Spark开发性能调优
标签(空格分隔): Spark
–Write By Vin
1. 分配资源调优
Spark性能调优的王道就是分配资源,即增加和分配更多的资源对性能速度的提升是显而易见的,基本上,在一定范围之内,增加资源与性能的提升是成正比的,当公司资源有限,能分配的资源达到顶峰之后,那么才去考虑做其他的调优
如何分配及分配哪些资源
在生产环境中,提交spark作业时,使用spark-submit shell脚本,里面调整对应的参数
常用参数
/opt/modules/spark-1.6.1-bin-2.5.0-cdh5.3.6/bin/spark-submit \
--class com.hypers.sparkproject.spark.session.UserVisitSessionAnalyzeSpark \
--num-executors 3 \ --配置executor的数量
--driver-memory 1024M \ --配置driver的内存,影响不大
--executor-memory 2G \ --配置每个executor的内存大小
--executor-cores 3 \ --Spark standalone and YARN only --配置每个executor的cpu核数
/usr/loacl/recommend-1.0-SNAPSHOT.jar \- 1
- 2
- 3
- 4
- 5
- 6
- 7
分配多少
- 第一种:Spark Standalone即Spark运行在自己的分布式框架时,需要知道每台机器能够使用的内存,CPU核数,假如每台机器能够使用4G内存和2个CPU核数,一共20台机器,那么就可以executor数量设置20,每个executor内存设置4G,每个executor设置2 CPU core
- 第二种: Yarn 当Spark运行在yarn上时,需要查看资源队列有多少资源,假如资源队列有500G内存,100个CPU core可用,那么就可以设置50个executor,每个executor内存设置10G,每个executor设置2个CPU core
总之,就是尽量的去调节到最大的大小(executor的数量和executor的内存)
资源分配是如何影响性能的
当我们从客户端提交一个Spark应用程序时,SparkContext,DAGScheduler,TaskScheduler会将程序中的算子,切分成大量的task,提交到executor上面运行
- 增加executor数量和executor的CPU核数 : 增加了并行执行能力,加入原来20个executor,每个executor的CPU核数为2个,那么能够并行执行的task数量就是40个task,当在资源允许的情况下增加这两个指标,执行速度将会成倍增加
- 增加executor的内存 : 增加内存后,对性能的提升主要有三点:
- 如果要对RDD进行cache,那么更多的内存就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘,减少了磁盘IO
- 对于shuffle操作,在reduce端,会需要内存来存放拉取的数据并进行聚合,如果内存不足,也会写入磁盘,如果给executor分配更多的内存,同样减少磁盘IO
- 对于task的执行,可能会创建很多对象,如果内存较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收,minor GC和full GC,速度很慢
2. 并行度调优
何为并行度
并行度指Spark作业中,各个stage的task数量
为什么要设置并行度 ?
假设,现在已经在spark-submit脚本里面,给spark作业分配了足够多的资源,比如50个executor,每个executor有10G内存,每个executor有3个CPU核。基本已经达到了集群或者yarn队列的资源上限。但是task没有设置,或者设置的很少,比如就设置了,100个task。50个executor,每个executor有3个cpu核,也就是说,你的Application任何一个stage运行的时候,都有总数在150个cpu核,可以并行运行。但是你现在,只有100个task,平均分配一下,每个executor分配到2个task,那么同时在运行的task,只有100个,每个executor只会并行运行2个task。每个executor剩下的一个cpu核,就浪费掉了。所以你的资源虽然分配足够了,但是问题是,并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。
合理的设置并行度
