爬虫就是做数据采集的,互联网的网站内容多了,就需要采集,就有了爬虫。一般叫网络蜘蛛,网络机器人,spider。百度这样的搜索引擎就是网络爬虫的应用者,最早的实践者。
早期的雅虎是做信息收集,不是采集(将大家的网站分类,类似国内的hao123,给网站归类),但是大家对感兴趣的内容才是最直接的。把网站内容提取出来,用一个综合网站就能找到各个网站关键字内容,这就是现在的搜索引擎。所以雅虎就从归类的网站变成一个搜索引擎的网站。
搜索引擎更多的是用关键字找文档,建立索引库,用关键字可以找到一大堆结果。搜索引擎提供给你的就是看到的一个搜索框,这个框是你与它的交换接口。
你提供的信息到百度后台就要替你查询,用你的关键字查到相关的所有的文档链接以及标题内容返回来
为什么查得到是提前去网站把所有内容看了一遍,需要放出自己的爬虫,启动程序,遍历整个网络的url,把内容拿回来存入到自己的索引库里,存到自己的数据库里,再建索引库,你用关键字查的其实是索引
搜索引擎还需要放出爬虫爬数据,整个互联网基于http协议,通过url访问资源。搜索引擎不能指定,只能广泛的爬,可能找不到你想要的,你就需要爬取你感兴趣的内容
搜索引擎现在正在往智能化引进,不仅仅是索引库了,因为你所有的搜索过程对它来说都是在训练AI机器人
爬虫分类

通用爬虫是无差别对待所收集的数据,只要是网站按照里面的规则去搜索,搜索的网页只要是有内容就收集了,是无差别的收集,通过这边的程序,提取关键字,建立索引,来供搜索

需要给一个起始的url,通过这个url知道,(网页都是你链接我,我链接你,互相链接,还有循环的,首页,进入子页,再跳转到首页,如果爬虫不做处理,就变成死链了)
要给一个页面做为起始页,从起始页开始,从这个url开始发送http请求,通过response的内容,对内容进行分析。把url放到一个队列里,因为可能对多个网站进行爬取
第二步,提取url,先拿第一个,要递归网页的话可能是无底洞。
将网页response里的内容都保存下了,将已经处理好的url挪走,到已经处理完的队列中。
将爬取的url放到已完成队列,保证在未爬取队列有没有爬取的url,爬完之后要把里面关心的url链接提取出来,如果需要,将这些url插入到待爬取队列中。就这样一直爬,直到爬完为止,但是有的时候基本爬不完。所有爬虫基本都是这么做的

新网站如何被搜索引擎获取:
1.主动提交
2.通过其他网站页面中设置的外链,比如友情链接
3.搜索引擎和DNS服务商合作,获取最新收录的网站。

聚焦爬虫,针对特定领域的数据,比如说做股票,就爬取跟股票相关的数据,不是什么都可以爬,是要入刑法的,对公开的数据爬取没事,但是有后门被你偷拿这是不允许的

要符合原则爬取,有不成文的规定,robots协议,这个协议在网站里一般都是写在一个特殊的文本文件robots.txt,这个文件就是告诉所有的爬虫你能爬什么,什么不能爬
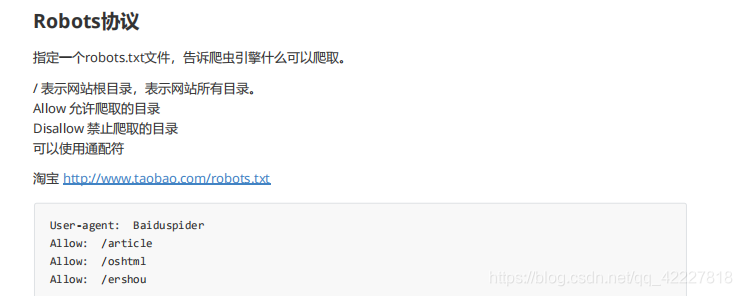
*/表示网站根目录,表示网站所有目录。
allow允许爬取内容的目录
disallow告诉你什么不能爬
通配符代表所有

