一,部署zookeeper
1,分别准备3台虚拟主机A,B,C,关闭防火墙和selinux,
[root@localhost ~] systemctl stop firewalld.service
[root@localhost ~] setenforce 0
#因为三台主机间要相互通信
2,分别在主机A,B,C导入服务所需安装包,安装jdk
[root@localhost ~] rpm -ivh jdk-8u131-linux-x64_.rpm
[root@localhost ~] java -version #查看是否安装成功
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
3,分别在主机A,B,C的/etc/hosts下添加主机名,并修改主机名
[root@localhost ~] vim /etc/hosts #三台主机配置相同即可
[root@localhost ~] cat /etc/hosts|grep 'kafka'
192.168.59.142 kafka01
192.168.59.143 kafka02
192.168.59.144 kafka03
[root@localhost ~] hostnamectl set-hostname kafka01 #在主机A上修改主机名
[root@localhost ~] hostnamectl set-hostname kafka02 #在主机B上修改主机名
[root@localhost ~] hostnamectl set-hostname kafka03 #在主机C上修改主机名
#注!重启主机后会生效新主机名
4,分别在主机ABC上,配置zookeepr,创建myid,并启动zookeeper
#因为zookeeper包是Java环境开发的,无需安装解压即可
[root@localhost ~] tar -zxf zookeeper-3.4.14.tar.gz #解压zk包
[root@localhost ~] mv zookeeper-3.4.14 /usr/local/zookeeper #转移至 /usr/local/并改名
[root@localhost ~] cd /usr/local/zookeeper/conf/
[root@localhost conf] mv zoo_sample.cfg zoo.cfg #简单改下配置文件的名称
[root@localhost conf] vim zoo.cfg #修改配置文件
[root@localhost conf] cat zoo.cfg |grep -v '^#' #查看并过滤出修改的文件内容
tickTime=2000 #服务器之间心跳时间
initLimit=10 #zk服务器最大连接失败时间
syncLimit=5 #zk同步通信时间
dataDir=/tmp/zookeeper #zk数据存放路径
clientPort=2181 #监听端口号
server.1=192.168.59.142:2888:3888 #服务器编号,ip地址,集群通信端口号,集群选举端口号
server.2=192.168.59.143:2888:3888
server.3=192.168.59.144:2888:3888
#主机A创建myid,启动zookeeper---Mode: follower
[root@localhost conf] mkdir /tmp/zookeeper
[root@localhost conf] echo '1' > /tmp/zookeeper/myid #设置myid值
[root@localhost conf] cd ..
[root@localhost zookeeper] ./bin/zkServer.sh start #启动
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost zookeeper] ./bin/zkServer.sh status #查看状态
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower # 选举生成节点
# 主机B创建myid,启动zookeeper----Mode: leader
[root@localhost conf] mkdir /tmp/zookeeper
[root@localhost conf] echo '2' > /tmp/zookeeper/myid #设置myid值
[root@localhost conf] cd ..
[root@localhost zookeeper] ./bin/zkServer.sh start #启动
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost zookeeper] ./bin/zkServer.sh status #查看状态
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader # 选举生成节点
# 主机C创建myid,启动zookeeper---Mode: follower
[root@localhost conf] mkdir /tmp/zookeeper
[root@localhost conf] echo '3' > /tmp/zookeeper/myid #设置myid值
[root@localhost conf] cd ..
[root@localhost zookeeper] ./bin/zkServer.sh start #启动
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost zookeeper] ./bin/zkServer.sh status #查看状态
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower # 选举生成节点
Mode: leader为主节点,Mode: follower为从节点,zk集群一般只有一个leader,多个follower,主一般是响应客户端的读写请求,而从主同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。
到此,zookeeper集群搭建结束,接下来基于zookeeper搭建kafka集群:
Kafka的基本概念:
主题:Topic特指Kafka处理的消息源(feeds of messages)的不同分类。
分区:Partition Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
Producers:消息的数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
Consumers:消息的数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker,这里用的是AMQP协议。
二,部署kafka
5,分别在三台主机上,安装配置kafka,并修改配置文件
[root@localhost ~] tar -zxf kafka_2.11-2.2.0.tgz
[root@localhost ~] mv kafka_2.11-2.2.0 /usr/local/kafka
主机A
[root@localhost ~] cd /usr/local/kafka/config/
[root@localhost config] vim server.properties
broker.id=0 #这里和zookeeper中的myid文件一样,采用的是唯一标识
advertised.listeners=PLAINTEXT://kafka01:9092
zookeeper.connect=192.168.49.142:2181,192.168.49.144:2181,192.168.49.144:2181 #集群的各个节点的IP地址及zookeeper的端口,在zookeeper集群设置的端口是多少这里的端口就是多少
#其他不需改动
主机B
[root@localhost ~] cd /usr/local/kafka/config/
[root@localhost config] vim server.properties
broker.id=1 #这里和zookeeper中的myid文件一样,采用的是唯一标识
advertised.listeners=PLAINTEXT://kafka02:9092
zookeeper.connect=192.168.49.142:2181,192.168.49.144:2181,192.168.49.144:2181 #集群的各个节点的IP地址及zookeeper的端口,在zookeeper集群设置的端口是多少这里的端口就是多少
#其他不需改动
主机C
[root@localhost ~] cd /usr/local/kafka/config/
[root@localhost config] vim server.properties
broker.id=2 #这里和zookeeper中的myid文件一样,采用的是唯一标识
advertised.listeners=PLAINTEXT://kafka03:9092
zookeeper.connect=192.168.49.142:2181,192.168.49.144:2181,192.168.49.144:2181 #集群的各个节点的IP地址及zookeeper的端口,在zookeeper集群设置的端口是多少这里的端口就是多少
#其他不需改动
6,分别启动kafka,并查看kafka日志是否成功
[root@localhost config] cd ..