理想情况下,task数量设置成Spark Application 的总CPU核数,但是现实中总有一些task运行慢一些task快,导致快的先执行完,空余的cpu 核就浪费掉了,所以官方推荐task数量要设置成Spark Application的总cpu核数的2~3 倍
如何设置并行度
SparkConf conf = new SparkConf()
.set("spark.default.parallelism", "500")- 1
- 2
3. 重构RDD架构及RDD持久化 序列化
- RDD架构重构与优化
默认情况下,多次对一个RDD执行算子,去获取不同的RDD,都会对这个RDD以及之前的父RDD全部重新计算一次,在实际项目中,一定要避免出现一个RDD重复计算的情况, 所以,要尽量去复用RDD,差不多的RDD可以抽取为一个共同的RDD,供后面的RDD计算时反复使用 - 公共RDD实现持久化
对于要多次计算和使用的公共RDD,一定要进行持久化
持久化:也就是说,将RDD的数据缓存在内存中/磁盘中,(BlockManager),之后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据 - 持久化数据序列化
如果正常将数据持久化在内存中,那么可能会导致内存的占用过大,会导致OOM,当纯内存无法支撑公共RDD数据完全存放的时候,就需要优先考虑使用序列化的方式在纯内存中存储,将RDD的每个partition的数据,序列化成一个大的字节数组,就一个对象,序列化后,大大减少内存的空间占用
序列化的唯一缺点就是在获取数据的时候需要反序列化, 如果序列化后纯内存的方式还导致OOM,就只能考虑内存+无序列化的普通方式 - 持久化+双副本机制
为了数据的高可靠性,而且内存充足,可以使用双副本机制进行持久化
持久化的双副本机制,持久化后的一个副本,因为机器宕机了,副本丢了,就还是得重新计算一次;持久化的每个数据单元,存储一份副本,放在其他节点上面;从而进行容错;一个副本丢了,不用重新计算,还可以使用另外一份副本。
4. 广播变量
广播变量:Broadcast,将大变量广播出去,而不是直接使用
- 为什么要用Broadcast
当进行随机抽取一些操作,或者从某个表里读取一些维度的数据,比如所有商品品类的信息,在某个算子函数中要使用到,加入该数据大小为100M,那么1000个task将会消耗100G的内存, 集群损失不可估量 - Broadcast的原理
默认的情况下,每个task执行的算子中,使用到了外部的变量,每个task都会获取一份变量的副本,所以会消耗很多的内存,进而导致RDD持久化内存不够等情况,大大影响执行速度
广播变量,在driver上会有一份初始的副本,task在运行的时候,如果要使用广播变量中的数据,首先会在自己本地的Executor对应的BlockManager中尝试获取变量副本,并保存在本地的BlockManager中,此后这个Executor上的所有task,都会直接使用本地的BlockManager中的副本,Executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本,距离越近越好.
总而言之: 广播变量的好处不是每一个task一份变量副本,而是变成每个节点的executor才一份副本,这样的话就可以变量产生的副本大大减少
5. Kryo序列化的使用
什么是序列化
默认情况下,Spark内部是使用java的序列化机制ObjectInputStream/ObjectOutputStream,即对象输入输出流机制来进行序列化, 这种序列化机制的好处在于,处理起来比较方便,只需在在算子里面使用的变量,必须是实现Serializable接口的,可序列化即可,但是这种默认的序列化机制的效率不高,序列化速度慢,序列化以后的数据占用的内存空间相对很大
Spark支持使用Kryo序列化机制,比默认的java序列化机制速度要快很多,而且序列化后的数据大小大概是java序列化机制的1/10
Kryo序列化机制,一旦启用,会生效的几个地方
算子函数中使用的外部变量
算子函数中使用的外部变量,在经过kryo序列化之后,会优化网络传输的性能,优化集群中内存的占用和消耗扫描二维码关注公众号,回复: 1082409 查看本文章
持久化RDD时进行序列化,StorageLevel.MEMORY_ONLY_SER
持久化RDD的时候,优化内存的占用和消耗shuffle
优化网络传输的性能
在Spark程序中如何使用序列化
- 第一步: 在SparkConf中设置一个属性
SparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")- 1