查看一下淘宝的

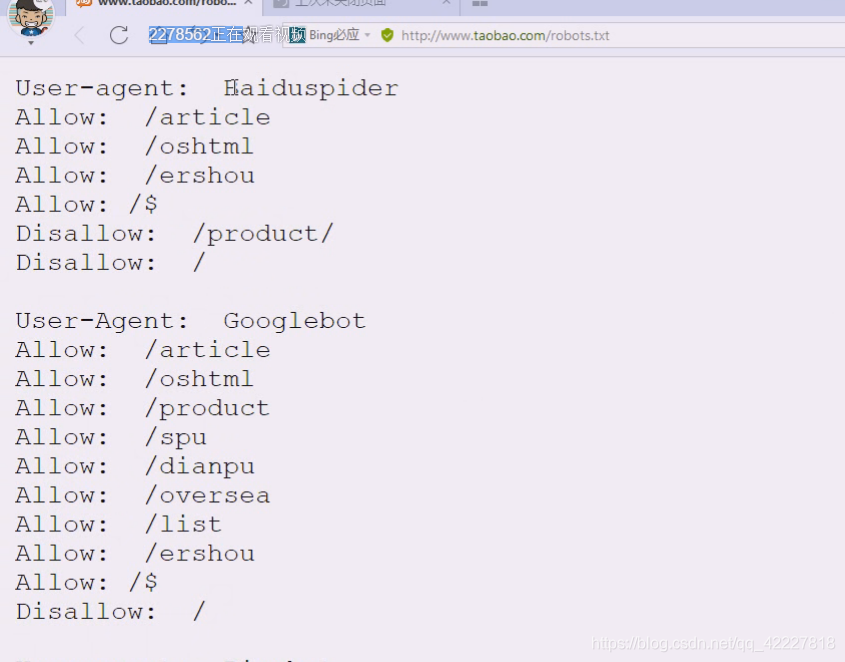
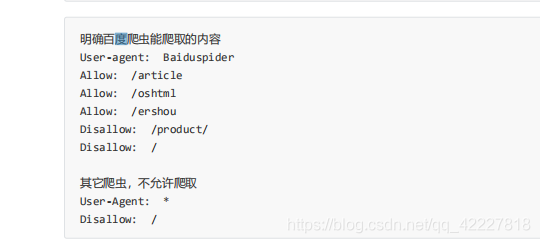
告诉百度这些目录允许看
disallow,不允许看产品
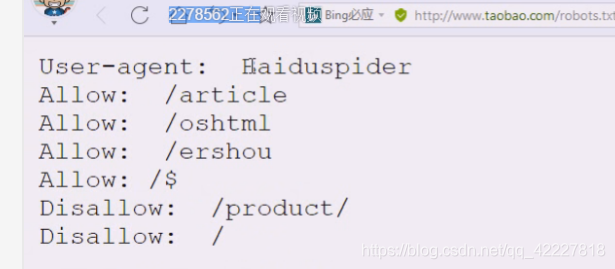
google却可以看,但是google比较不守国家规矩
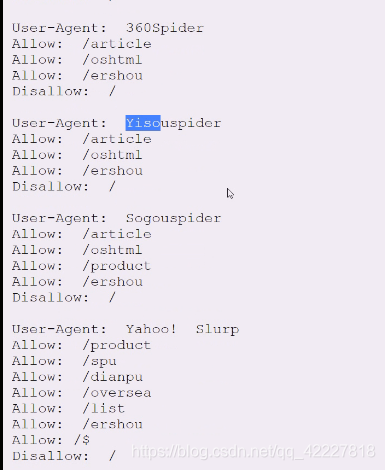
对每个搜索引擎的欢迎程度是不一样的
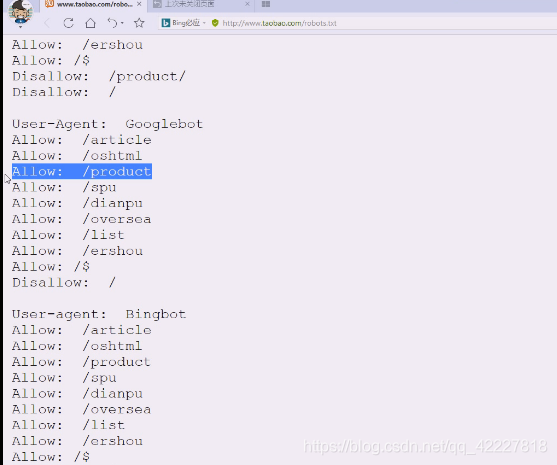
bing这边也是相对比较宽松的


