Hello,我是 Alex 007,一个热爱计算机编程和硬件设计的小白,为啥是007呢?因为叫 Alex 的人太多了,再加上每天007的生活,Alex 007就诞生了。
最近有一位小学妹 Coco 入坑了算法,没有跟着老师正规的学习,而是自己走的野路子,一些解题方式确实把我雷到了,来看一下小学妹是怎么解决迷宫问题的。

1.题目描述
先来看一下题目吧,所谓的迷宫其实就是一个二维列表,其中的1表示墙壁,0表示空地,之恩给你横着后或者竖着走,不能斜着走。
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]

简单粗暴的方法,你也不能说人家做的是错的,实践出真知,至少结果是对的,但是姑娘,你怕是没遭受迷宫问题的毒打吧。
虽然方法不敢苟同,但至少迷宫图可以拿过来用一下:
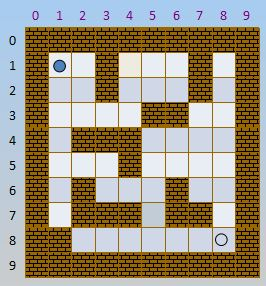
2.解题思路
对于迷宫问题,在算法中通常有两种解决方案,一种是深度优先搜索(Depth First Search),另一种是广度优先搜索(Breadth First Search)。
暂且不论两种搜索算法的适用场景和优劣,我们先来看一下到底该怎么搜索。
计算机并没有我们想象的那么聪明,它解决问题的方法目前为止只有一个,那就是暴力枚举,所谓的各种算法只不过是通过逻辑或者计算减少一些无意义枚举。
在迷宫问题中,计算机搜索的具体实现就是通过不断尝试不同的方向,结合题意,从某个位置开始出发有四个方向可选择,也就是上下左右,但是在走之前,要先判断能不能走,也就是下一步有没有墙存在,还要判断下一步有没有走过,如果以前已经走过的话,那就没必要再走了。
而在二维列表中,所谓的上下左右走,不过就是索引的变换,因此我们可以先定义一下四个方向的计算函数:
directions = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1),
]
大致了解了计算机搜索的方式之后,我们再来具体看一下两种搜索算法。
3.深度优先搜索DFS
所谓是深度优先搜索,顾名思义,就是不到黄河心不死,找到一条路之后,我就一条道走到黑,如果实在没有地方可以继续往下走了,我才往后退,并且把走过的这条路标上“此路不通”。
往后退到除了刚才尝试过的路径还有其它选项的位置,再尝试下一个路径,如此重复,可以将迷宫中所有能走的位置都走一遍,直到某一条路径能够到达终点为止。
def findMazePath(startX, startY, endX, endY):
# 用于记录路径
pathStack = [(startX, startY)]
while pathStack:
current = pathStack[-1]
# 如果当前节点就是终点
if current[0] == endX and current[1] == endY:
for path in pathStack:
print(path, end=" -> ")
print("bingo!")
return True
directions = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1),
]
for direction in directions:
nextStep = direction(current[0], current[1])
# 如果下一个节点可以走
if maze[nextStep[0]][nextStep[1]] == 0:
# 1.添加到路径中
pathStack.append(nextStep)
# 2.标记为已走过
maze[nextStep[0]][nextStep[1]] = 2
break
else:
# 如果for循环正常执行完,说明无路可走,路径中弹出刚才的路线
pathStack.pop()
else:
print('NO PATH TO THROUGH MAZE')
return False
输出结果为:
(1, 1) -> (2, 1) -> (3, 1) -> (4, 1) -> (5, 1) -> (5, 2) -> (5, 3) -> (6, 3) -> (6, 4) -> (6, 5) -> (7, 5) -> (8, 5) -> (8, 6) -> (8, 7) -> (8, 8) -> bingo!
不相信的小伙伴可以像Coco一样,自己按照路线走一下试试。
4.广度优先搜索BFS
广度优先搜索,顾名思义,就是多管齐下,广泛搜索,从某一个位置出发,将所有可以走到的位置存储在队列中,然后一一尝试新的位置,在新的位置中继续判断下一步可以到达的位置,在记录路径的时候,可以开一个列表存储走过的每一步,同时要记录这一步是从哪一步迈出的。
def findMazePath(startX, startY, endX, endY):
queue, path = deque(), []
queue.append((startX, startY, -1))
while queue:
# 取出当前所在位置
current = queue.popleft()
path.append(current)
# 如果当前节点是终点
if current[0] == endX and current[1] == endY:
printPath(path)
return True
directions = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1),
]
# 遍历四个方位的节点
for direction in directions:
nextStep = direction(current[0], current[1])
# 如果下一个节点可以走
if maze[nextStep[0]][nextStep[1]] == 0:
# 1.记录路径和父节点
queue.append((nextStep[0], nextStep[1], len(path) - 1))
# 2.标记为已走过
maze[nextStep[0]][nextStep[1]] = 2
else:
print('NO PATH TO THROUGH MAZE')
return False
输出结果为:
(1, 1) -> (2, 1) -> (3, 1) -> (4, 1) -> (5, 1) -> (5, 2) -> (5, 3) -> (6, 3) -> (6, 4) -> (6, 5) -> (7, 5) -> (8, 5) -> (8, 6) -> (8, 7) -> (8, 8) -> bingo!
而且,广度优先搜索还有一个好处,它搜索到的路径一定是最短路径,因此它是一层一层搜索的,只要到底了目标就立刻返回。
5.总结
最后我们通过一张图来看一下深度优先搜索和广度优先搜索:


完整代码放在了我的GitHub上,喜欢的小伙伴欢迎Star哦!