- 第二步: 注册需要使用Kryo序列化的自定义的类
如果要达到Kryo的最佳性能的话,那么就一定要注册自定义的类
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{CategorySortKey.class})- 1
- 2
6.fastutil
fastutil 是扩展了java标准集合框架(Map,List,Set,HashMap,ArrayList,HashSet)的类库,提供了特殊类型的Map,Set,List和queue,fastutil能够提供更小的内存占用,更快的存取速度,fastutil也提供了64位的array、set和list,以及高性能快速的,以及实用的IO类,来处理二进制和文本类型的文件;
fastutil最新版本要求Java 7以及以上版本
Spark中fastutil应用场景:
- 1.如果算子函数使用了外部变量,那么可以用三步来优化: a.使用Broadcast广播变量优化, b. 使用Kryo序列化类库优化,提升性能和效率,c.如果外部变量是某种比较大的集合,可以使用fastutil改写外部变量
- 2.在算子函数中,如果要创建比较大的Map.List等集合,可以考虑将这些集合类型使用fastutil类库重写
fastutil的使用:
<dependency>
<groupId>fastutil</groupId>
<artifactId>fastutil</artifactId>
<version>5.0.9</version>
</dependency>- 1
- 2
- 3
- 4
- 5
7.数据本地化等待时长
什么是本地化等待时长
Spark在Driver上,对Application的每一个stage的task,在进行分配之前,都会计算出每个task要计算的是哪个分片的数据也即是RDD的某个partition.Spark的task分配算法优先会希望每个task正好分配到它要计算的数据所在的节点,这样就避免了网络间传输数据
但是,task可能没有机会分配到它的数据所在的节点,因为可能计算资源和计算能力都满了,这种情况下,Spark会等待一段时间,过了这个时间,才会选择一个比较差的本地化级别,比如将这个task分配到相邻的一个节点上,这个时候肯定发生网络传输,会通过一个getRemote()方法,通过TransferService(网络数据传输组件)从数据所在节点的BlockManager中获取数据,上述中的一段时间即为本地化等待时长
如何调节本地化等待时长
PROCESS_LOCAL:进程本地化,代码和数据在同一个进程中,也就是在同一个executor中;计算数据的task由executor执行,数据在executor的BlockManager中;性能最好
NODE_LOCAL:节点本地化,代码和数据在同一个节点中;比如说,数据作为一个HDFSblock块,就在节点上,而task在节点上某个executor中运行;或者是,数据和task在一个节点上的不同executor中;数据需要在进程间进行传输
NO_PREF:对于task来说,数据从哪里获取都一样,没有好坏之分
RACK_LOCAL:机架本地化,数据和task在一个机架的两个节点上;数据需要通过网络在节点之间进行传输
ANY:数据和task可能在集群中的任何地方,而且不在一个机架中,性能最差
spark.locality.wait,默认是3s- 1
- 2
- 3
- 4
- 5
- 6
- 7
在使用client模式测试时,在本地就可以看到比较全的日志,日志里面会显示: 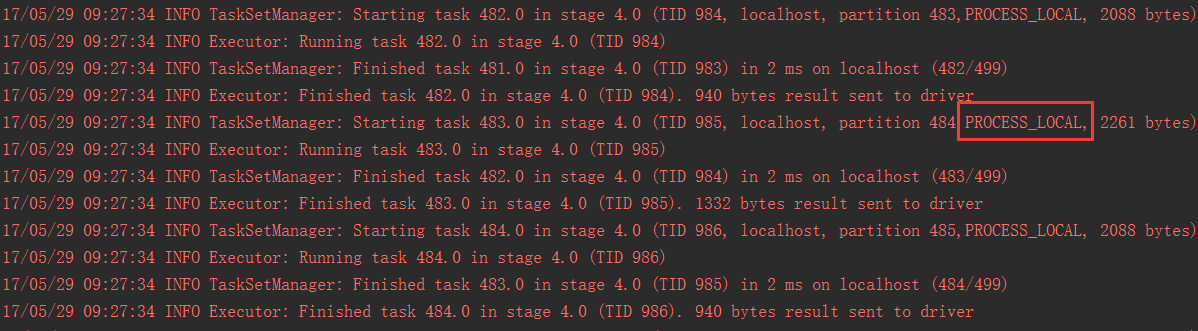
如果大多都是PROCESS_LOCAL,那就不用调节了
如果是发现,好多的级别都是NODE_LOCAL、ANY,那么最好就去调节一下数据本地化的等待时长
调节完,应该是要反复调节,每次调节完以后,再来运行,观察日志
看看大部分的task的本地化级别有没有提升;看看,整个spark作业的运行时间有没有缩短
调节方法:
spark.locality.wait,默认是3s;可以调节为6s,10s
默认情况下,下面3个的等待时长,都是跟上面那个是一样的,都是3s
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
new SparkConf()
.set("spark.locality.wait", "10")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
8.JVM调优
JVM体系结构