看一下马蜂窝的
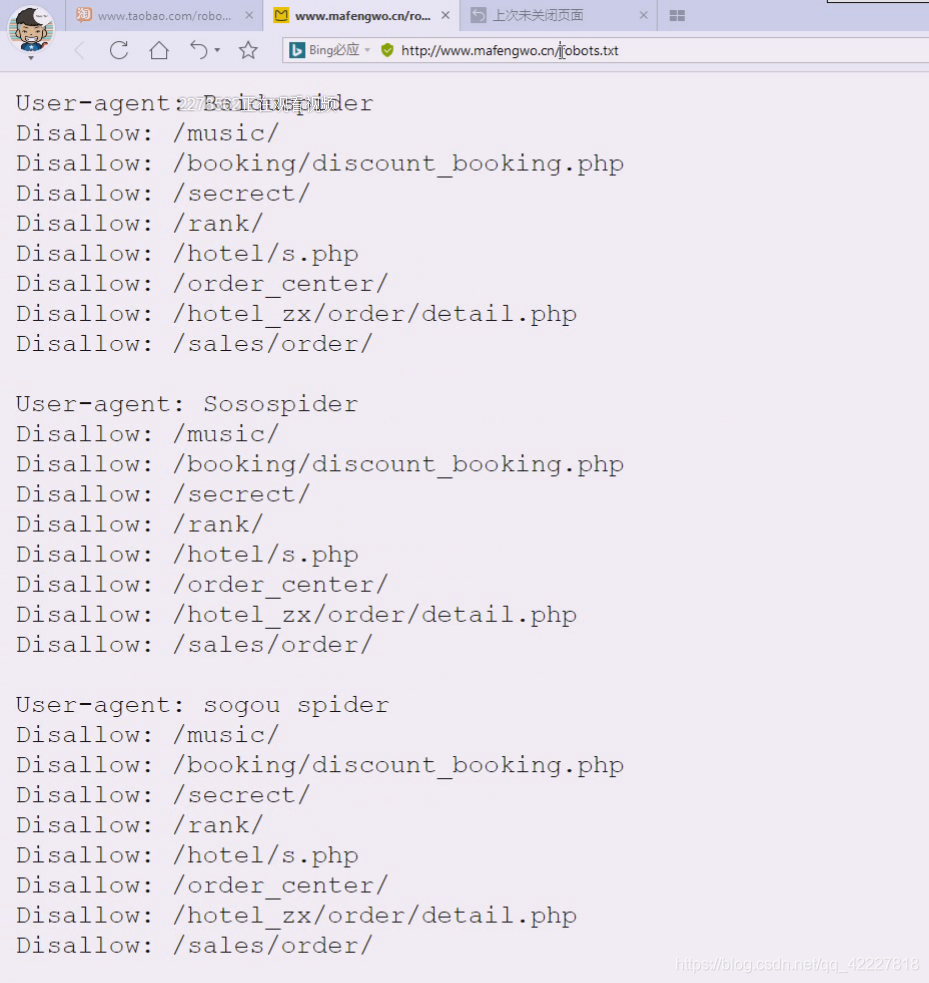
这是告诉你禁止爬的,但是这是君子协定,可以忽视它,但是你要小心,不要让别人告你上法庭
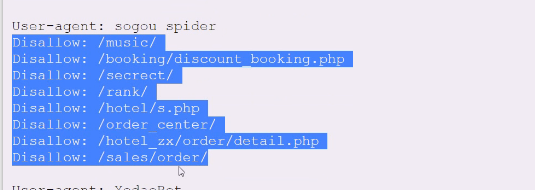
马蜂窝就是靠游记活的,它其实还是希望搜索引擎爬取游记然后指向马蜂窝这个网站
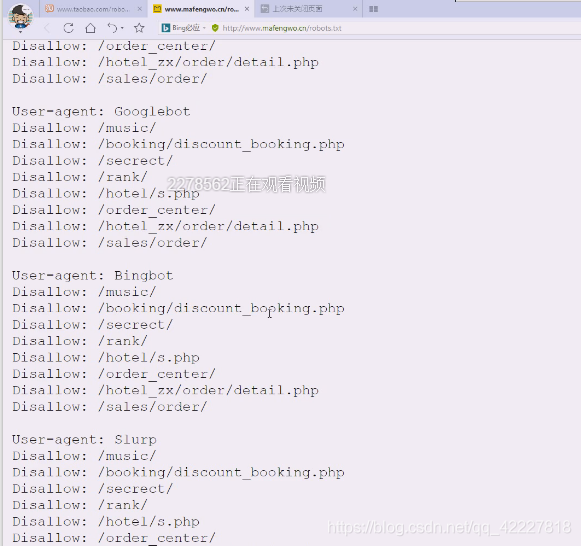
**通配符,如果不是上面的spider爬虫的话,浏览器除外,因为浏览器是通过连接来看的,不是爬的 **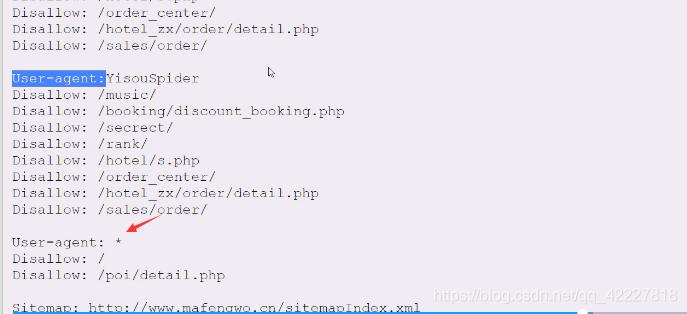
其他浏览器,从根开始都不允许,其他的spider就告诉哪些允许,其他都是允许的,对于上面的其他搜索引擎,要求你什么都不能访问,也就是不欢迎你搜索引擎。
这个是君子协定,不做强制性要求,只要是浏览器能做的事情,爬虫都能做

