PyTorch数据准备
简介
没有数据,所有的深度学习和机器学习都是无稽之谈,本文通过Caltech101图片数据集介绍PyTorch如何处理数据(包括数据的读入、预处理、增强等操作)。
数据集构建
本文使用比较经典的Caltech101数据集,共含有101个类别,如下图,其中BACKGROUND_Google为杂项,无法分类,使用该数据集时删除该文件夹即可。
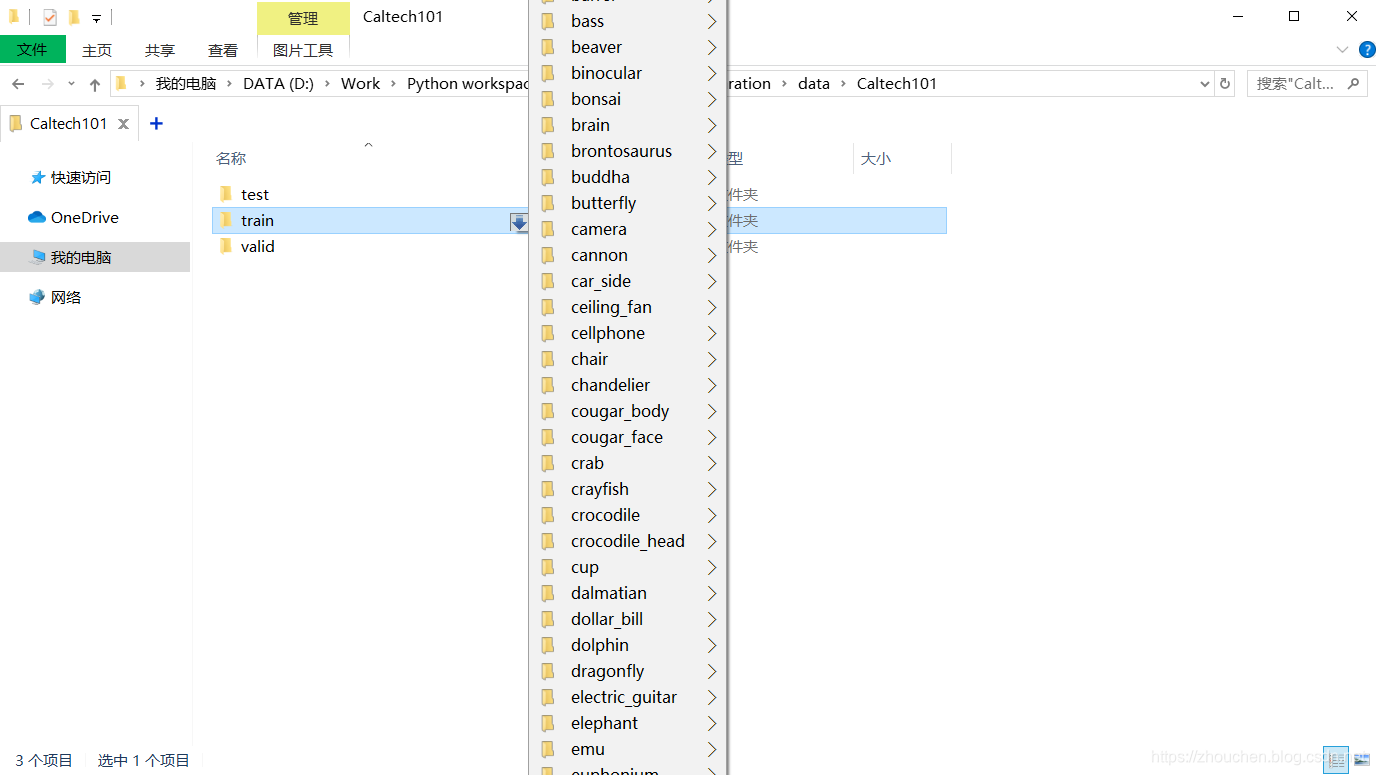
对数据集进行划分,形成如下格式,划分为训练集、验证集和测试集,每一种数据集中每个类别按照8:1:1进行数据划分,具体代码见scripts/dataset_split.py。
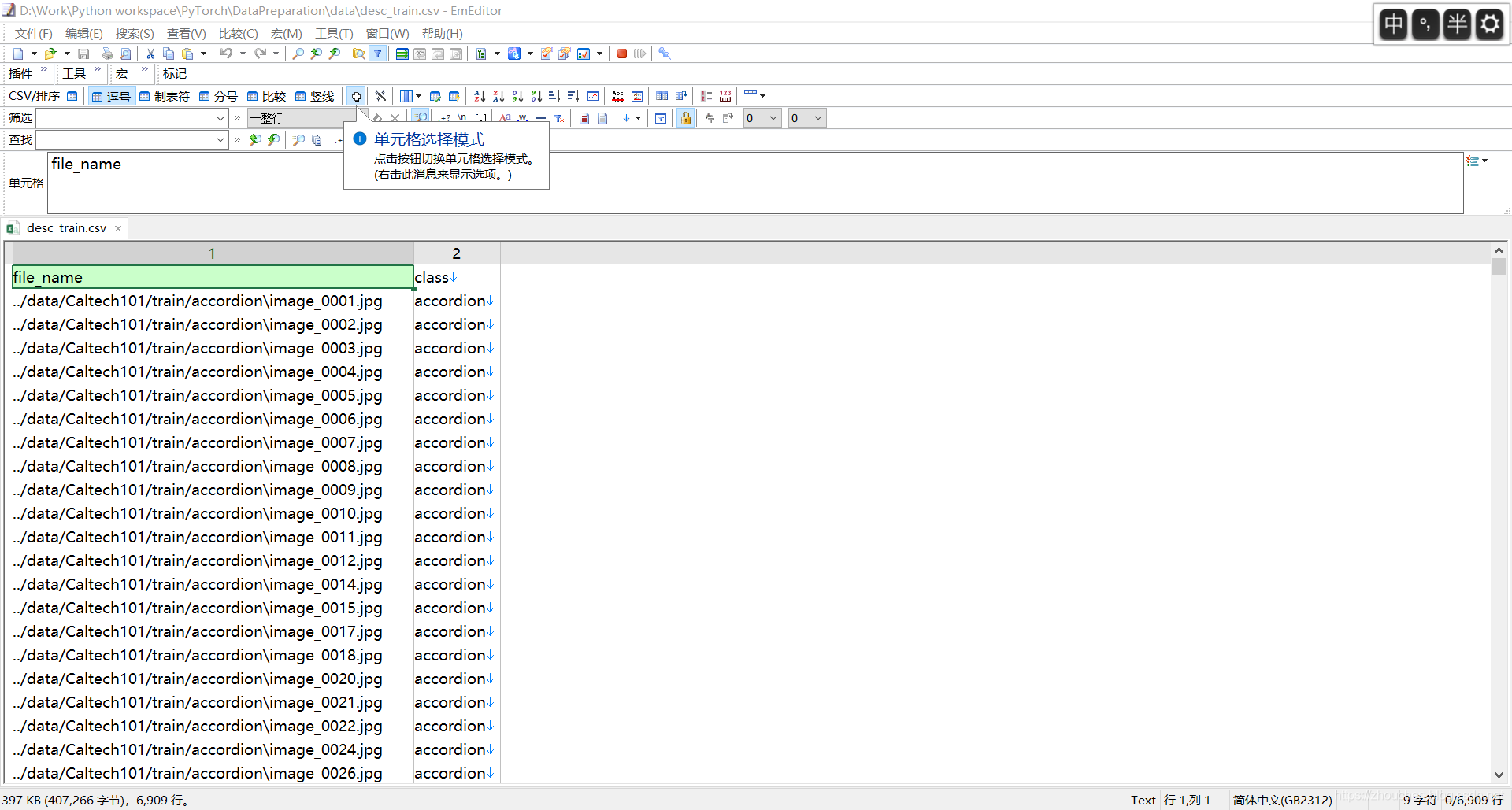
数据划分完成后就要制作相关的数据集说明文件,在很多大型的数据集中经常看到这种文件且一般是csv格式的文件,该文件一般存放所有图片的路径及其标签。生成了三个说明文件如下,图中示例的是训练集的说明文件。这部分的具体代码见scripts/generate_desc.py。
PyTorch数据读取API
上面构造了比较标准的数据集格式和主流的数据集说明文件,那么PyTorch如何识别这种格式的数据集呢?事实上,PyTorch对于数据集导入进行了封装,其API为torch.utils.data中的Dataset类,只要继承自该类即可自定义数据集。
需要注意的是Dataset类的最主要的重载方法为__getitem__方法,该方法需要传入一个index的list(索引的列表),根据该列表去取出多个数据元素,每个元素是一个样本(这里指图片和标签)。
下面的代码构建了一个最简单的Dataset,事实上训练时需要定义很多预处理和增强方法,这里略过。
from torch.utils.data import Dataset
import pandas as pd
from PIL import Image
class MyDataset(Dataset):
def __init__(self, desc_file, transform=None):
self.all_data = pd.read_csv(desc_file).values
self.transform = transform