[root@localhost kafka] ./bin/kafka-server-start.sh -daemon config/server.properties
[root@localhost kafka] tailf /usr/local/kafka/logs/server.log
可以测试一下
#在主机A测试,创建topic,查看当前topic,模拟生产者
[root@kafka01 bin] ./kafka-topics.sh --create --zookeeper 192.168.59.142:2181 --replication-factor 2 --partitions 3 --topic msg
Created topic msg.
[root@kafka01 bin] ./kafka-topics.sh --list --zookeeper 192.168.59.142:2181 msg
[root@kafka01 bin] ./kafka-console-producer.sh --broker-list 192.168.59.142:9092 --topic msg
>haha
>hehe
>hihi
#在主机B上查看,主机A的topic情况
[root@kafka02 kafka] ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.59.143:9092 --topic msg --from-beginning
hihi
haha
hehe
7,分别在三台主机上配置yum源,安装filebeat,修改配置并启动
[root@localhost ~] vim /etc/yum.repos.d/filebeat.repo
[root@localhost ~] cat /etc/yum.repos.d/filebeat.repo
[filebeat-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
#安装filebeat
[root@localhost ~] yum -y install filebeat
#修改配置
[root@localhost ~] vim /etc/filebeat/filebeat.yml
[root@localhost ~] cat /etc/filebeat/filebeat.yml |grep -v '^#'|sed '/^$/d'
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
output.kafka:
enabled: true
hosts: ["192.168.59.142:9092","192.168.59.143:9092","192.168.59.144:9092"]
Topic: msg
#启动filebeat
[root@localhost ~] systemctl enable filebeat #开机自启
[root@localhost ~] systemctl start filebeat #启动
[root@localhost ~] tailf /var/log/filebeat/filebeat #查看日志状态是否成功
8,可以在主机A上安装logstash,编写配置
[root@kafka01 ~] rpm -ivh logstash-6.6.0.rpm