为了预防某些人乱爬网站,提供了另外的东西,站点 地图

这是一个xml
看看这里有什么
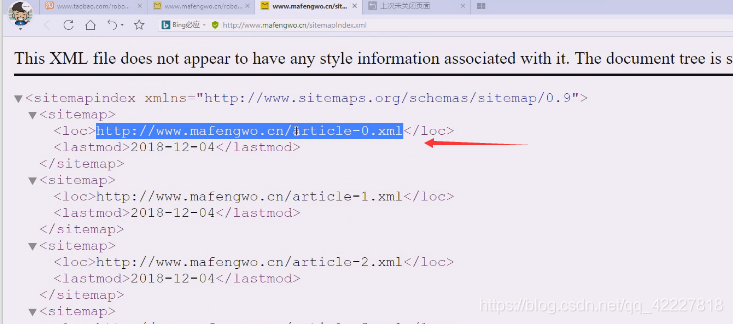
这个文件很大
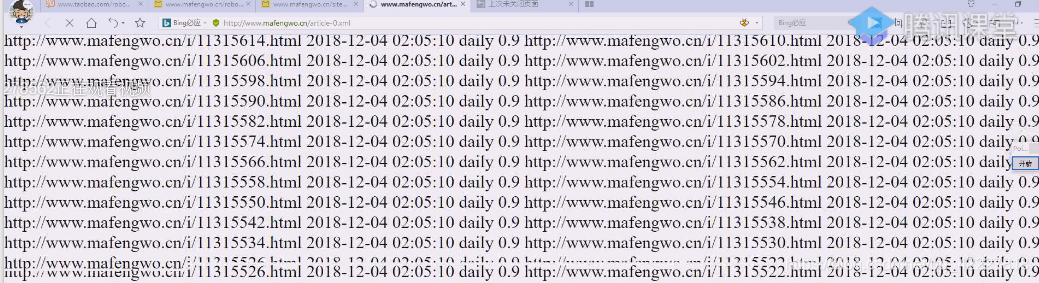
告诉你哪些文章,这些文章什么时候发表的信息全部提供给你,让你不要乱爬了,马蜂窝是依靠游记生存的网站
这些里面是什么允许爬,什么不允许爬,
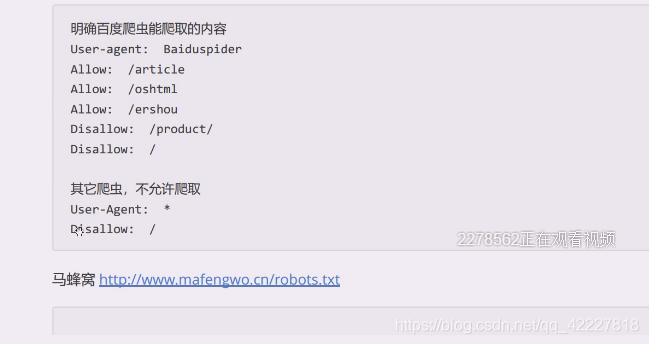
这个是基本上其他爬虫都不允许的,这个是让对爬虫遵守的规则

