pytorch小试
之前一直使用Tensorflow写程序,今天初学pytorch来实现一个简单的回归模型。回归模型即给定一组样本特征 (相当于超空间中的点),训练一个简单的线性函数来拟合它们 。
普通的写法:
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
criterion = nn.MSELoss()
# 事先定义好特征x和回归值y,w和b为预设的参数,后续的init_w和init_b目标是拟合它们
# x为三维向量,一共10个样本,输出的y是一个数值
x = torch.rand(10,3)
w = torch.tensor([[2.,1.,-4.]])
b = torch.tensor(2.8)
y = w.mm(x.permute(1,0)) + b
print(x.size())
print(y.size())
print(y)
# 初始化训练的参数init_w 和init_b
init_w = torch.normal(mean=0.5, std=torch.tensor([[1,2,3]], dtype=torch.float))
init_w = Variable(init_w, requires_grad=True)
init_b = torch.rand(1,1)
init_b = Variable(init_b, requires_grad=True)
# 设定优化方法
optimizer = optim.SGD((init_w,init_b), lr=0.05)
# 设置迭代次数
for i in range(2000):
# output
y_hat = init_w.mm(x.permute(1,0)) + init_b
# 计算loss
loss = criterion(y_hat, y)
print(i, 'th: loss=', loss)
# 清除计算的梯度
optimizer.zero_grad()
# 计算梯度
loss.backward(retain_graph=True)
# 更新参数
optimizer.step()
#输出训练后的结果
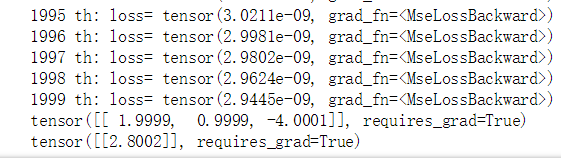
print(init_w)
print(init_b)
继承 torch.nn.Module 写法:
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
# 事先定义好特征x和回归值y,w和b为预设的参数,后续的init_w和init_b目标是拟合它们
# x为三维向量,一共10个样本,输出的y是一个数值
x = torch.rand(10,3)
w = torch.tensor([[2.,1.,-4.]])
b = torch.tensor(2.8)
# y=wx+b
y = w.mm(x.permute(1,0)) + b
# 模型类(一个线性回归函数)
class Regress(nn.Module):
def __init__(self):
super(Regress, self).__init__()
self.init_w = torch.normal(mean=0.5, std=torch.tensor([[1,2,3]], dtype=torch.float))
self.init_w = Variable(self.init_w, requires_grad=True)
self.init_w = nn.Parameter(self.init_w)
self.init_b = torch.rand(1,1)
self.init_b = Variable(self.init_b, requires_grad=True)
self.init_b = nn.Parameter(self.init_b)
self.criterion = nn.MSELoss()
self.optim = optim.SGD(self.parameters(), lr=0.05)
def forward(self, input):
y = self.init_w.mm(input.permute(1,0)) + self.init_b
return y
# 创建类对象,初始化相关变量与函数
net = Regress()
# 迭代训练(迭代次数可自调)
for i in range(2000):
y_hat = net.forward(x)
loss = net.criterion(y_hat, y)
print(i, 'th: loss=', loss)
net.optim.zero_grad()
loss.backward(retain_graph=True)
net.optim.step()
# 打印结果
print(init_w)
print(init_b)
运行结果: