出现的次数
- 用统计的结果创建Huffman树
- 什么是Huffman树:带权路径长度最短的一颗二叉树----权值越大,越靠近根结点
- Huffman树创建规则:
- 用所有的权值创建只有根结点的二叉树森林
- 从二叉树森林中取出根结点权值最小的两棵二叉树
- 以该两棵二叉树作为某个结点的左右子树创建一颗新的二叉树,新二叉树中的权值为其左右子树权值之和
- 将新创建的二叉树插入到森林中
- 取权值最小,用优先级队列也就是堆
- 从Huffman树种获取字节的编码
void GenerateHuffmanCode(pRoot)
{
if(nullptr == pRoot )
return ;
GenerateHuffmanCode(pRoot->left);
GenerateHuffmanCode(pRoot->right);
//是叶子结点获取编码
if(nullptr == pRoot->left&& nullptr == pRoot->right)
{
Node* pParent =pRoot->parent;
Node* pCur = pRoot;
while(pParent)
{
if(pCur == pParent->left)
str+='0';
else
str+='1';
}
}
}
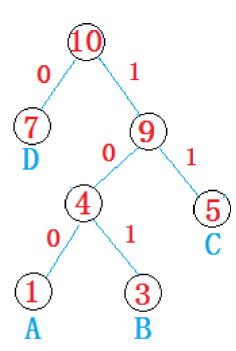
压缩文件实现
我们将文件中出现的字符信息保存在一个大小为256的数组中
//构造函数
FileCompressHuff::FileCompressHuff()
{
_fileInfo.resize(256);
for (int i = 0; i < 256; ++i)
{
_fileInfo[i]._ch = i;
_fileInfo[i]._count = 0;
}
}
每一个数组的元素都是一个结构体类型,里面要保存该字符的信息,如:编码,出现的次数
而且要支持字符之间的一些运算
struct CharInfo
{
unsigned char _ch; //具体的字符
size_t _count; //字符出现的次数
std::string _strCode;//字符编码
CharInfo(size_t count = 0)
:_count(count)
{}
CharInfo operator+(const CharInfo& c)
{
//返回对象,无名对象
return CharInfo(_count + c._count);
}
bool operator>(const CharInfo& c)
{
return _count > c._count;
}
//比较次数
bool operator==(const CharInfo& c)
{
return _count == c._count;
}
};
最后再按照上面的四步来完成压缩的任务
void FileCompressHuff::CompressFile(const string& path)
{
//1.统计源文件中每个字符出现的次数
FILE* fIn = fopen(path.c_str(),"rb");
if (nullptr == fIn)
{
assert(false);
return;
}
unsigned char * pReadBuff = new unsigned char[1024];
int rdSize = 0;
while (true)
{
//读文件
rdSize = fread(pReadBuff, 1, 1024, fIn);
if (0 == rdSize)
break;
//统计
for (int i = 0; i < rdSize; ++i)
{
_fileInfo[pReadBuff[i]]._count++;
}
}
//2.以这些出现的次数为权值创建哈夫曼树
HuffManTree<CharInfo> t(_fileInfo,CharInfo());
//3.获取每个字符的编码
GenerateHuffManCode(t.GetRoot());
//4.获取到的字符编码重新改写
FILE* fOut = fopen("2.txt", "wb"); //打开一个文件保存压缩后的结果
if (nullptr == fOut)
{
assert(false);
return;
}
//将来要保存文件的后缀,所以压缩时要读取压缩格式文件头部信息
WriteHead(fOut, path);
fseek(fIn,0,SEEK_SET); //把文件指针再次放到文件的起始位置
char ch = 0; //存放字符编码
int bitcount = 0; //计算放了多少个比特位
while (true)
{
rdSize = fread(pReadBuff, 1, 1024,fIn);
if (0 == rdSize) //文件读取结束
break;
//根据字节的编码对读取到的内容进行重写
for (size_t i = 0; i < rdSize; ++i)
{
//拿到编码
string strCode = _fileInfo [pReadBuff[i]]._strCode;
//A "100"
for (size_t j = 0; j < strCode.size(); ++j)
{
ch <<= 1; //每放一个往左一位,把下一个编码往里放
//存放的时候,一个一个比特位来放
if ('1' == strCode[j])