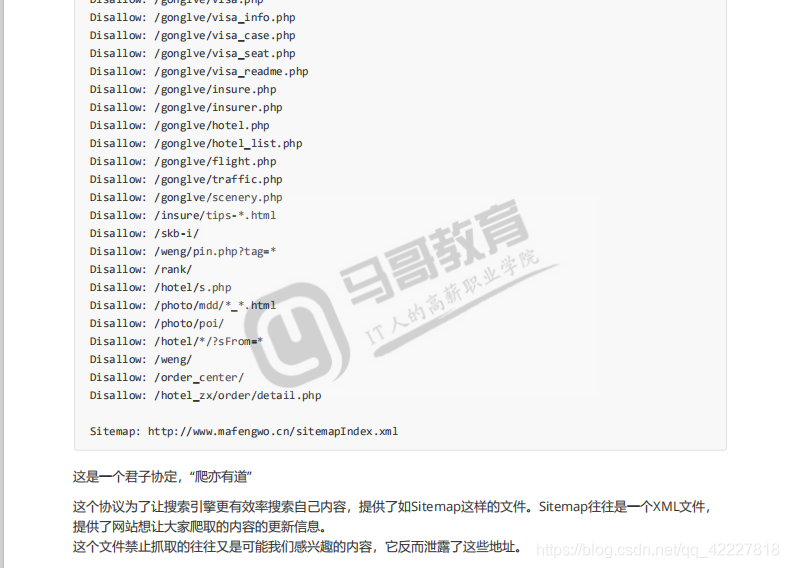
这是君子协定,不是强制性的,但是不要违反,有些会告你的,京东应该是基本上都不允许,因为它认为想要看就到京东来,淘宝就开发比较多,所以每家企业不一样。
想要更有效率就提供了sitemap站点地图来查,不管怎么样还是要去遵守君子协定,避免法定纠纷

如何发起一个http请求,之前是用测试工具或者浏览器,python也提供了这样的库,最有名的就是urllib库,标准库,也就是python自带,
包含 了4个子包,分别是request,error,parse,robotparser
request管l理请求
error管异常
parse管url解析的
robotprser分析robots,分析robots文件的,直接调用构造函数,read就可以读到了

python2里是两个库,python3将这两个库合并了,更名了urllib包(是urllib和urllib2的 合体)

与请求相关的是request模块,这个模块提供了请求相关的方法和类,我们只需要把方法学会即可。我们用浏览器就要告诉别人网站本人不是爬虫,就是useragent,是放在header中的,需要改头。之前用postman是因为是自己的网站,但是试其他网站就知道你是爬虫,用的urllib,几下就把你禁止了

request有个方法最常用,urlopen,两个 参数,给个url打开就是了 ,第二个参数data,意思就是数据,只要给数据就是post方法,只要data是none就是get方法。会返回一个响应对象,是http.client.HTTPResponse类,是放在http.client.HTTPResponse类里了,这个类是一个类文件对象

写一个简单例子试试

先定义一个url,访问www.bing.com肯定301,让你访问中国区的,response对象是一个类文件对象,文件对象都可以打开关闭,可以用with语法,enter和exit。
先打印类型看看。
错误,301其实是发了两次请求

