文章目录
一、致谢
最近打算研究推荐系统,第一篇阅读的就是实验室推荐的《Neural Collaborative Filtering》,何向南博士的论文。下为作者论文源码地址:
源码地址
之后我也阅读了一些关于推荐系统理论的论文以及书刊,了解到了利用用户行为数据的方面最基本的两个推荐角度:面向User和面向Item。
向南博士这篇论文选择的角度为面向User,众所周知最常见的面向User的计算用户距离的方法为MF(矩阵因式分解)法。而这篇论文中,讨论了关于矩阵因式分解法的弊端,提出了GMF(广义矩阵因式分解)以及有创新意义的混合模型NeuMF(矩阵因式分解与深度神经网络结合)。
刚接触这一领域的我也借此思路和作者提供的源码,熟悉Keras的基本框架以及重温了作者的算法,并基于较新版本的tensorflow-keras框架对源码进行兼容性修改。
再次感谢作者的论文以及源码。
本文图片来源《Neural Collaborative Filtering》2017
Xiangnan He National University of Singapore, Singapore
二、算法模型
作者的思路为, 在原本的MF的基础之上,增加一个边缘权重向量h以及激活函数a,获得激活后的广义矩阵因式分解模型,对原有MF模型做出推广:
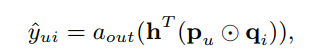
而另一方面,通过对User以及Item提取的隐式向量进行深度学习,找到隐式向量与label之间的关系,并进行预测,从而实现基于MLP(多层感知机)模型的面向用户推荐算法。

最终,将两者结合,引入权重参数,得到混合模型NeuMF,经过作者的测试实验,发现混合模型的效果更好,而且证实了预处理以及深度神经网络的必要性。

三、源码分析
原始源码在较新版本python包中会出现很多错误,在本文中我的注释代码对其中不兼容内容进行修改,并进行测试。
经过修改源码地址
3.1 源码结构

- Data:经过处理后的原始数据:
分为训练集、测试集,训练集中包含正负样本(隐式用户偏好) - Pretrain:预处理内容
- Dataset.py:包含从数据集中导入数据操作
- GMF、MLP、NeuMF.py:对应算法的实现
- evaluate.py: 模型评测部分
3.2 数据集读写Dataset.py
#Dataset将原始数据集读入内存
class Dataset(object):
def __init__(self, path):
#调用三个当前类的方法,将训练、测试(正)、测试(负)数据集读入
self.trainMatrix = self.load_rating_file_as_matrix(path + ".train.rating")
self.testRatings = self.load_rating_file_as_list(path + ".test.rating")
self.testNegatives = self.load_negative_file(path + ".test.negative")
assert len(self.testRatings) == len(self.testNegatives)
self.num_users, self.num_items = self.trainMatrix.shape
#读入测试打分集合,只需要记录记录打分的user和item,不需要关系打多少分,因为考虑的是隐式数据集推荐,最终将u-i对保存在list中返回
def load_rating_file_as_list(self, filename):
ratingList = []
with open(filename, "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
user, item = int(arr[0]), int(arr[1])
ratingList.append([user, item])
line = f.readline()
return ratingList
# 导入测试负样本集合,将所有u-list对记录下来,便于测试
def load_negative_file(self, filename):
negativeList = []
with open(filename, "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
negatives = []
for x in arr[1: ]:
negatives.append(int(x))
negativeList.append(negatives)
line = f.readline()
return negativeList
# 将所有打分情况以矩阵的形式记录,便于总体哦停机
def load_rating_file_as_matrix(self, filename):
'''
Read .rating file and Return dok matrix.
The first line of .rating file is: num_users\t num_items
'''
# Get number of users and items
# 获取到样本中用户数和电影条目数
num_users, num_items = 0, 0
with open(filename, "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
u, i = int(arr[0]), int(arr[1])
num_users = max(num_users, u)
num_items = max(num_items, i)
line = f.readline()
#利用上面获得的条目构造特定大小的矩阵,如果有interaction则置为1,没有则保持为0
# Construct matrix
mat = sp.dok_matrix((num_users+1, num_items+1), dtype=np.float32)
with open(filename, "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
user, item, rating = int(arr[0]), int(arr[1]), float(arr[2])
if (rating > 0):
mat[user, item] = 1.0
line = f.readline()
return mat
3.3 评价功能evaluate.py
作者在文中提到两种评价功能:HR(命中率)和NDCG(归一化累计增一),可以在项目中找到对应的评价实现。
# 模型测试接口,可以根据读入的正负测试集,确定当前模型的参数学习成果,使用HR、NDCG两个测试方法进行评估。
def evaluate_model(model, testRatings, testNegatives, K, num_thread):
"""
Evaluate the performance (Hit_Ratio, NDCG) of top-K recommendation
Return: score of each test rating.