ch |= 1;
bitcount++;
if (8 == bitcount) //说明ch满了,把这个字节写到文件中去
{
//fputc 写单个字节的函数
fputc(ch, fOut);
//写完后,都清零
bitcount = 0;
ch = 0;
}
}
}
}
//最后一次ch中可能不够8个比特位
if (bitcount < 8)
{
ch <<= 8 - bitcount; //左移剩余的位数
//不够的位肯定要写到文件中
fputc(ch, fOut);
}
delete[]pReadBuff;
fclose(fIn);
fclose(fOut);
}
获取字符编码
//计算字符编码
void FileCompressHuff::GenerateHuffManCode(HuffManTreeNode<CharInfo>* pRoot)
{
if (nullptr == pRoot)
return;
GenerateHuffManCode(pRoot->_pLeft);
GenerateHuffManCode(pRoot->_pRight);
//找到叶子结点
if (nullptr == pRoot->_pLeft&&pRoot->_pRight == nullptr)
{
string& strCode = _fileInfo[pRoot->_weight._ch]._strCode;
HuffManTreeNode<CharInfo>* pCur = pRoot;
HuffManTreeNode<CharInfo>* pParent = pCur->_pParent;
while (pParent)
{
if (pCur == pParent->_pLeft) //左为0
{
strCode += '0';
}
else //右为1
{
strCode += '1';
}
pCur = pParent;
pParent = pCur->_pParent;
}
//字符编码从叶子结点开始获取是个反的
//我们需要把它翻转一下
reverse(strCode.begin(), strCode.end());
//_fileInfo[pRoot->_weight._ch]._strCode = strCode;
}
}
获取文件后缀
//获取文件的后缀
//2.txt
//F:\123\2.txt
string FileCompressHuff:: GetFilePostFix(const string& filename)
{
//substr截取文件,第二个参数没有给的话默认截取到末尾
return filename.substr(filename.rfind('.'));
}
压缩文件的格式
压缩文件中只保存压缩之后的数据可以吗?
答案是不行的,因为在解压缩时,没有办法进行解压缩。比如:10111011 00101001 11000111 01011,只有压缩数据是没办法进行解压缩的,因此压缩文件中除了要保存压缩数据,还必须保存解压缩需要用到的信息:
- 源文件的后缀
- 字符次数对的总行数
- 字符以及字符出现次数(为简单期间,每个字符放置一行
- 压缩数据
//压缩文件格式
void FileCompressHuff::WriteHead(FILE* fOut, const string& filename)
{
assert(fOut);
//写文件的后缀
string strHead;
strHead += GetFilePostFix(filename);
strHead += '\n'; //后缀与后面的内容之间用\n隔开
//写行数
size_t lineCount = 0;
string strChCount;
char szValue[32] = { 0 }; //缓冲区放入字符次数
for (int i = 0; i < 256; ++i)
{
CharInfo& charInfo = _fileInfo[i];
if (charInfo._count)
{
lineCount++; //行数
strChCount += charInfo._ch; //字符
strChCount += ':'; //字符与字符次数之间用冒号隔开
_itoa(charInfo._count, szValue, 10);
strChCount += szValue; //字符次数
strChCount += '\n'; //末尾加\n
}
}
_itoa(lineCount, szValue, 10);//接受字符的行数
strHead += szValue; //字符的行树
strHead += '\n'; //换行隔开信息
strHead += strChCount; //字符的种类个数
//写信息
fwrite(strHead.c_str(),1,strHead.size(),fOut);
}
解压缩
- 从压缩文件中获取源文件的后缀
- 从压缩文件中获取字符次数的总行数
- 获取每个字符出现的次数
- 重建huffman树
- 依靠Huffman树解压缩解压缩
要解压缩文件我们先要读取压缩文件的格式信息
//读取压缩文件的信息
void FileCompressHuff::ReadLine(FILE* fIn, string& strInfo)
{
assert(fIn);
//读取一行的字符
while (!feof(fIn)) //只要文件指针没有到文件末尾就读取
{
//读取一个字符
