文件的打开
文件处理的步骤:打开、操作、关闭,打开文件是第一步。
open() 将会返回一个 file 对象,基本语法格式如下:
open(<文件名>, <打开模式>)
文件名:文件路径和名称(源文件同目录可省路径)
Windows下文件路径是使用反斜杠方式,但python中的反斜杠\表示转义符,双反斜杠表示反斜杠。所以路径里的反斜杠我们可以用斜杠/或双反斜杠表示。
打开模式:只读r,写入w,追加a等。
打开之后将返回一个文件对象(file object),后续对文件内数据的操作都是基于这个文件对象的方法(method)来实现的。
举个例子:
(这里我在桌面上创建了一个名为a的文本文件,里面内容是张若虚的春江花月夜)
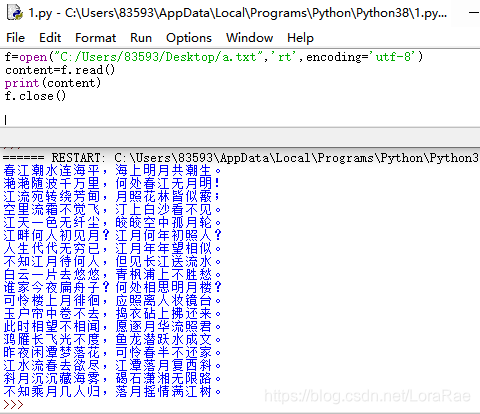
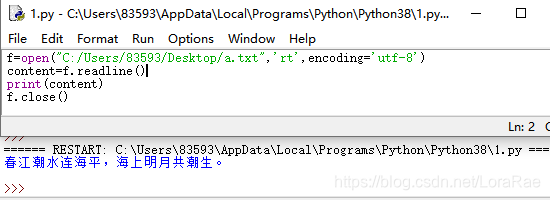
f=open("C:/Users/83593/Desktop/a.txt",'rt',encoding='utf-8')
content=f.read()
print(content)
f.close()
注:win系统下读文件默认是gbk读取文件,但是读取的文件时utf-8保存的,所以open里面加了encoding=‘utf-8’。
运行结果:
打开模式分类:
| 文件的打开模式 | 描述 |
|---|---|
| ‘r’ | 只读模式,默认值,如果文件不存在,返回FileNotFoundError |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回FileExistsError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与r/w/x/a一同使用,在原功能基础上增加同时读写功能 |
f = open(“f.txt”) -文本形式、只读模式、默认值
f = open(“f.txt”, “rt”) -文本形式、只读模式、同默认值
f = open(“f.txt”, “w”) -文本形式、覆盖写模式
f = open(“f.txt”, “a+”) -文本形式、追加写模式+ 读文件
f = open(“f.txt”, “x”) -文本形式、创建写模式
f = open(“f.txt”, “b”) -二进制形式、只读模式
f = open(“f.txt”, “wb”) -二进制形式、覆盖写模式
文件的关闭
<变量名>.close()
也可以使用 with open() as f: 在操作后自动关闭文件
with open("C:/Users/83593/Desktop/a.txt",'rt',encoding='utf-8') as f:
content=f.read()
print(content)
文件内容的读取
| 方法 | 含义 |
|---|---|
| < file >.readall() | 读入整个文件内容,返回一个字符串或字节流 |
| < file >.read(size) | 从文件中读入整个文件内容,如果给出参数,读入前size长度的字符串或字节流 |
| < file >.readline(size) | 从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或字节流 |