[root@kafka01 ~] vim /etc/logstash/conf.d/messages.conf
[root@kafka01 ~] cat /etc/logstash/conf.d/messages.conf
input {
kafka {
bootstrap_servers => ["192.168.59.142:9092,192.168.59.143:9092,192.168.59.144:9092"]
group_id => "logstash"
topics => "msg"
consumer_threads => 5
}
}
output {
elasticsearch {
hosts => "192.168.59.143:9200"
index => "messages-%{+YYYY.MM.dd}"
}
}
9,在主机B上安装elasticsearch,修改elasticsearch服务配置文件,并启动
[root@kafka02 ~] rpm -ivh elasticsearch-6.6.2.rpm
#配置文件
[root@kafka02 ~] vim /etc/elasticsearch/elasticsearch.yml
[root@kafka02 ~] cat /etc/elasticsearch/elasticsearch.yml|grep -v '^#'|sed '/^$/d'
cluster.name: wg001
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.59.143
http.port: 9200
#添加开机自启,和启动
[root@kafka02 ~] systemctl enable elasticsearch
[root@kafka02 ~] systemctl start elasticsearch
#查看日志
[root@kafka02 ~] tailf /var/log/elasticsearch/wg001.log
10,启动主机A上的logstash,查看日志
[root@kafka01 ~] systemctl start logstash
[root@kafka01 ~] tailf /var/log/logstash/logstash-plain.log
11,在主机C上安装kibana,修改配置文件,并启动kibana
[root@kafka03 ~] rpm -ivh kibana-6.6.2-x86_64.rpm
#修改配置文件
[root@kafka03 ~] vim /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.59.144"
elasticsearch.hosts: ["http://192.168.59.143:9200"]
[root@kafka03 ~] systemctl enable kibana #添加开机自启
[root@kafka03 ~] systemctl start kibana
12,并在浏览器页面测试配置

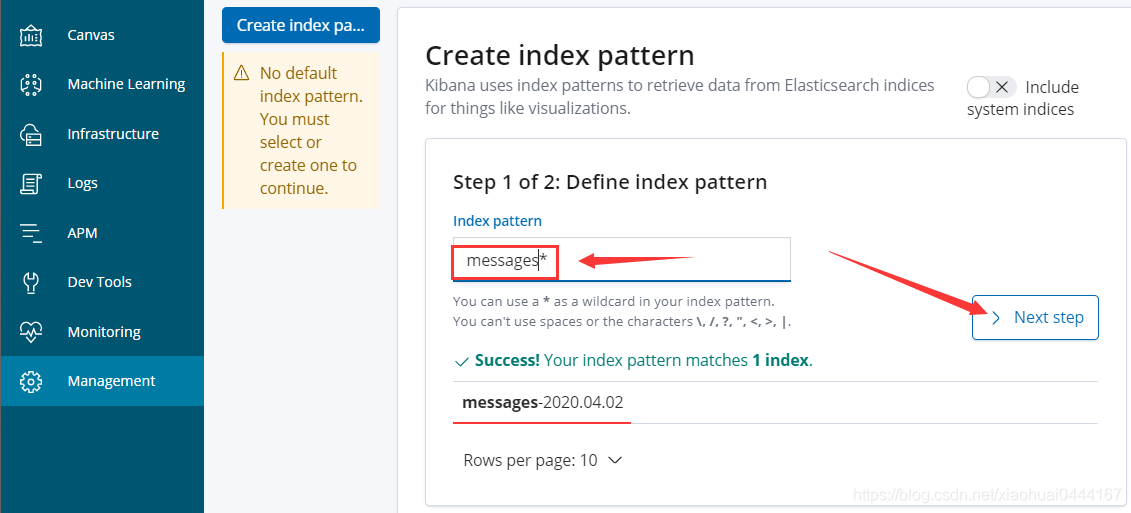
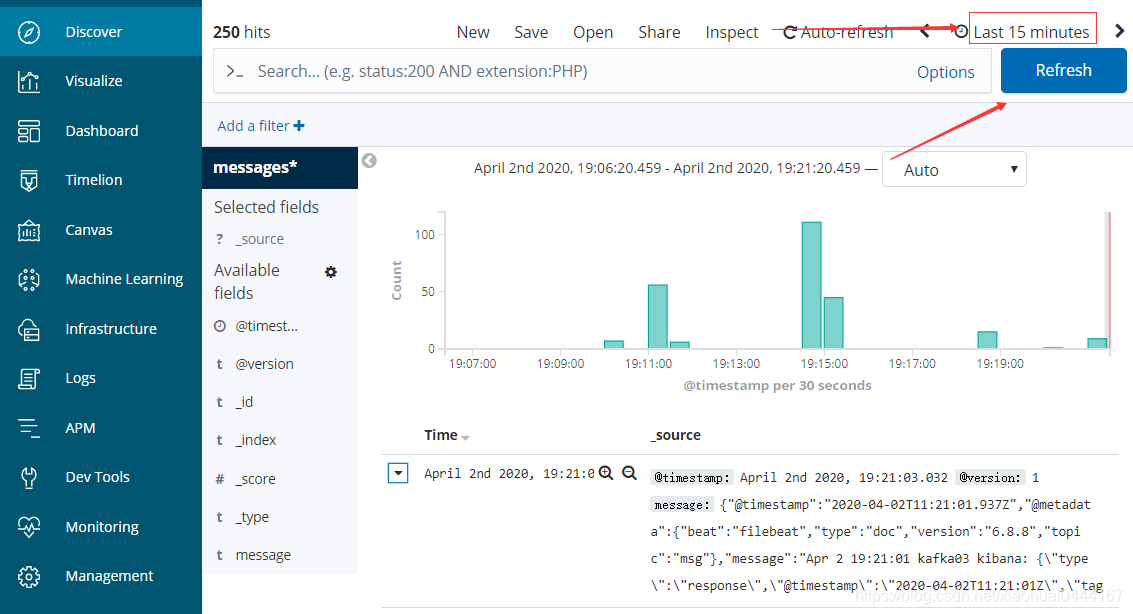
#有些服务启动比较慢,稍等一下下就好了,不是做错,而是服务慢