char ch = fgetc(fIn);
if (ch == '\n')
break;
//有效的字符就拼接上去
strInfo += ch;
}
}
按照上面的步骤完成解压缩
void FileCompressHuff::UNComPressFile(const std::string& path)
{
FILE* fIn = fopen(path.c_str(), "rb");
if (nullptr == fIn)
{
assert(false);
return;
}
//读取文件的后缀
string strFilePostFix;
ReadLine(fIn,strFilePostFix);
//读取字符信息的总行数
string strCount;
ReadLine(fIn, strCount);
int lineCount = atoi(strCount.c_str()); //总的行数
//读取字符的信息
for (int i = 0; i < lineCount; ++i)
{
string strchCount;
ReadLine(fIn, strchCount); //读每一行的字符信息
//如果读取到的是\n
if (strchCount.empty())
{
strchCount += '\n'; //将\n写入读取
ReadLine(fIn, strchCount); //多读一行,将\n的次数和冒号读取
}
//A:100
_fileInfo[(unsigned char)strchCount[0]]._count = atoi(strchCount.c_str() + 2);//跳过前两个字符,因为前两个是A:
}
//还原Huffman树
HuffManTree<CharInfo> t; //创建Huffamn树的对象
t.CreatHuffManTree(_fileInfo, CharInfo(0)); //还原Huffman树
FILE* fOut = fopen("3.txt","wb");
assert(fOut);
//解压缩
char* pReadBuff = new char[1024]; //创建缓冲区
char ch = 0;
HuffManTreeNode<CharInfo>* pCur = t.GetRoot();
size_t fileSize = pCur->_weight._count; //文件总的大小就是根结点的权值的次数
size_t uncount = 0;//表示解压缩了多少个
while (true)
{
size_t rdSize = fread(pReadBuff,1,1024,fIn); //读数据
if (0 == rdSize)
break;
//一个个字节进行解压缩
for (size_t i = 0; i < rdSize; ++i)
{
//只需要将一个字节中的8个比特位单独处理
ch = pReadBuff[i];
for (int pos = 0; pos < 8; ++pos)
{
//增加一次判断
if (nullptr == pCur->_pLeft && nullptr == pCur->_pRight)
{
//uncount++; //每次解压缩一个,就++一下
fputc(pCur->_weight._ch, fOut);
if (uncount == fileSize)
break;
//叶子结点,解压出一个字符,写入文件
pCur = t.GetRoot(); //把pCur放到树根的位置上继续
}
if (ch & 0x80)
//如果该位上的数字为1
pCur = pCur->_pRight;
else
pCur = pCur->_pLeft;
ch <<= 1; //与完后往左移动一位
if (nullptr == pCur->_pLeft && nullptr == pCur->_pRight)
{
uncount++; //每次解压缩一个,就++一下
fputc(pCur->_weight._ch, fOut);
if (uncount == fileSize)
break;
//叶子结点,解压出一个字符,写入文件
pCur = t.GetRoot(); //把pCur放到树根的位置上继续
}
}//for循环完后再读取下一个字节
}
}
delete[]pReadBuff;
fclose(fIn);
fclose(fOut);
}
出现的问题
1. 加中文
问题1
压缩时统计源文件中每个字符出现的次数时,出现崩溃,因为数组越界,因为char[-128.127];
修改:将char改成unsigned char;
问题2
获取编码时崩溃,将CharInfo结构体中的char改为unsigned char
问题3
解压缩函数读取字符信息时崩溃,strchCount要作为数组下标必须为整数,将其强转为unsigned char
2.多行信息
问题1
解压缩函数中的解压缩时崩溃,因为pCur为空了,因为读取文件时,读取空格就直接什么都没有读到,所以遇到空格时应该多读一行,在解压缩读取文件时处理\n
问题2
文件量增大时,只能解压缩一部分,将所有的文件打开和写入方式转变为以二进制形式打开和写入,并在解压缩时再增加一次判断
完整代码:
要改进的方面
- 保证压缩的正确性
- 压缩比率
- 是不是每次压缩之后变小?有没有可能压缩变大?
- 文本文件,视频,音频,图片,都可以压缩?
- 其它改进的方式
