码距
任何一种编码都由许多码字构成,任意两个码字之间最少变化的二进制位数,被称为数据校验码的码距。例如,用四位二进制表示16种状态,则有16个不同的码字,此时码距为1,即两个码字之间最少仅有一个二进制位不同(如0000与0001之间)。这种编码没有检错能力,因为当某一个合法码字中有一位或几位出错,就变成为另一个合法码字了。
具有检、纠错能力的数据校验码的实现原理是:在编码中,除去合法的码字外,再加进一些非法的码字,当某个合法码字出现错误时,就变成为非法码字。合理地安排非法码字的数量和编码规则,就能达到纠错的目的。例如,若用四位二进制表示八个状态,其中只有八个码字是合法码字,而另八个码字为非法码字,此时码距为2。对于码距≥2的数据校验码,开始具有检错的能力。码距越大,检、纠错能力就越强,而且检错能力总是大于或等于纠错能力。
奇偶校验码
码距为2
奇偶校验码由一位校验位和若干位信息位构成。
原理:校验位的取值将决定整个校验码的1的个数是偶数或者奇数。信息位有1位或奇数位发生变化时,1的个数就不是偶数或奇数,以此来检错。
根据1的个数是奇数还是偶数将检验规律分两种。
- 奇校验(1的个数是奇数)
- 偶校验(1的个数是偶数)
如果信息位是0000 0001,则奇校验码是0 0000 0001,偶校验码是1 0000 0001。
以下是电路图,假设有效信息位有8位。

- 对于0000 0001,D7至D1是0,D0是1。
- D7与D6,D5与D4等两两异或。异或的结果再异或,最终得到一个值1,1就是偶形成,1取反就是奇形成。
- 奇偶形成就是对应的奇偶校验位
- D校如果是偶校验位,和偶形成异或,得到的值是1说明偶校验出错。
- D校如果是奇校验位,和偶形成异或,得到的值取反,是1说明奇校验出错。
通过奇偶校验只能确定奇偶校验码是否出现1位或奇数位发生的错误,无法确定出错位置。
交叉奇偶检验
计算机在进行大量字节(数据块)传送时,不仅每一个字节有一个奇偶校验位做横向校验,而且全部字节的同一位也设置一个奇偶校验位做纵向校验,这种横向、纵向同时校验的方法称为交叉校验。
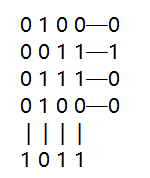
假如第一行的四个数全出错了,变成1011,它横向任然是奇数个1。无法查出错误。但纵向全变成了偶数个1,这样就知道错了。
交叉校验可以发现多位同时出错的情况
海明校验码
实质上是多组奇偶校验
处理过程:
最终比较时按位异或,以确定是否有错。这种异或操作所得到的结果称为故障字。
单纠错码
码距为3
每组一个校验位,校验码的位数等于组数。每一组内采用一位奇偶校验位。
假定数据位是n位,校验码是k位,故障字也是k位。
k位故障字能表示2K个状态,每种状态可以来说明一种情况。
若只有一位发生变化,则结果可能是:
- 数据位出错一位(n种情况)
- 检验码出错一位(k种情况)
当然还有一种不出错的情况。
综上所述,k位故障字所表示的状态可以反映一位出错的状态和不出错的状态。所以需要大于等于n+k+1。
基本思想:n位数据位和k位校验位按某种方式排列为一个n+k位的码字,将该字中每个出错位的位置与故障字的数值建立关系,通过故障字的值确定该码字中的哪一位发生错误,并将其取反来纠正
有如下规则:
- 故障字全0,表示无错。
- 故障字有1位1,表示校验码中出错一位。
- 故障字有多位1,表示数据位中出错一位,故障字的值来确定出错位置,纠正时将出错位取反。
以8位数据位,4位校验位,组成12位码字为例:
- 根据上面规则1,故障字是0000时,表示无错。
- 根据上面规则2,故障字是0001,0010,0100,1000分别表示校验位的第1,2,3,4位出错。为了统一故障字的值表示出错位置,0001,0010,0100,1000对应10进制的1,2,4,8,将校验位的第1,2,3,4位分别置于码字的第1,2,4,8位。
