声明:本文引用吴恩达教授的DeepLearning课程内容。
1.目标检测基本概念
对于之前的图像问题多数是图像分类,首先将一个图片输入到神经网络中,然后通过多层卷积运算,最后经过几个全连接层,交给Softmax得到分类预测概率向量。
对于目标检测算法,输出标签需要增加边界框四个参数(有一些不同的表示方法:1.中心点、长、宽;2.左下角坐标、右上角坐标;3.左下角坐标,长,宽;但是原理都是一样的)。
2.基于滑动窗口的目标检测算法
首先固定一个卷积区域,然后将卷积核在图像上按照指定步长进行滑动,对于每一次的滑动得到区域进行预测,判断该区域中存在目标的概率。

滑动窗口目标检测算法也有很明显的缺点,就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
3.卷积的滑动窗口实现
Andrew Ng在视频中使用的网络结构如图:
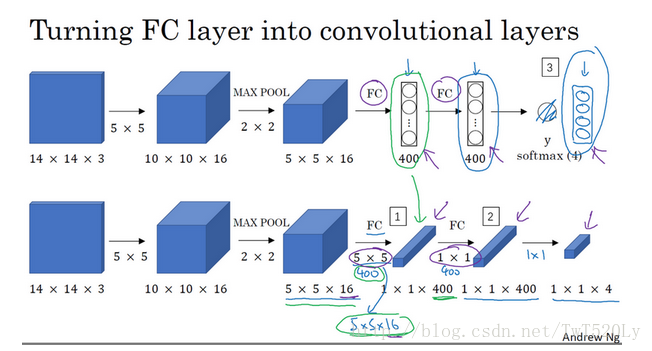
假设对象检测算法输入一个14×14×3的图像,假设对象检测算法输入一个14×14×3的图像。假设对象检测算法输入一个14×14×3的图像y。
我们使用卷积层对全连接层进行替换。至于为什么需要使用卷积层对全连接层进行替换?因为本身在窗口滑动以及多尺度检测的时候运算量会大幅度上升,本身全连接层的运算量非常大,所以使用卷积操作进行替换,提升速度。
对于全连接层,我们可以用5×5的过滤器来实现,数量是400个(编号1所示),输入图像大小为5×5×16,用5×5的过滤器对它进行卷积操作,过滤器实际上是5×5×16,因为在卷积过程中,过滤器会遍历这16个通道,所以这两处的通道数量必须保持一致,输出结果为1×1。假设应用400个这样的5×5×16过滤器,输出维度就是1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层。从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16维度的过滤器,所以每个值都是上一层这些5×5×16激活值经过某个任意线性函数的输出结果。我们再添加另外一个卷积层(编号2所示),这里用的是1×1卷积,假设有400个1×1的过滤器,在这400个过滤器的作用下,下一层的维度是1×1×400,它其实就是上个网络中的这一全连接层。最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,我们最终得到这个1×1×4的输出层,而不是这4个数字(编号3所示)。
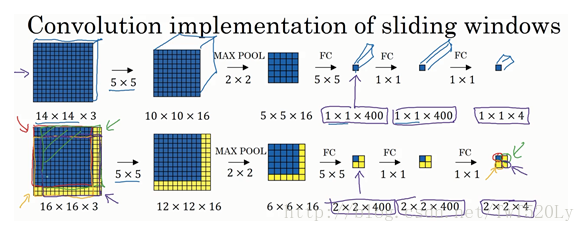
在训练阶段的输入是14×14×3的输入图像,然后经过一系列的卷积运算,得到1×1×4的输出。对于检测阶段,在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。