Java爬虫
Java使用WebMagic爬取小说数据
最近在上课过程中发现很多同学对爬虫比较感兴趣,而且很多同学也陷入了一个误区,认为只有Python能够写爬虫,只有Python能够爬取数据,甚至还有一部分同学认为Python只要会爬虫了就已经很厉害了,就已经把Python学好了,就可以很着躺了,我只能说还是太年轻太天真呀
好了,话不多说直接上代码,基于Java来写的一个爬虫,爬取某点网的小说
/**
* @author Mr.Zhou
* 2020年4月4日 12:30:25
*/
public class GetQiDian implements PageProcessor{
//设置待爬取文件的相关配置
private Site site = Site.me()
.setCharset("utf-8")//设置字符集
.setTimeOut(10000)//设置超时时间
.setSleepTime(1000);//设置休眠时间
//书的名字
String bookName = "";
@Override
public Site getSite() {
return site;
}
//爬取数据的逻辑
//第一级url https://www.qidian.com/xuanhuan 此URL是为了获取书的目录
//第二级url https://book.qidian.com/info/1019251979#Catalog 章节目录
// https://book.qidian.com/info/1017585246#Catalog
//第三级url https://read.qidian.com/chapter/SaT8jsiJD54smgY_yC2imA2/oQbX6YtwB_NOBDFlr9quQA2 文章
// https://read.qidian.com/chapter/SaT8jsiJD54smgY_yC2imA2/DQlxXvcO0OT6ItTi_ILQ7A2
//https://read.qidian.com/chapter/SaT8jsiJD54smgY_yC2imA2/DQlxXvcO0OT6ItTi_ILQ7A2
//https://read.qidian.com/chapter/SaT8jsiJD54smgY_yC2imA2/DQlxXvcO0OT6ItTi_ILQ7A2
@Override
public void process(Page page) {
//获取url
Selectable table = page.getUrl();
System.out.println(table);
//url匹配
if(table.regex("https://read.qidian.com/chapter/.{23}/.{23}").match()){//文章
//获取html页面信息
Html html = page.getHtml();
// System.out.println(html);
// System.out.println(html.xpath("/html/body/div[2]/div[3]/div[2]/div[1]/div[1]/div[1]/div[1]/h1/text()").toString());
//章节标题
String title = "";
//内容集合
List<String> content = new ArrayList<String>();
//抓取有用的信息
//判断是否是第一章
if(html.xpath("/html/body/div[2]/div[3]/div[2]/div[1]/div[1]/div[1]/div[1]/h1/text()").toString() != null ){//是第一章
//获取书名
bookName = html.xpath("/html/body/div[2]/div[3]/div[2]/div[1]/div[1]/div[1]/div[1]/h1/text()").toString();
// System.out.println(bookName);
//获取章节名
title = html.xpath("[@class='main-text-wrap']/div[1]/h3/span/text()").toString();
// System.out.println(title);
//获取文章内容
content = html.xpath("[@class='main-text-wrap']/div[2]/p/text()").all();
}else{//不是第一章
//获取章节名
title = html.xpath("[@id='j_chapterBox']/div[1]/div[1]/div[1]/h3/span/text()").toString();
//获取文章内容
content = html.xpath("[@id='j_chapterBox']/div[1]/div[1]/div[2]/p/text()").all();
}
//存到本地
downBook(bookName,title,content);
}else if(table.regex("https://book.qidian.com/info/\\d{10}#Catalog").match()){//书的章节目录
//获取每一章节的地址
List<String> url = page.getHtml().xpath("[@class='volume-wrap']/div[1]/ul/li/a/@href").all();
//加入待爬取序列
page.addTargetRequests(url);
}else{//一级url
//获取Html页面
Html html = page.getHtml();
//解析出每本书的url
List<String> url = html.xpath("[@id='new-book-list']/div/ul/li/div[2]/h4/a/@href").all();
//拼接成完整的路径
List<String> url2 = new ArrayList<String>();
for (String string : url) {
url2.add(string + "#Catalog");
}
//加入待爬取序列
page.addTargetRequests(url2);
}
}
//将书存入本地
private void downBook(String bookName2, String title, List<String> content) {
//判断书名目录存不存在
File file = new File("D:/book/" + bookName2);
if(!file.exists()){
//创建目录
file.mkdirs();
}
//使用IO流
PrintWriter pw = null;
//输出流
try {
//按照书名和分章节存入到本地
FileOutputStream fos = new FileOutputStream("D:/book/" + bookName2 + "/" + title + ".txt");
pw = new PrintWriter(fos,true);
for (String string : content) {
pw.println(string);
}
System.out.println("爬取完毕");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if(pw != null)pw.close();
}
}
//程序的主入口
public static void main(String[] args) {
Spider.create(new GetQiDian()).thread(1).addUrl("https://www.qidian.com/xuanhuan").run();
}
}
OK,到此运行main方法就可以爬取到某点网的小说了,上面的代码是爬取某点网中玄幻新书,就用到了WebMagic框架和IO流就可以了,既然使用WebMagic框架的话就需要用到相关依赖。
如果你使用Maven构建项目的话,在你自己的项目(已有项目或者新建一个)中添加以下坐标即可:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
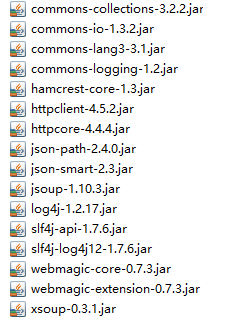
如果不使用Maven的话则需要手动导入一下依赖jar包文件
写的不好勿喷,有不懂的地方可以关注楼主欢迎留言讨论,也可以加楼主扣扣1878784146