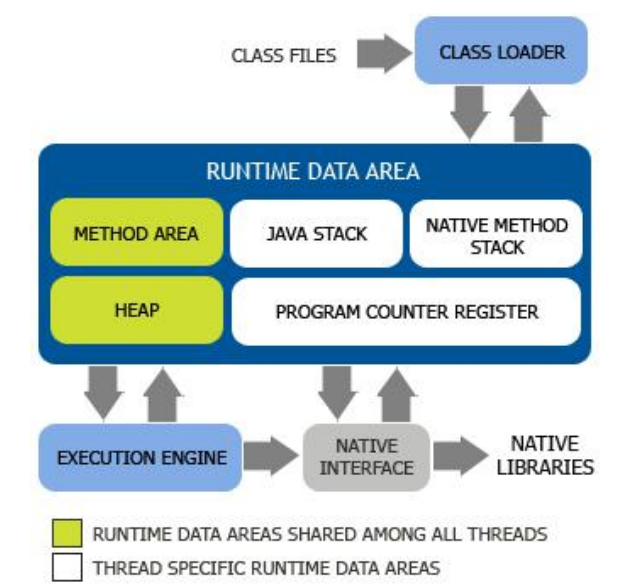
- CLASS FILES : scala或者java类程序
- CLASS LOADER : 类加载子系统
RUNTIME DATA AREA : 运行数据域组件
- Java Stack(栈)
- HEAP (堆)
- Method Area(方法区)
- PC Register(程序计数器)
- Native Method Stack (本地方法栈)
Execution Engine : 执行引擎子系统
- Native Interface : 本地接口组件
Java Stack (栈)
栈也叫栈内存,是Java程序的运行区,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束,栈也随之释放
栈中的数据是以栈帧(Stack Frame)的格式存在,栈帧是一个内存区块,是一个数据集,是一个有关方法(Method)和运行期数据的数据集,当一个方法A被调用时就产生了一个栈帧F1,并被压入到栈中,A方法又调用B方法,于是产生栈帧F2也被压入栈中,执行完毕后,先弹出F2,后弹出F1,即”先进后出”原则
Java Heap(堆)
一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的,堆内存也是JVM中用于存放对象与数组实例的地方,垃圾回收的主要区域就是这里(还有可能是方法区Method Area),类加载器读取了类文件之后,需要把类,方法,常变量放到堆内存中,以方便执行器执行,堆内存分为三个部分:
- Permanent Space : 永久存储区
- Young Generation Space 新生区 / New Generation
- Tenure Generation Space 养老区 / Old Generation

- New /Young Generation
又称新生代,程序中新建的对象都会分配到新生代中,新生代又由Eden Space 和两块Survivor Space构成,可通过-Xmn参数来指定其大小,Eden 和两块Survivor Space的大小比例默认是8:1:1,这个比例可通过-XX:SurvivorRatio来指定
- Old Generation
又称老年代,用于存放程序中经过几次垃圾回收还存活的对象,例如缓存的对象,老年代所占的内存大小即为-Xmx大小减去-Xmn大小
- Permanent Generation
一个常住内存区域,用于存放JDK自身所携带的Class,Interface的元数据,即存储的是运行环境必须的类信息,被装载到此区域的数据是不会被;垃圾回收掉的,直至关闭JVM才会释放
Young/New Generation
年轻代与Spark调优息息相关,所以这里单独拿出来讲解
所有新生成的对象首先都是放在年轻代中,年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象
大部分对象在Eden区生成,当Eden区满时,还存活的对象将被复制到Survivor区中(两中的一个),当这个Survivor区满的时候,此区存放的对象会被放在另一个Survivor区中,当另一个Survivor也满的时候,从第一个Survivor复制过来的还存活的对象将被复制到老年代中,Survivor的两个区是对称的,没有先后关系,所以同一个Survivor取中可能存在从Eden复制过来的对象和从另一个Survivor复制过来的对象,而且Survivor总有一个是空的,而且可以配置多余两个
Spark的JVM调优
- 降低cache操作的内存占比
Spark task执行算子函数时会生成大量对象,这些对象会被放入年轻代中,当年轻代内存比较小时,会导致年轻代中Eden区和Survivor区频繁内存溢满,导致频繁的minor GC,而频繁的minorGC或导致一些存活的短声明周期(其实就是在后面用不到的对象)对象直接放入老年代中,而当老年代内存溢满是,则会导致Full GC
full gc / minor gc,无论是快,还是慢,都会导致jvm的工作线程停止工作,简而言之,就是说,gc的时候,spark停止工作了。等着垃圾回收结束。
总而言之,上面的情况都是由内存不足引起的即内存不充足的时候,问题:
1、频繁minor gc,也会导致频繁spark停止工作
2、老年代囤积大量活跃对象(短生命周期的对象),导致频繁full gc,full gc时间很长,短则数十秒,长则数分钟,甚至数小时。可能导致spark长时间停止工作。
3、严重影响咱们的spark的性能和运行的速度。
如何增大内存?