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testRatings = testRatings
_testNegatives = testNegatives
_K = K
hits, ndcgs = [],[]
#多线程情况,构造线程池,取出线程进行操作
if(num_thread > 1): # Multi-thread
pool = multiprocessing.Pool(processes=num_thread)
res = pool.map(eval_one_rating, range(len(_testRatings)))
pool.close()
pool.join()
hits = [r[0] for r in res]
ndcgs = [r[1] for r in res]
return (hits, ndcgs)
# Single thread
#单线程情况,调用eval_one_rating函数,针对测试集的Rating的每一个index进行评估
for idx in range(len(_testRatings)):
(hr,ndcg) = eval_one_rating(idx)
#保存评估结果并返回
hits.append(hr)
ndcgs.append(ndcg)
return (hits, ndcgs)
# 针对当前index进行评估
评估策略:
命中率(HR) :找到所有用户最近一次交互,用该用户没有交互过的100个item,计算打分,判断当前最近一次交互是否在100个评分的前十。
def eval_one_rating(idx):
# 唯一的最近一次当前用户的交互样本
rating = _testRatings[idx]
#负样本列表
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
#将唯一的正样本混合进负样本中,正负样本1:99
items.append(gtItem)
map_item_score = {}
# 用当前用户u初始化要测试的用户列表
users = np.full(len(items), u, dtype = 'int32')
# 调用Keras的mode.predict函数,对当用户和项目列表交互情况进行预测
predictions = _model.predict([users, np.array(items)],
batch_size=100, verbose=0)
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i]
items.pop()
# 将预测打分结果从大到小排序,获取最大的指定部分,观察是否正样本在其中
ranklist = heapq.nlargest(_K, map_item_score, key=map_item_score.get)
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return (hr, ndcg)
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return math.log(2) / math.log(i+2)
return 0
3.4 模型构建以及训练
处于布局考虑,没有放置关于命令行参数解析的代码,只把主要模型代码进行注解,下面以最简单形式的GMF为例:相当于模型图的左半边。
def get_model(num_users, num_items, latent_dim, regs=[0,0]):
# 定义输入层,为两个1*n的向量,u的向量长度为item数,i的向量长度为user数
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# 嵌入对象,即类比因式分解,将原始矩阵分解成M*K和K*N两个矩阵相乘,即维度为K的隐向量空间,使用嵌入层进行原始稀疏数据的密集化,压缩为latent_dim = 8的向量。
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = latent_dim, name = 'user_embedding', input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = latent_dim, name = 'item_embedding', input_length=1)
# 构造嵌入层,将嵌入对象的输出对准嵌入层
user_latent = Flatten()(MF_Embedding_User(user_input))
item_latent = Flatten()(MF_Embedding_Item(item_input))
# 直接将两个嵌入层内积(也是文中提到会造成误差的地方)
predict_vector = merge([user_latent, item_latent], mode = 'mul')
# 内积结果经过边缘权重向量h调整(edge weight)和激活函数(sigmoid)
#prediction = Lambda(lambda x: K.sigmoid(K.sum(x)), output_shape=(1,))(predict_vector)
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = 'prediction')(predict_vector)
使用Keras接口创造模型,指定好输入输出
model = Model(input=[user_input, item_input],
output=prediction)
return model
# 构造训练集,从模型取出train(matrix),抽取所有正样本,并随机添加指定书目的负样本,作为训练集合。样本和label需对应
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [],[],[]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
if __name__ == '__main__':
# 参数解析等初始化
args = parse_args()
num_factors = args.num_factors
regs = eval(args.regs)
num_negatives = args.num_neg
learner = args.learner
learning_rate = args.lr
epochs = args.epochs
batch_size = args.batch_size
verbose = args.verbose
topK = 10
evaluation_threads = 1 #mp.cpu_count()
print("GMF arguments: %s" %(args))
model_out_file = 'Pretrain/%s_GMF_%d_%d.h5' %(args.dataset, num_factors, time())
# Loading data
t1 = time()
# 调用Dataset.py接口构建数据集
dataset = Dataset(args.path + args.dataset)
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
num_users, num_items = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, num_users, num_items, train.nnz, len(testRatings)))