现在这样就可以,301是发了两次请求,先一个域名给了回应,response的header里有location,301,告诉永久重定向了,再发起请求,
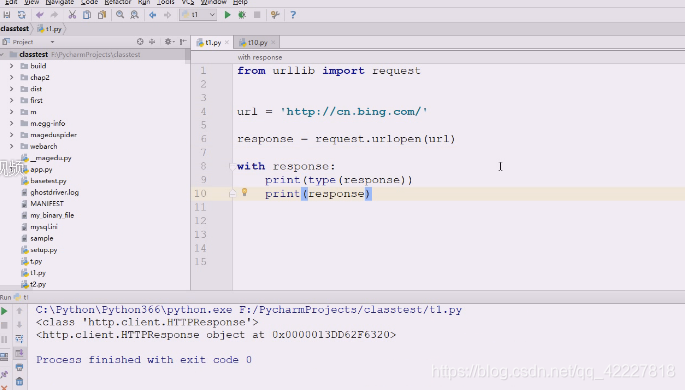
3.6 可以这么写,直接httpresponse,这是response的header
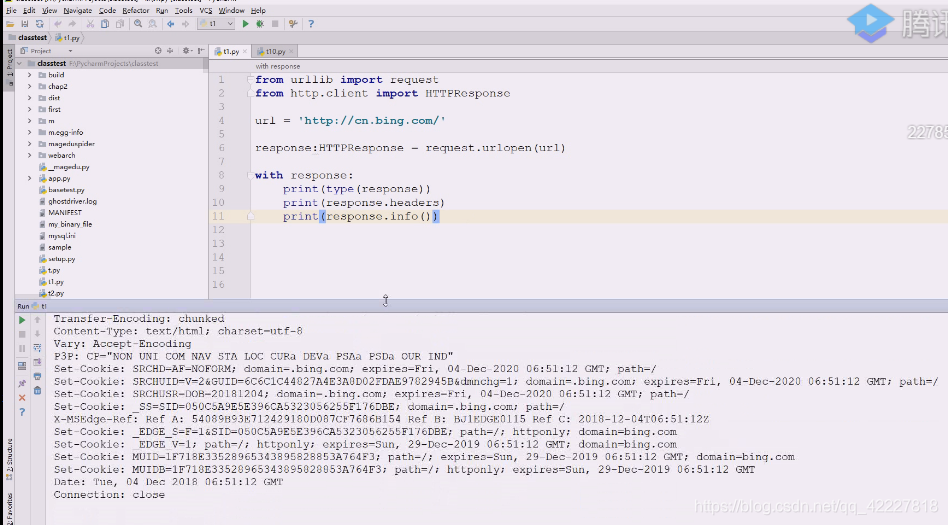
这两个是一样的,headers和info
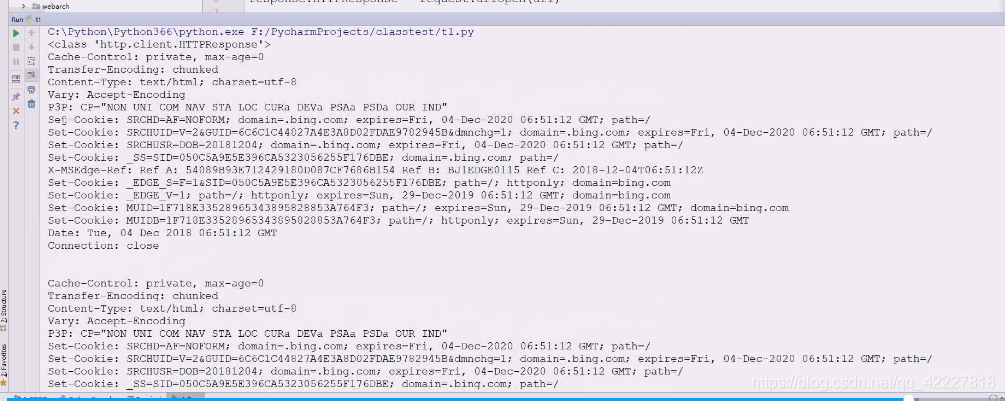
看到了大量的set-cookie,维护一些状态
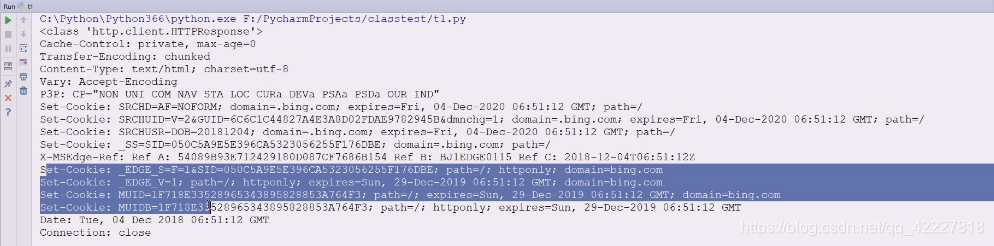
status状态码,reason原因,描述说明,最后地址跟你输入地址不一样
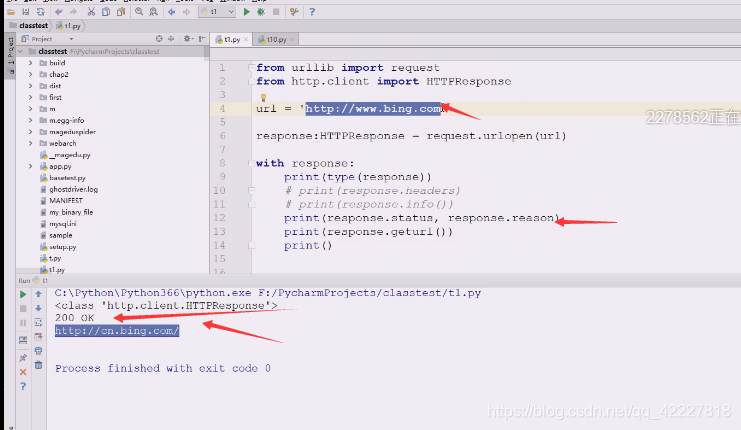
所以最后的url往往是跳转完的地址

