在日常工作中,有时可能需要解析一些 PDF 文件,提取文件中的关键词,好让它们能够被我们搜索。解决这个问题的重要部分就是找到如何从 PDF 文件中提取文本数据的方法。从如果是几张或者几十张倒还好办,那要是几百几千张,可能就有点麻烦了。

幸好我们可以用 Python 完成这项工作。下面就分享一下如何用 Python 解析一个PDF文件,将其转为一列关键字。
设置:
本教程我们使用的是 Python 3.6.3,当然在实际工作中你可以使用任何你喜欢的 Python 版本,只要它支持用到的库就行。
需要安装以下 Python 库:
PyPDF2(用于将简单的基于文本的 PDF 文件转为 Python 可读的文本)
Textract(用于将 PDF 扫描文件转为 Python 可读的文本)
Nltk(用于清理短语、将短语转为关键字)
可以通过以下命令行安装这些库:
pip install PyPDF2
pip install textract
pip install nltk
这样我们就安装了解析 PDF 文件所需的库,一定要确保你的 PDF 文件放在你编写脚本所在的文件夹中。
启动编辑器,开始敲代码吧!
第一步:导入库

第2步:读取 PDF 文件
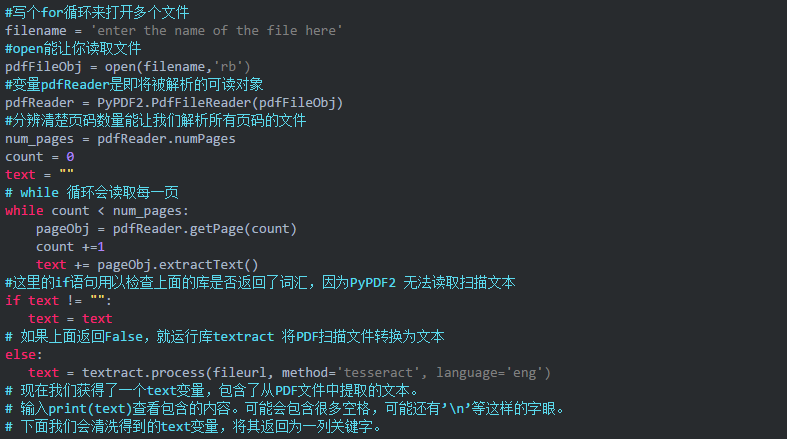
第3步:将文本转换为关键字

现在我们就将手中的 PDF 文件保存为了列表,可以按自己的需要使用了。如果想让 PDF 可搜索,或者解析大量文件进行聚类分析,还可以将得到的列表保存在电子表格中。