def __getitem__(self, index):
img, label = self.all_data[index, 0], self.all_data[index, 1]
img = Image.open(img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.all_data)
if __name__ == '__main__':
ds_train = MyDataset('../data/desc_train.csv', None)
在成功构建这个Dataset之后就是将这个Dataset对象交给Dataloader,实例化的Dataloader会调用Dataset对象的__getitem__方法读取一张图片的数据和标签并拼接为一个batch返回,作为模型的输入。

下面示例讲解如何在PyTorch中读取数据集。
- 首先,需要构造Dataset对象,该对象定义了本地数据的路径和图片的转换方法(预处理方法)。这里提一下,这个数据转换的方法是一个
transforms.Compose对象,它从一个列表构建,列表中每个元素是一种处理方法。 - 接着,构造Dataloader对象,该对象成批调用Dataset对象的
__getitem__方法获得批量变换后的数据返回,用于模型训练。 - 训练完成,释放内存,进行下一批数据读取。
实验效果如下,可以看到,按批次取出了数据和标签。

其代码如下。
from my_dataset import MyDataset
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
desc_train = '../data/desc_train.csv'
desc_valid = '../data/desc_valid.csv'
batch_size = 16
lr_init = 0.001
epochs = 10
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
train_transform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(normMean, normStd) # 按照imagenet标准