Spark中,堆内存又被划分成了两块,一块是专门用来给RDD的cache,persist操作进行RDD缓存用的,另一块就是用来给Spark算子函数用的,存放函数中自己创建的对象
默认情况下,给RDD的cache操作的内存占比是0.6,即百分之六十的内存用来给RDD做缓存用,但其实RDD并不需要这么大的内存,我们可以通过查看每个stage中每个task运行的时间,GC时间等来判断是否发生了频繁的minorGC和fullGC,从而来调低这个比例
调节方法
spark.storage.memoryFraction,0.6 -> 0.5 -> 0.4 -> 0.2- 1
- Ececutor堆外内存
当Spark处理超大数据量时(数十亿,百亿级别),executor的堆外内存可能会不够用,出现shuffle file can’t find, task lost,OOM等情况
默认情况下,这个堆外内存是300M,当运行超大数据量时,通常会出现问题,因此需要调节到1G,2G,4G等大小
调节方法必须在spark-submit提交脚本中设置而不能在程序中设置
--conf spark.yarn.executor.memoryOverhead=2048- 1
- GC引起的连接等待时长
Spark在处理超大数据量时,task可能会创建很大很多的对象,频繁的让JVM内存溢满,导致频繁GC,而前面提到过executor获取数据优先的从本地关联的blockmanager获取,如果没有的话,会通过transferService去远程连接其他executor的blockmanager,如果正好碰到那个executor垃圾回收,那么程序就会卡住,spark默认网络连接时长是60s,当超过60s没有获取到数据,则直接宣告任务失败,也有可能DAGscheduler反复提交几次stage,TaskScheduler反复提交task,则会大大影响spark运行速度,所以可以考虑适当调节等待时长
调节方式同调节堆外内存一样,必须在提交spark程序的脚本中设置
--conf spark.core.connection.ack.wait.timeout=300- 1
9. shuffle 调优
shuffle原理
什么情况下发生shuffle?
在Spark中,主要有以下几个算子
- groupByKey : 把分布在各个节点上的数据中的同一个key对应的value都集中到一块儿,集中到集群中的一个节点中,也即是集中到一个节点的executor的一个task中
- reduceByKey : 算子函数对values集合进行reduce操作,最后生成一个value
- countByKey : 在一个task中获取同一个key对应的所有value,然后计数,统计总共有多少value
- join : 两个RDD,Key相同的两个value都集中到一个executor的task中
shuffle过程: 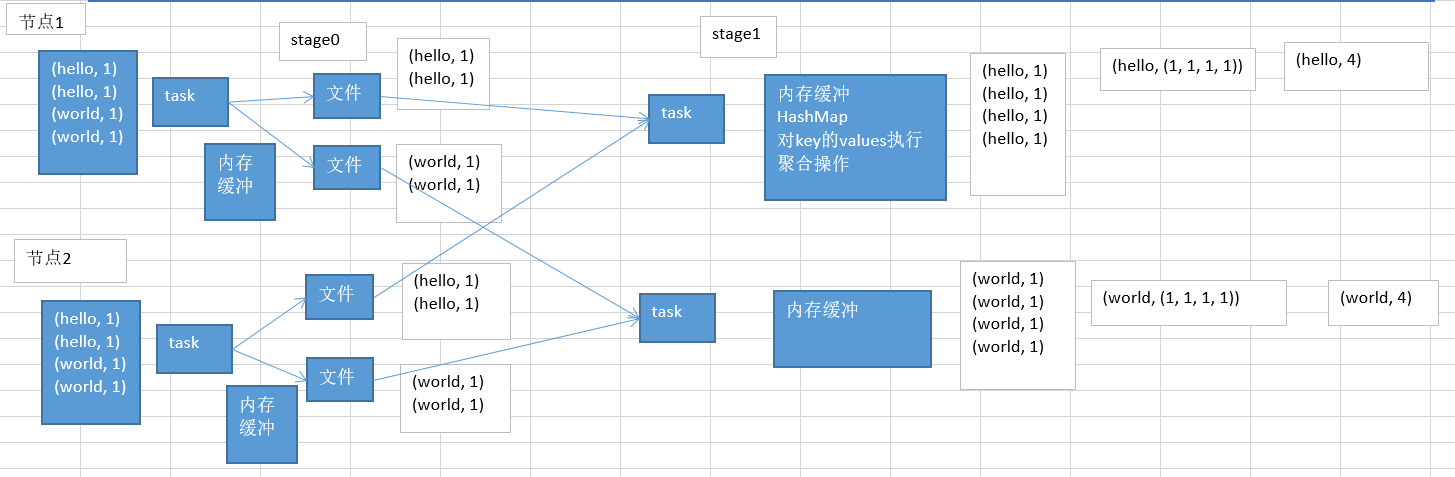
在一个shuffle过程中,前半部分stage中,每个task都会创建后半部分stage中相同task数量的文件,比如stage后半部分有100个task,那么前半部分的每个task都会创建100个文件(先写入到内存缓冲中,后溢满写入到磁盘),会将同一个key对应的values写入同一个文件中,shuffle后半部分的stage中的task,每个task都会从各个节点的task创建其中一份属于自己的那份文件中,拉取属于自己的key-value对,然后task会有一个内存缓冲区,然后调用HashMap进行key-values的聚合,最终调用我们定义的聚合函数来进行相应的操作
shuffle调优之合并map端输出文件
默认情况下,Spark是不开启合并map端输出文件机制的,所以当分批次执行task时,每批的task都会创建新的文件,而不会共用,大大影响了性能,所以当有大量map文件生成时,需要开启该机制
设置方法
new SparkConf().set("spark.shuffle.consolidateFiles", "true")- 1
设置合并机制之后:
第一个stage,并行运行2个task,运行这两个task时会创建下一个stage的文件,运行完之后,会运行下一批次的2个task,而这一批次的task则不会创建新的文件,会复用上一批次的task创建的文件
第二stage的task在拉取上一个stage创建的文件时就不会拉取那么多文件了,而是拉取少量文件,每个输出文件都可能包含了多个task给自己的map端输出
shuffle调优之map端内存缓冲和reduce内存占比
默认情况下:
每个task的内存缓冲为32kb,reduce端内存占比为0.2(即默认executor内存中划分给reduce task的微20%)
所以在不调优的情况下,如果map端task处理的比较大,内存不足则溢满写入磁盘
比如:
每个task就处理320kb,32kb,总共会向磁盘溢写320 / 32 = 10次。
每个task处理32000kb,32kb,总共会向磁盘溢写32000 / 32 = 1000次。
同理,ruduce端也一样
何时调优?
