1.需求:
根据上一篇博文统计手机号耗费的总上行流量、下行流量、总流量(序列化)产生的结果再次对总流量进行排序。
2.数据准备:
上一篇博文产生的数据:
13480253104 180 180 360
13502468823 7335 110349 117684
13560436666 3597 25635 29232
13560439658 2034 5892 7926
13602846565 1938 2910 4848
13660577991 6960 690 7650
13719199419 240 0 240
13726230503 2481 24681 27162
13760778710 120 120 240
13826544101 264 0 264
13922314466 3008 3720 6728
13925057413 11058 48243 59301
13926251106 240 0 240
13926435656 132 1512 1644
15013685858 3659 3538 7197
15920133257 3156 2936 6092
15989002119 1938 180 2118
18211575961 1527 2106 3633
18320173382 9531 2412 11943
84138413 4116 1432 5548
3.分析:
(1)把程序分两步走,第一步正常统计总流量,第二步再把结果进行排序
(2)context.write(总流量,手机号)
(3)FlowBean实现WritableComparable接口重写compareTo方法
@Override
public int compareTo(FlowBean o) {
//倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}4.代码实现:
(1)FlowBean类:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/14 & 1.0
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upflow;
private long downflow;
private long sumflow;
//定义空参构造器,反序列化需要
public FlowBean(){
}
public FlowBean(long upflow,long downflow,long sumflow){
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = sumflow;
}
//自定义比较器,倒序排序
public int compareTo(FlowBean o){
if (this.sumflow > o.sumflow){
return -1;
}else if (this.sumflow < o.sumflow){
return 1;
}else {
return 0;
}
}
// 序列化 注意:反序列化顺序和序列化循序是对应
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upflow);
dataOutput.writeLong(downflow);
dataOutput.writeLong(sumflow);
}
//反序列化
public void readFields(DataInput dataInput) throws IOException {
this.upflow = dataInput.readLong();
this.downflow = dataInput.readLong();
this.sumflow = dataInput.readLong();
}
//重写toString,用来输出
public String toString(){
return this.upflow + "\t" + this.downflow + "\t" + this.sumflow;
}
}
(2)WritableComparableMapper类:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/14 & 1.0
*/
public class WritableComparableMapper extends Mapper<LongWritable, Text,FlowBean,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取数据
String line = value.toString();
//切分
String[] splits = line.split("\t");
context.write(new FlowBean(Long.parseLong(splits[1]),Long.parseLong(splits[2]),Long.parseLong(splits[3])),new Text(splits[0]));
}
}(3)WritableComparableReducer类:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/14 & 1.0
*/
public class WritableComparableReducer extends Reducer<FlowBean, Text,Text,FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text t : values){
context.write(t,key);
}
}
}(4)WritableComparableDriver类:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/14 & 1.0
*/
public class WritableComparableDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"D:\\input\\plus\\output\\0819", "D:\\input\\plus\\output\\0820"};
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(WritableComparableDriver.class);
// 3 关联map和reduce
job.setMapperClass(WritableComparableMapper.class);
job.setReducerClass(WritableComparableReducer.class);
// 4 设置最终输出类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
5.运行结果:
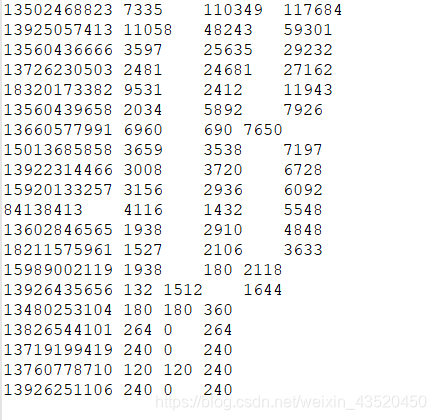
至此,完成倒序排序。