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(normMean, normStd)
])
# 构建MyDataset实例
train_data = MyDataset(desc_train, transform=train_transform)
valid_data = MyDataset(desc_valid, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=batch_size)
for epoch in range(epochs):
for step, data in enumerate(train_loader):
inputs, labels = data
print("epoch", epoch, "step", step)
print("data shape", inputs.shape, labels.shape)
数据增强
在实际使用中,数据进入模型之前会进行一些对应的预处理,如数据中心化、数据标准化,随机裁减、图片旋转、镜像翻转,PyTorch预先定义了诸多数据增强方法,这些都放在torchvision的transforms模块下。官方文档只是罗列了相关API,没有按照逻辑整理,其实数据增强主要有四大类。
- 裁减
- 转动
- 图像变换
- transform操作
下面逐一介绍。
裁减(Crop)
- 随机裁减
transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')- 根据给定的size进行随机裁减。
- size参数为裁减后的图像尺寸,为元组或者整型数,若为元组要符合
(height, width)格式,若int型数则自动按照(size, size)进行长宽设定。 - padding参数设置需要填充多少个像素,为元组或者整形数,若为整形数则图像上下左右填充
padding个像素,若两个数字的元组则第一个数字表示左右第二个数字表示上下,若四个数字则分别表示上下左右填充的像素个数。 - fill参数设置填充的值是什么,为整型或者元组只有
padding_mode为constant时有效,当int时,各个通道填充该值,三个数的元组时RGB三通道分别填充。 - padding_mode参数设置填充模式,