通过Spark UI查看shuffle磁盘的read和write是不是很大,如果很大则应相应调优
如何调优?
spark.shuffle.file.buffer : 32kb -> 128kb
spark.shuffle.memoryFraction: 0.2 -> 0.3- 1
- 2
10. Spark算子调优之MapPartitions
MapPartitions提升Map类操作性能
spark中,最基本的原则是每个task处理一个RDD的partition
如果是普通的Map,假如一个partition中有一万条数据,那么map中的function就要执行和计算一万次,但是使用MapPartitions操作之后,一个task只会执行一次function,function一次接收了所有partition数据,性能比较高
MapPartitions的缺点:
如果是普通的Map,一条一条处理数据,当出现内存不够的情况时,那么就可以将已经处理掉的数据从内存里面垃圾回收掉,所以普通map通常不会出现OOM情况
如果是MapPartitions,对于大量数据来说,如果一个partiton数据有一百万条,一次性传入function之后,可能导致内存不足,但是又没办法腾出空间,直接就导致了内存溢出,OOM
所以,当使用MapPartitons算子时,要估算每个partiton的数据能不能一下子缓存到分配给executor的内存中,如果可以,就是用该算子,对性能有显著提升
11. Spark算子调优之filter过后使用coalesce减少分区数量
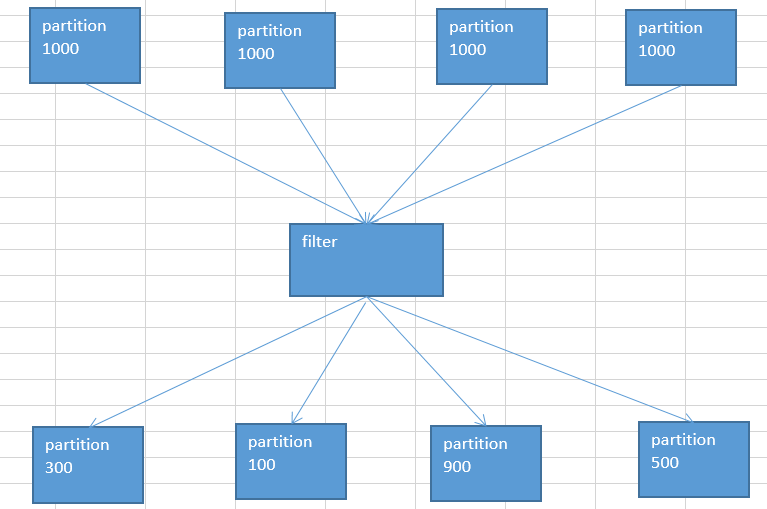
spark程序,通常情况下,RDD在经过filter之后,会出现两个情况:
每个partition内的数据可能就不太一样,有的很多有的很少
这样会导致后面在处理这些partition数据的时候,每个task处理的数据量相差悬殊,最终导致很严重的问题->数据倾斜partition数据量减少
由于partition数据量减少,但是在后面进行处理的时候,还是按照跟partition相同数量的task来进行处理,这就导致的资源浪费
针对上面两个问题,需要使用coalesce算子来处理,该算子能压缩partiton的数量,减少partiton的数据量,而且让每个partition的数据量都尽量均衡紧凑,从而便于后续task进行处理,从某种程度上提升spark程序的性能
12. Spark算子调优之foreachPartition优化写数据库性能
foreach是对每条数据进行处理的,task对partition中的每一条数据都会执行function操作,如果function中有写数据库的操作,那么有多少条数据就会创建和销毁多少个数据库连接,这对性能的影响很大
在生产环境中,通常都是使用foreachPartition来写数据库的,使用了该算子之后,对于用户自定义的function函数,就调用一次,一次传入一个partition的所有数据,这里只需创建一个数据库连接,然后向数据库发送一条sql语句外加多组参数即可,但是这个时候要配合数据库的批处理
同样,该算子在超大数据量面前同样会出现OOM情况
13. Spark算子调优之使用repartition解决SparkSQL低并行度性能问题
通常情况下,在上面第二条的并行度调优时,使用spark.default.parallelism来设置并行度,那么这个设置在什么地方有效,什么地方无效?