| < file >.readlines(hint) | 从文件中读入所有行,以每行为元素形成一个列表,hint参数可以指定提示来控制读取的行数 |
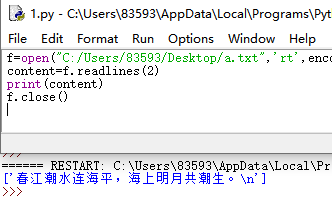
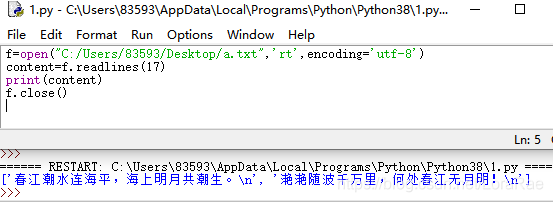
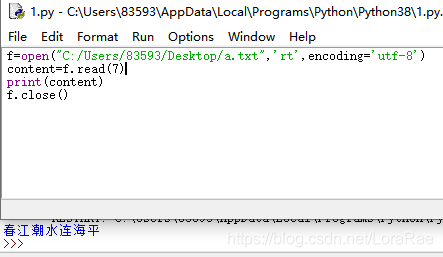
这里要注意,参数hint并不是直接指示所对应的行数,hint参数是字节的总大小,会读取到该文件内对应字节数的当前行。
如:
hint为2时:
hint为7时:

hint为17时,才读取了下一行:
读取文件的例子:
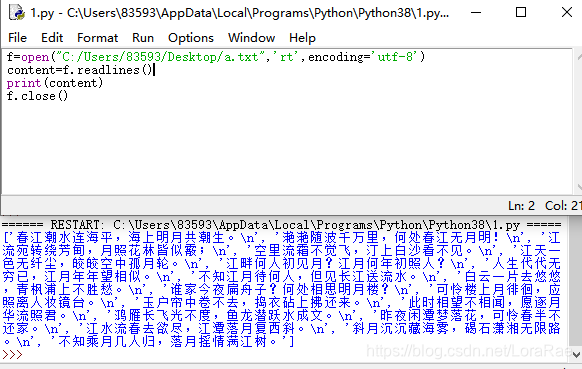
readlines() 读取后得到的是每行数据组成的列表,但是一行样本数据全部存储为一个字符串,并且数据读入后并没有将换行符去掉。
解决方法:在读入数据之后,用 for 循环对每一个元素去除换行符,并将每一个变量
值用字符串处理方法 .split() 分隔。
(.strip() 本身是一个对字符串去除指定字符的方法括号里参数为空的时候,就会去除 \r \n \t。)
f=open("C:/Users/83593/Desktop/a.txt",'rt',encoding='utf-8')
content=f.readlines()
f.close()
content_new=[ ]
for con in content:
tmp=con.strip()
tmp=tmp.split(',')
content_new.append(tmp)
print(content_new)
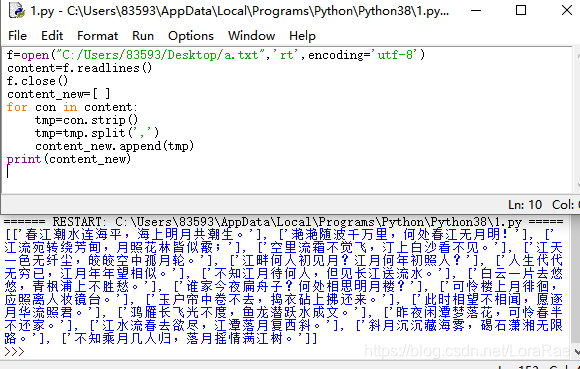
逐行操作:
f=open("C:/Users/83593/Desktop/a.txt",'rt',encoding='utf-8')
for line in f.readlines():
print(line)
f.close()
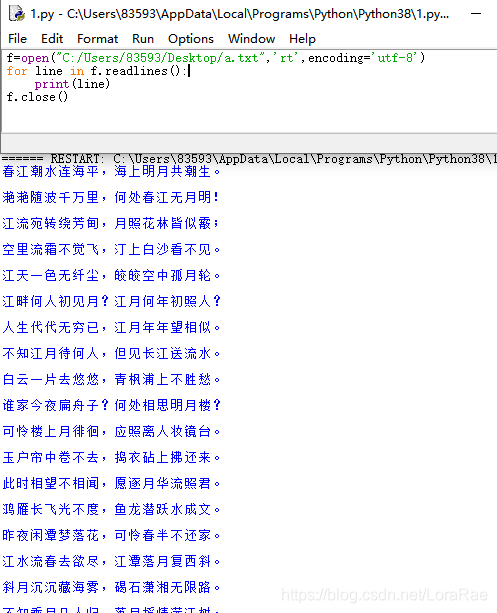
数据的文件写入
| 方法 | 描述 |
|---|---|
| write() | 向文件写入一个字符串或字节流 |
| writelines() | 可对一个列表里的所有数据一次性写入文件中 |
| seek(offset,whence) | 改变当前文件操作指针的位置,offset代表文件指针的偏移量,单位是字节bytes。whence代表参照物,有三个取值(1)0:参照文件的开头(2)1:参照当前文件指针所在的位置(3)2:参照文件末尾 ( 强调:其中whence=1和whence=2只能在b 模式下使用 ) |
例子:
f=open("C:/Users/83593/Desktop/a.txt",'wt',encoding='utf-8')
f.write('Hello world')
f.close()
f=open("C:/Users/83593/Desktop/a.txt",'wt',encoding='utf-8')
ls=['中国','法国','美国']
f.writelines(ls)
f.close()

以上是覆盖写模式。也可改为追加写模式:
f=open("C:/Users/83593/Desktop/a.txt",'a',encoding='utf-8')
f.writelines('11111')
f.close()