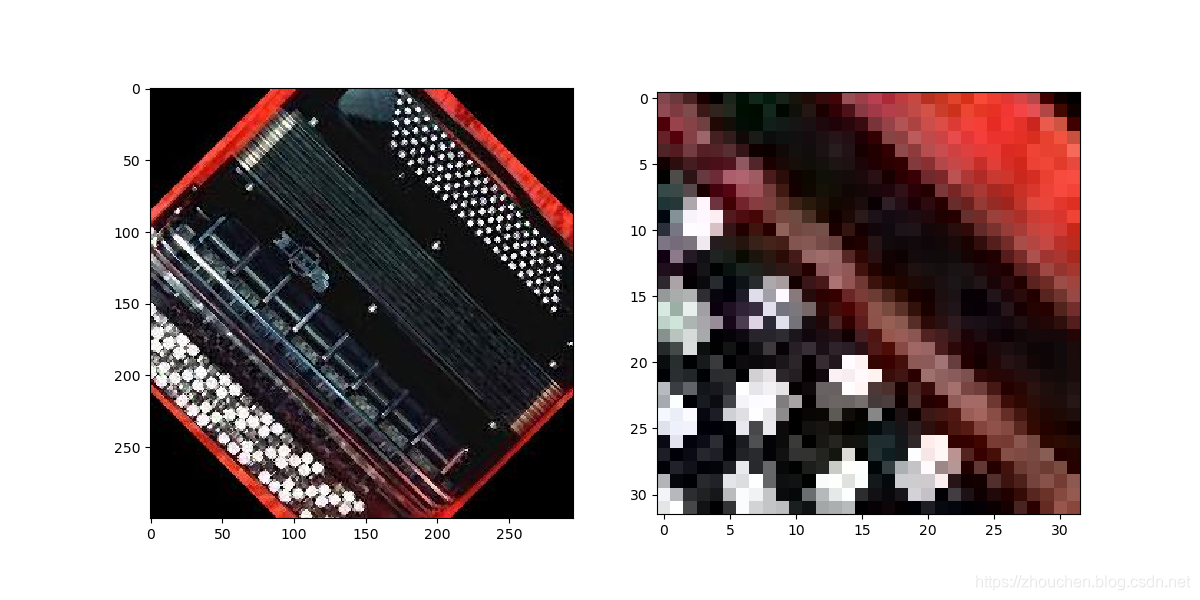
constant表示常量填充,edge表示按照图片边缘像素值填充,reflect根据反射进行填充,symmetric同前一个的效果但会重复边上的值。 - 下图左侧为原图,右侧为随机裁减的结果。
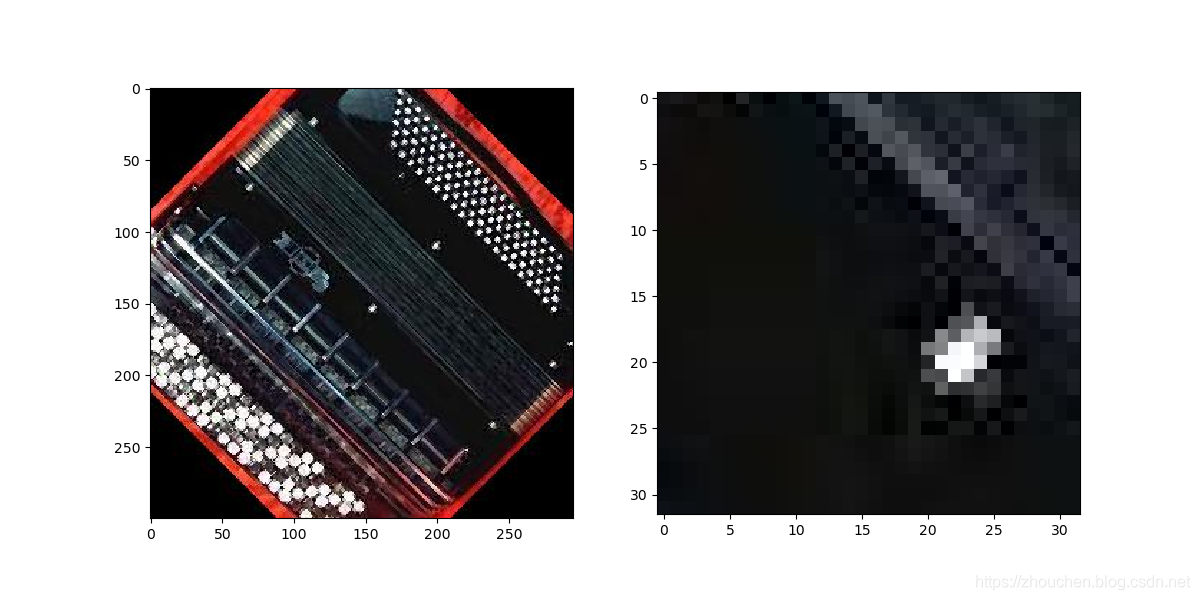
- 中心裁减
transforms.CenterCrop(size)- 根据给定的size从中心进行裁减。
- size参数设置裁减后的图片大小,为整型或者元组,若为元组要符合
(height, width)格式,若int型数则自动按照(size, size)进行长宽设定。 - 下图左侧为原图,右侧为随机裁减的结果。
- 随机长宽比裁减
transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.333), interpolation=2)- 随机大小且随机长宽比裁减图片,最后resize到指定的大小。
- size设置输出图片的大小,为整型或者元组,可以是
(h, w)或者(size, size)格式。 - scale设置随机裁减的大小区间,为浮点型,
(a, b)表示裁减后会在a倍到b倍大小之间。 - ratio设置随机长宽比,浮点型。
- interpolation设置插值方法,默认为双线性插值。
- 上下左右中心裁减
transforms.FiveCrop(size)- 对图片进行上下左右中心进行裁减,得到5个结果图片,返回一个4D的Tensor。
- size参数同上。
- 上下左右中心裁减并翻转
ransforms.TenCrop(size, vertical_flip=False)- 对图片进行上下左右中心裁减后并翻转,共得到10张图片,返回一个4D的Tensor。
- size参数同上。
- vertical_flip设置是否进行垂直翻转,布尔型,默认水平翻转。
转动(Flip and Rotation)
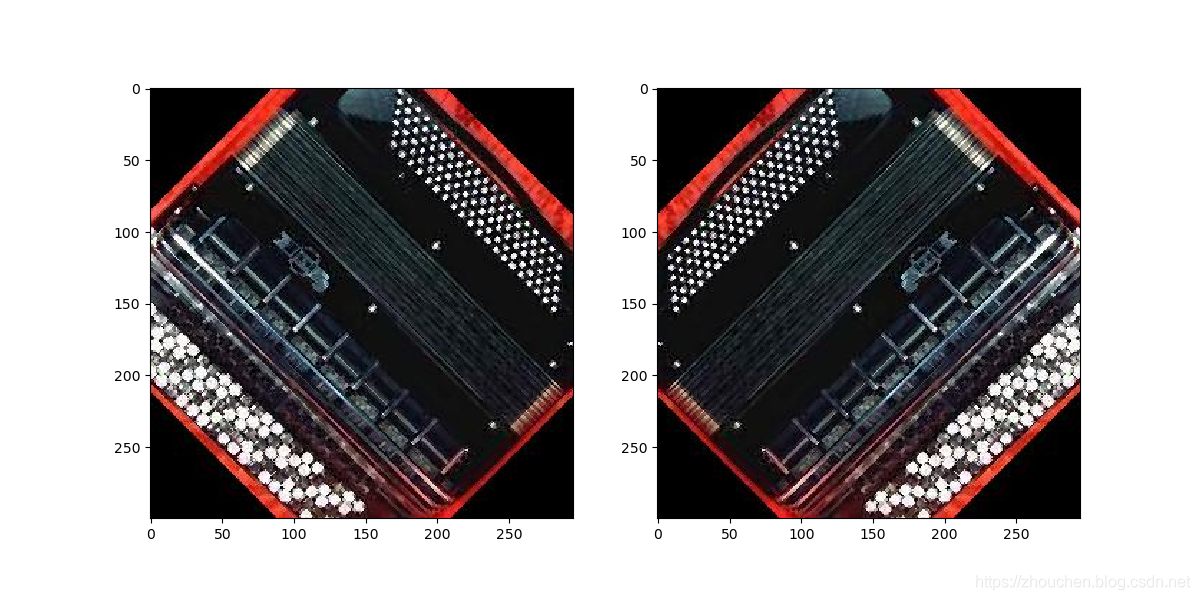
- 概率水平翻转
transforms.RandomHorizontalFlip(p)- 以概率p对图片进行水平翻转。
- p设置进行翻转的概率,浮点型,默认0.5。