当程序中没有使用SparkSQL,那么整个sparkapplication的所有stage的并行度都是设置的这个参数,除非使用了coalesce算子缩减过partition.
当程序中使用了SparkSQL,那么SparkSQl的那么stage的并行度无法设置,因为SparkSQL会默认的根据Hive表对应的hdfs文件的block,自动设置SparkSQL那个stage的并行度,所以这就导致出现了用少量task来处理复杂逻辑的情况, 这种情况下,需要使用repartition来设置SparkSQL的并行度,即对从Hive中读取出来的RDD,使用repartiton重新分区为预期的数量来设置并行度
14.Spark算子调优之reduceByKey的本地聚合
reduceByKey相对于普通的shuffle操作(比如groupByKey),它的一个重要特点就是map端的本地聚合,见图: 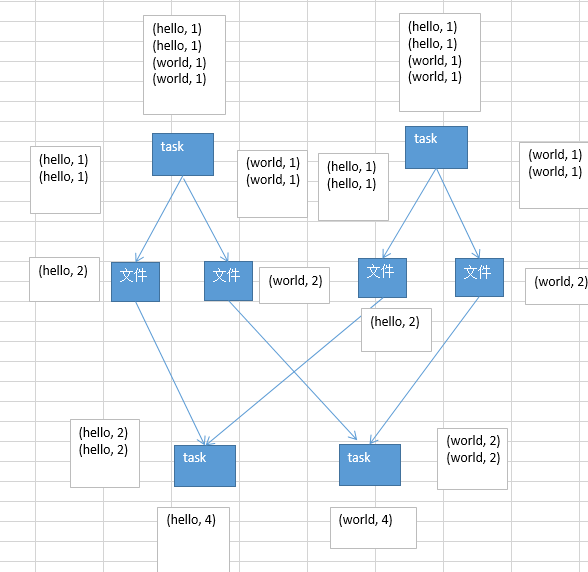
在map端,给下个stage的每个task创建的输出文件中,写数据之前,会进行本地的combiner操作,也就是说,对每一个key,对应的values都会执行用户自定义的算子函数,比如+_,当进行了这个combiner操作之后,减少了数据量,也即是减少了磁盘IO,同时减少了网络传输,对性能有明显提升,所以,在实际的项目中,能用reduceByKey实现的就尽量用该算子实现
数据倾斜
数据倾斜原理及现象分析
数据倾斜是Spark中极其影响性能的现象,它甚至能导致程序无法跑完,更不用提性能调优什么的了
数据倾斜如何产生的?
在shuffle操作的时候,是按照key来进行value的数据的输出,拉取和聚合的,同一个key的values,一定是分配到同一个reduce task进行处理的,假如多个key对应的value一共有90万条数据,但是可能某条key对应了88万条,其他key最多也就对应数万条数据,那么处理这88万条数据的reduce task肯定会特别耗费时间,甚至会直接导致OOM,这就是所谓的数据倾斜
数据倾斜解决方案
1.聚合源数据
Spark的数据源通常情况下都是来自于Hive表,(HDFS或其它大数据分布式系统),而Hive本身就是适合做离线数据分析的,所以说通常要变换一下思路,能在Hive中做聚合的,通常就可以跑定时任务在Hive中做聚合,最终spark拿到的只是每个key对应的一个value值,然后就可以使用map来对这个特殊的value串来处理,省去了groupByKey的过程
2.过滤掉导致倾斜的key
这种情况只适合用户能够接受摒弃某些特殊的数据,比如大部分key都对应了几十万条,而少数key只对应了几十条,那么直接在Hive中过滤掉这些key就从源头上避免了数据倾斜
3.提高shuffle操作reduce端并行度
提高shuffle操作reduce端并行度会有更多task来处理数据,那么每个task处理的数据会相对来说更少一些
如何操作?