fileno是文件描述符,至少是个文件对象
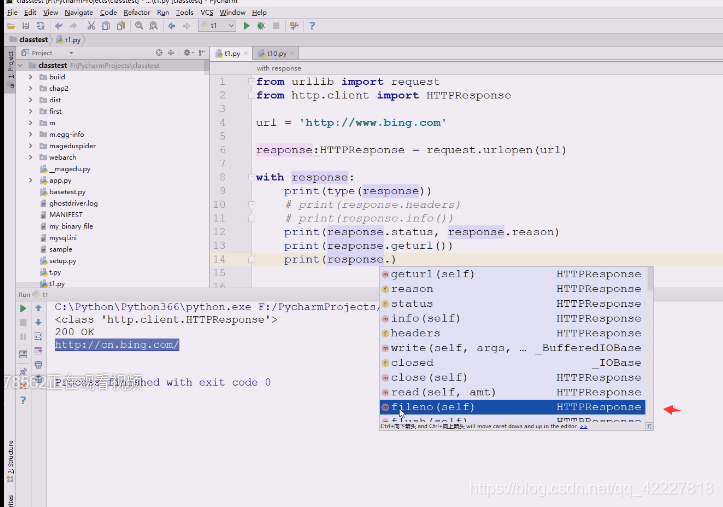
如何去拿里面的数据,看一下httpresponse
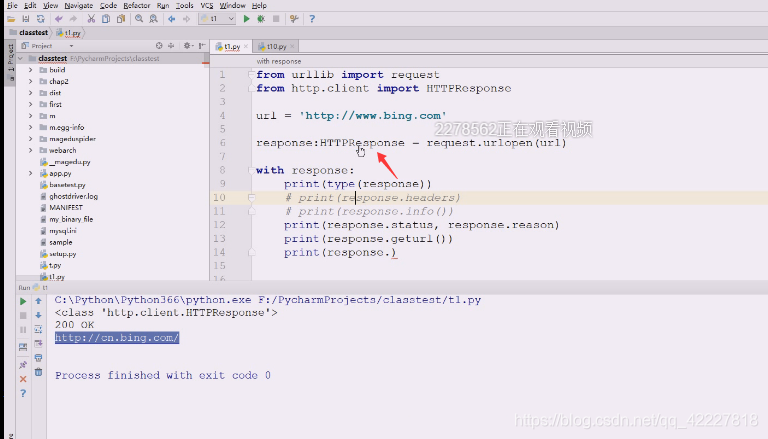
定个位看看,好像没有特别的属性,

init里也没有,没有data,text,让我们能拿到数据的东西
往下看也没有property装饰器,就看到了read
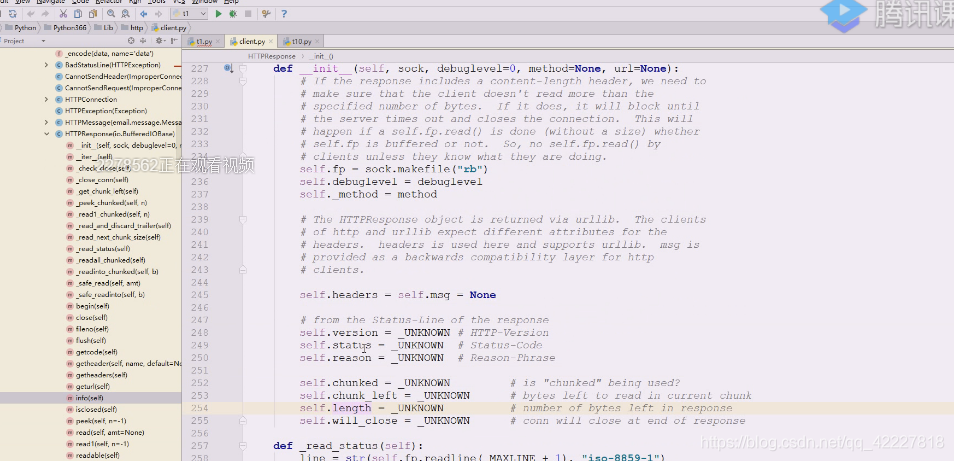
看read,如果fp是个none,head就是简化版的get方法