- 下图左侧为原图,右侧为随机裁减的结果。
- 概率垂直翻转
transforms.RandomVerticalFlip(size)- 以概率p对图片进行垂直翻转。
- 参数同上。
- 随机旋转
transforms.RandomRotation(degrees, resample=None, expand=False, center=None, fill=None)- 按照degree度数进行随机旋转。
- degrees设置旋转最大角度,数值型或者元组,若单数值则默认
(-degrees, degree)之间随机旋转,若两个数字的元组则表示(a, b)区间进行随机旋转。 - resample设置重采样方法,有下面三个选项
PIL.Image.NEAREST, PIL.Image.BILINEAR, PIL.Image.BICUBIC。 - expand设置是否扩展图片以容纳旋转结果,布尔型,默认False。
- center设置是否中心旋转,默认左上角旋转。
- fill设置填充方法,同裁减部分的参数。
- 下图右侧为随机旋转的结果图。

图像变换
- 图片大小调整
transforms.Resize(size, interpolation=2)- 按照指定size调整图片大小。
- size设置图片大小,
(h, w)格式,若为int数,则按照size*height/width, size进行调整。 - interpolation设置插值方法,默认
PIL.Image.BILINEAR。
- 图像标准化
transforms.Normalize(mean, std)- 对图像按通道进行标准化,即减均值后除以标准差,输入图片
(h, w, c)格式。
- 转为Tensor
transforms.ToTensor()- 将PIL Image或者Numpy.ndarray转为PyTorch的Tensor类型,并归一化至
[0-1],注意是直接除以255。
- 填充
transforms.Pad(padding, fill=0, padding_mode='constant')- 对图像进行填充。
- 参数同上面的
RandomCrop。
- 亮度、对比度和饱和度
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)- 修改亮度、对比度和饱和度。