- 根据上面规则3,将1的个数1位以上的故障字依次表示数据位发生错误的情况。所以0011,0101,0110,0111,1001,1010,1011,1100分别表示数据位的1至8位出错。0011,0101,0110,0111,1001,1010,1011,1100对应10进制的3,5,6,7,9,10,11,12,将数据位的第1至8位置于码字的第3,5,6,7,9,10,11,12位。
注意:上面所说的位置是逻辑上的位置·,物理上检验位和数据位是分开的。
分组
设校验位从低位至高位用P1至P4表示。数据位从低位至高位用M1至M8表示。
所以构成的码字是M8M7M6M5P4M4M3M2P3M1P2P1
引用上面:故障字是0001,0010,0100,1000分别表示校验位的第1,2,3,4位出错。
故障字是0011,0101,0110,0111,1001,1010,1011,1100分别表示数据位的1至8位出错
因为故障字0000时表示无错,所以列一个表,这个表反应码字每一位出错对应的故障字
| 组数 | M8 | M7 | M6 | M5 | P4 | M4 | M3 | M2 | P3 | M1 | P2 | P1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| 4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
将故障字按位分组。影响相同位的码字位是一组,1代表影响,0代表不影响。
每组中都有一位校验位和多位数据位。
每组处理时和奇偶校验就一样。
所以,按偶校验看的话,校验位就是数据位两两异或。(奇校验是两两异或的最终结果取反)
得到:
P1=M1⊕M2⊕M4⊕M5⊕M7
P2=M1⊕M3⊕M4⊕M6⊕M7
P3=M2⊕M3⊕M4⊕M8
P4=M5⊕M6⊕M7⊕M8
将生成的P1P2P3P4和校验位进行异或,即可得到故障字。
例如:
有一个二进制数是1001 1100,经过传输以后变成了1001 1101(M1出错)。正确的数1001 1100生成的校验码(偶校验)是0100,错误的数1001 1101生成的校验码是0111,将两个校验码异或生成故障字0011,所以M1出错(M1位于M8M7M6M5P4M4M3M2P3M1P2P1第三位)。
单纠错双检测码
码距为4
增加一位校验位P5,将P5排在码字最前面,即P5M8M7M6M5P4M4M3M2P3M1P2P1,并使数据的每一位都参加3个校验位的生成,从上面的表可以看出,M4和M7生成3个校验位,其他的生成2个校验位,将生成2个校验位的数据位生成P5,这样每个数据位都生成3个校验位,即P5=M1⊕M2⊕M3⊕M5⊕M6⊕M8。
这样当任一一位数据位发生错误时,会有相应的3个校验位变化,这样码距就是4。
有如下规则:
- 故障字全0,表示无错。
- 故障字有1位1,表示校验码中出错一位或者是数据位出错1位和检验码出错2位(共3位)。
- 故障字有2位1,表示校验码和检验码各出错1位(共2位)或者检验码出错2位。
- 故障字有3位1,表示数据位中出错一位或者3位检验位出错,故障字的值来确出错位置,纠正时将出错位取反。
- 故障字有4、5位1,表示系统工作故障或硬件出问题。
循环冗余码(CRC码)
- 循环冗余校验码是通过除法运算来建立有效信息位和校验位之间的约定关系的。
- 一个CRC码一定能被生成多项式整除。
- 假设,待编码的有效信息以多项式M(X)表示,用另一个约定的多项式G(X)去除,所产生的余数R(X)就是检验位。有效信息和检验位相拼接就构成了CRC码。
- 当整个CRC码被接收后,仍用约定的多项式G(X)去除,若余数为0表明该代码是正确的;若余数不为0表明某一位出错,再进一步由余数值确定出错的位置,以便进行纠正。
例如:
- 一个二进制数是101101,对应的报文多项式是
- 若约定的生成多项式是 ,生成多项式是4位,校验位是4-1=3位,除数是1001。
- 生成校验码时,用x3 · M(x)除以G(x),即
- 相除时,采用“模2运算”的多项式除法
模二运算不考虑加法减法借位,上商的原则是当部分余数首位是1时商取1,反之商取0

最终得到的余数加上数据位就得到CRC码,即101101+000=101101000(余数刚好为000)