# 调用本py文件的接口建立预测学习模型
model = get_model(num_users, num_items, num_factors, regs)
for i in range(len(model.layers)):
print(model.get_layer(index=i).output)
# 增加优化方法
if learner.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
print(model.summary())
# 建立评估模型
t1 = time()
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
#mf_embedding_norm = np.linalg.norm(model.get_layer('user_embedding').get_weights())+np.linalg.norm(model.get_layer('item_embedding').get_weights())
#p_norm = np.linalg.norm(model.get_layer('prediction').get_weights()[0])
print('Init: HR = %.4f, NDCG = %.4f\t [%.1f s]' % (hr, ndcg, time()-t1))
# 训练模型,次数为epochs
best_hr, best_ndcg, best_iter = hr, ndcg, -1
for epoch in range(epochs):
t1 = time()
# Generate training instances
user_input, item_input, labels = get_train_instances(train, num_negatives)
# Training
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, verbose=2, shuffle=True)
t2 = time()
# Evaluation
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
if args.out > 0:
model.save_weights(model_out_file, overwrite=True)
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
if args.out > 0:
print("The best GMF model is saved to %s" %(model_out_file))
3.5 本文提出的最优算法模型构建过程
def get_model(num_users, num_items, mf_dim=10, layers=[10], reg_layers=[0], reg_mf=0):
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# 两个输入稀疏向量
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# 经过嵌入对象提取特征到k空间,由于使用两种算法的混合模型,文中提到两种算法的嵌入层输出并不相同。分别为mf_dim与layers[0]/2
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = mf_dim, name = 'mf_embedding_user',
init = init_normal, W_regularizer = l2(reg_mf), input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = mf_dim, name = 'mf_embedding_item',
init = init_normal, W_regularizer = l2(reg_mf), input_length=1)
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = layers[0]/2, name = "mlp_embedding_user",
init = init_normal, W_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = layers[0]/2, name = 'mlp_embedding_item',
init = init_normal, W_regularizer = l2(reg_layers[0]), input_length=1)
# 与之前GMF思路相同
mf_user_latent = Flatten()(MF_Embedding_User(user_input))
mf_item_latent = Flatten()(MF_Embedding_Item(item_input))
mf_vector = merge([mf_user_latent, mf_item_latent], mode = 'mul') # element-wise multiply
# 构造num_lay层全连接深度神经网络
mlp_user_latent = Flatten()(MLP_Embedding_User(user_input))
mlp_item_latent = Flatten()(MLP_Embedding_Item(item_input))
mlp_vector = merge([mlp_user_latent, mlp_item_latent], mode = 'concat')
for idx in range(1, num_layer):
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name="layer%d" %idx)
mlp_vector = layer(mlp_vector)
# Concatenate 连接两种算法的最终输出
predict_vector = merge([mf_vector, mlp_vector], mode = 'concat')
# 通过sigmoid函数获得预测值
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = "prediction")(predict_vector)
model = Model(input=[user_input, item_input],
output=prediction)
return model
4. 对于源码版本兼容性对应的问题
源码只适用于Keras1.X,而目前主流tensorflow对应Keras为2.X
需要根据源码的报错信息,对原始代码进行修改:
initializations -> liitialize
 需要对python3.X 的shape进行从float32到int32的转换。
需要对python3.X 的shape进行从float32到int32的转换。
已修改好的源码可见
5. 关于相似思路的启发
- 通过user方式,可以突破原始的MF方法,利用深度MLP进行学习,得到更好的结果。
- 我的思考:通过item的方式,通过聚类的方法,也可以突破原始传统的Corr、dist、cos的距离计算方法,而通过聚类为有特征的item进行划分,我认为聚类算法非常有利于在线的动态实现。也是我接下来希望自己尝试的方向。
