Python相关实用技巧04:网络爬虫——Scrapy框架
1 Scrapy爬虫框架介绍
1.1 Scrapy简介与安装
Scrapy是一个快速且功能强大的的网络爬虫框架。
-
Python中实用的第三方库
-
重要的爬虫技术方法
-
Scrapy安装执行:pip install scrapy
-
安装后小测:执行scrapy -h
1.2 scrapy爬虫框架结构
-
爬虫框架:
- 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
- 爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
-
“5+2”结构(分布式、数据流):Spiders、Item Pipelines、Engine、Scheduler、Downloader。

1.3 爬虫框架解析
-
Engine:
- 控制所有模块之间的数据流
- 根据条件触发事件
- 不需要用户修改
-
Downloader:
- 根据请求下载网页
- 不需要用户修改
-
Scheduler:
- 对所有爬虫请求进行调度管理
- 不需要用户修改
-
Downloader Middleware:
- 目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应
- 用户可以编写配置代码
-
Spider(框架入口):
- 解析Downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的爬取请求(Request)
- 需要用户编写配置代码
-
Item Pipeline(框架出口):
- 以流水线方式处理Spider产生的爬取项
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
- 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
- 需要用户编写配置代码
-
Spider Middleware
- 目的:对请求和爬取项的再处理
- 功能:修改、丢弃、新增请求或爬取项
- 用户可以编写配置代码
2 requests库 和 Scrapy框架爬虫比较
-
相同点:
(1)两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
(2)两者可用性都好,文档丰富,入门简单
(3)两者都没有处理js、提交表单、应对验证码等功能(可扩展) -
不同点:

-
选用谁?
- 非常小的需求,requests库
- 不太小的需求,Scrapy框架
- 定制程度很高的需求(不考虑规模),自搭框架,requests > Scrap
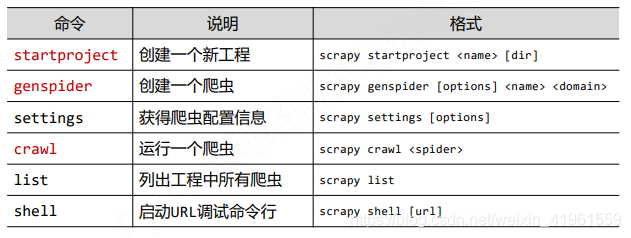
3 Scrapy爬虫的常用命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行
- 命令行(不是图形界面)更容易自动化,适合脚本控制。本质上,Scrapy是给程序员用的,功能(而不是界面)更重要
- Win下,启动cmd控制台
- Scrapy命令行格式:

- Scrapy常用命令:
4 Scrapy爬虫基本操作流程(举例阐述)
应用Scrapy爬虫框架主要是编写配置型代码:
4.1 建立一个Scrapy爬虫工程
- 选取一个目录:如,D盘下的pycodes文件夹,输入“D:”,再输入“cd pycodes”
- 然后执行如下命令:scrapy startproject python123demo

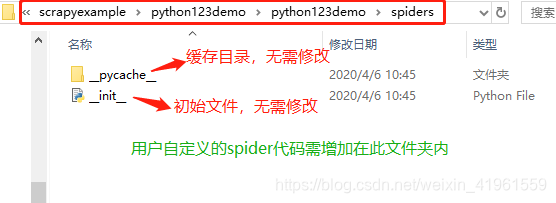
- 自动生成的爬虫工程目录:

打开python123demo文件夹,如下:

打开spiders文件夹,如下:
4.2 在工程中产生一个Scrapy爬虫
进入工程目录(D:\scrapyexample\python123demo),然后执行如下命令:scrapy genspider demo pythondemo123.io
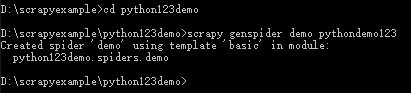
该命令作用:
(1)生成一个名称为demo的spider
(2)在spider目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
demo.py文件内容如下:

4.3 配置产生的spider爬虫
(1)初始化URL地址
(2)获取页面后的解析方式

4.4 运行爬虫,获取网页
在命令行下,执行如下命令:scrapy crawl demo

demo爬虫被执行,捕获页面存储在demo.html
5 Scrapy爬虫的使用
5.1 Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
5.2 Scrapy爬虫的数据类型
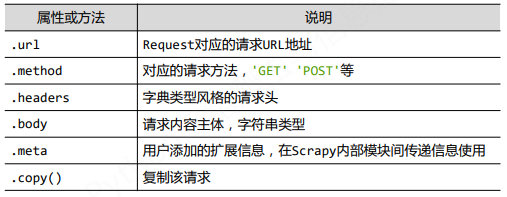
(1)Request类
class scrapy.http.Request()
- Request对象表示一个HTTP请求
- 由Spider生成,由Downloader执行
(2)Response类
class scrapy.http.Response()
- Response对象表示一个HTTP响应
- 由Downloader生成,由Spider处理

(3)Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline处理
- Item类似字典类型,可以按照字典类型操作
5.3 Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法:
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector

6 实例:股票数据Scrapy爬虫
6.1 功能描述
- 目标:获取上交所和深交所所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:scrapy
6.2 数据网站的确定
(1)获取股票列表:
- 东方财富网:http://quote.eastmoney.com/stocklist.html
(2)获取个股信息:
- 百度股票:https://gupiao.baidu.com/stock/
- 单个股票:https://gupiao.baidu.com/stock/sz002439.html
6.3 爬虫操作步骤
步骤1:建立工程和Spider模板
(1)>scrapy startproject BaiduStocks
(2)>cd BaiduStocks
(3)>scrapy genspider stocks baidu.com
(4)进一步修改spiders/stocks.py文件
步骤2:编写Spider(处理链接爬取和页面解析)
(1)配置stocks.py文件
(2)修改对返回页面的处理
(3)修改对新增URL爬取请求的处理


步骤3:编写ITEM Pipelines(处理信息存储)
(1)配置pipelines.py文件
(2)定义对爬取项(Scraped Item)的处理类
(3)配置ITEM_PIPELINES选项


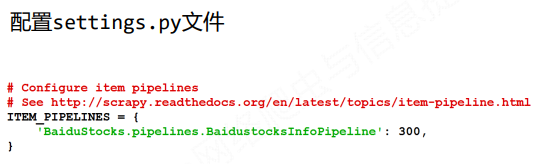
步骤4:执行爬虫
scrapy crawl stocks
6.4 爬虫实例优化
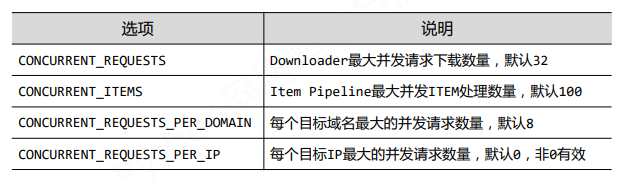
如何进一步提高scrapy爬虫爬取速度?
配置并连接选项
- settings.py文件
相关笔记:
- Python相关实用技巧01:安装Python库超实用方法,轻松告别失败!
- Python相关实用技巧02:Python2和Python3的区别
- Python相关实用技巧03:14个对数据科学最有用的Python库
- Python相关实用技巧04:网络爬虫之Scrapy框架及案例分析
- Python相关实用技巧05:yield关键字的使用
- Scrapy爬虫小技巧01:轻松获取cookies
- Scrapy爬虫小技巧02:HTTP status code is not handled or not allowed的解决方法
- 数据分析学习总结笔记01:情感分析
- 数据分析学习总结笔记02:聚类分析及其R语言实现
- 数据分析学习总结笔记03:数据降维经典方法
- 数据分析学习总结笔记04:异常值处理
- 数据分析学习总结笔记05:缺失值分析及处理
- 数据分析学习总结笔记06:T检验的原理和步骤
- 数据分析学习总结笔记07:方差分析
- 数据分析学习总结笔记07:回归分析概述
- 数据分析学习总结笔记08:数据分类典型方法及其R语言实现
- 数据分析学习总结笔记09:文本分析
- 数据分析学习总结笔记10:网络分析
本文主要根据个人学习(Python网络爬虫与信息提取MOOC),并搜集部分网络上的优质资源总结而成,如有不足之处敬请谅解,欢迎批评指正、交流学习!