- 灰度化
transforms.Grayscale(num_output_channels=1)- 图片转为灰度图。
- num_output_channels,输出的灰度图通道数,默认为1,为3时RGB三通道值相同。
- 线性变换
transforms.LinearTransformation(transformation_matrix)- 对矩阵做线性变换,可用于白化处理。
- 仿射变换
transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0)
- 概率灰度化
transforms.RandomGrayscale(p)- 以概率p进行灰度化。
- 转换为PIL Image
transforms.ToPILImage(mode)- 将PyTorch的Tensor或者Numpy的ndarray转为PIL的Image。
- mode参数设置准换后的图片格式,mode为None时单通道,mode为3时转为RGB,为4时转为RGBA。
- Lambda
transforms.Lambda(func)- 将自定义的图像变换函数应用到其中。
- func是一个lambda函数。
transform操作
PyTorch不只是能对图像进行变换,还能对这些变换进行随机选择和组合。
transforms.RandomChoice(transforms)- 随机选择某一个变换进行作用。
transforms.RandomApply(transforms, p=0.5)- 以概率p进行变幻的选择。
transforms.RandomOrder(transforms)- 随机打乱变换的顺序。
补充说明
这个系列的PyTorch教程我没有按照之前TensorFlow2系列教程那样进行由浅入深的展开,即从基础张量运算API到模型训练以及主流的深度模型构建这样的思路,而是按照深度方法端到端的思路展开的,即数据准备、模型构建。损失及优化、训练可视化这样的思路。这是因为PyTorch的基础运算操作类似于Numpy和TensorFlow,我在之前的TensorFlow教程中以及介绍过了。
本文涉及的项目代码均可以在我的Github找到,欢迎star或者fork。因为篇幅限制,较为简略,如有疏漏,欢迎指出。