,head就是简化版的get方法

文件对象的read,在反复读
它返回的是文件对象,在这个文件一个个就把对方send回来的数据read出来了
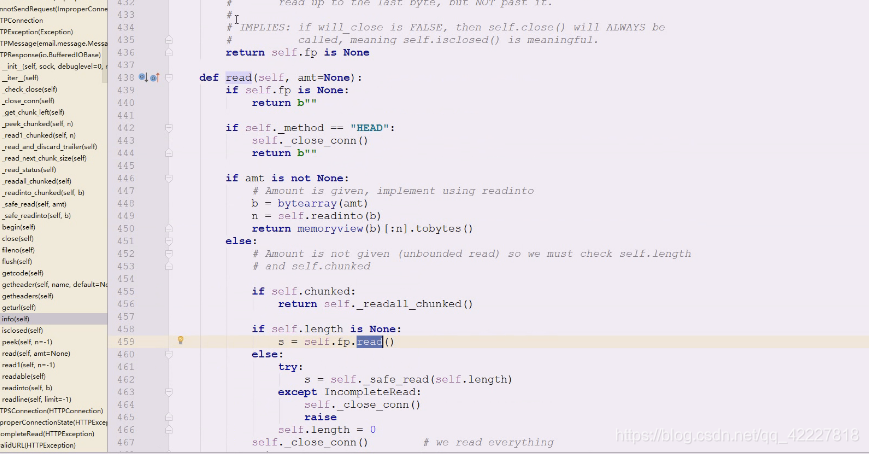
直接read即可,bytes的,文件默认用二进制的读,这里相当于看到了返回的网页内容
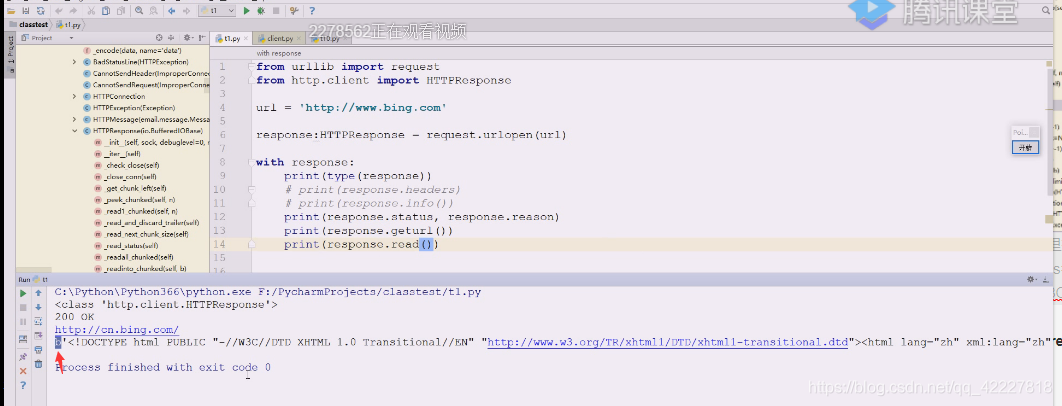
爬虫的第一步做到了,从服务器get方法获取一个网页出来
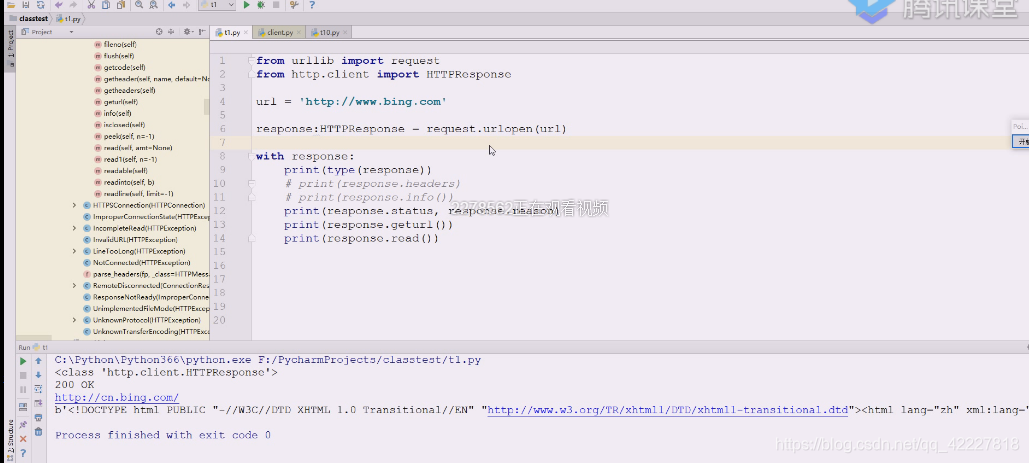
但是这样对react写的SPA(单网页应用没什么用,就一个网页引用了一个script没了),所以对SPA和异步调用的还需要想办法