给shuffle算子传递进去一个参数,即一个数字,这个数字就代表了shuffle操作时reduce端的并行度,然后在进行shuffle操作的时候,就会对应创建指定数量的reduce task
4.使用随机key实现双重聚合
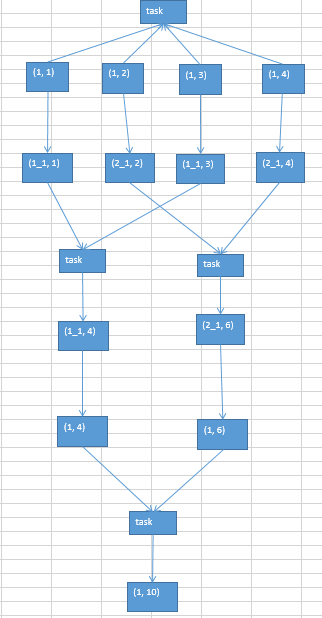
这个场景主要用于reduceByKey,groupByKey,而非join
主要原理就是:
在第一轮聚合时,对key进行打散,将原先一样的key,变成不一样的key,相当于将每个key分组,然后针对key的多个分组,进行key的局部聚合,接着再去掉key的前缀,然后对所有key进行全局聚合,这种方案对解决这两个算子产生的数据倾斜有比较好的效果
5.join算子操作的数据倾斜解决方案
将reduce join转换为map join
示例代码:
List<Tuple2<Long, Row>> userInfos = userid2InfoRDD.collect();
final Broadcast<List<Tuple2<Long, Row>>> userInfosBroadcast = sc.broadcast(userInfos);
JavaPairRDD<String, String> sessionid2FullAggrInfoRDD = userid2PartAggrInfoRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
// 得到用户信息map
List<Tuple2<Long, Row>> userInfos = userInfosBroadcast.value();
Map<Long, Row> userInfoMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> userInfo : userInfos) {
userInfoMap.put(userInfo._1, userInfo._2);
}
// 获取到当前用户对应的信息
String partAggrInfo = tuple._2;
Row userInfoRow = userInfoMap.get(tuple._1);
String sessionid = StringUtils.getFieldFromConcatString(
partAggrInfo, "\\|", Constants.FIELD_SESSION_ID);
int age = userInfoRow.getInt(3);
String professional = userInfoRow.getString(4);
String city = userInfoRow.getString(5);
String sex = userInfoRow.getString(6);
String fullAggrInfo = partAggrInfo + "|"
+ Constants.FIELD_AGE + "=" + age + "|"
+ Constants.FIELD_PROFESSIONAL + "=" + professional + "|"
+ Constants.FIELD_CITY + "=" + city + "|"
+ Constants.FIELD_SEX + "=" + sex;
return new Tuple2<String, String>(sessionid, fullAggrInfo);
}
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
原理图: 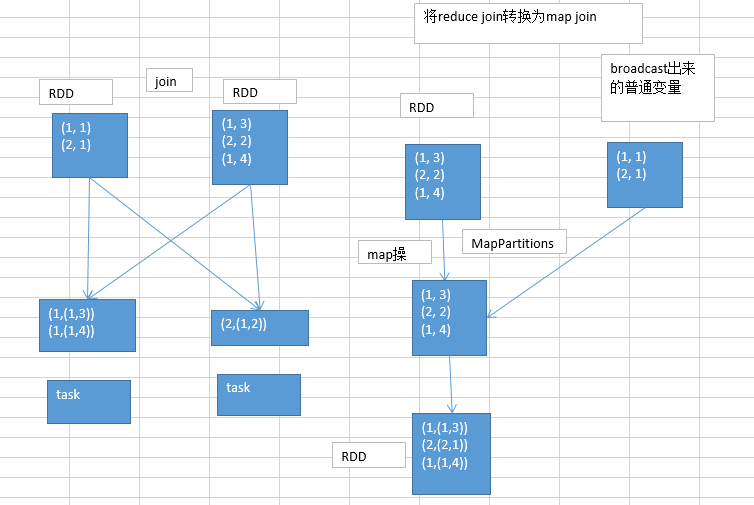
说明:
普通的join,肯定是要走shuffle,那么,既然走shuffle,那么普通的join肯定是reduce join, 即将所有相同的key对应的values,聚合到一个task中,再进行join操作
那么如何将reduce join转换为map join?
当两个RDD要进行join时,其中一个RDD是比较小的,那么就可将该小数据量RDD广播出去,该RDD数据将会在每个executor的blockmanager中驻留一份数据,然后在map操作中就可以使用该数据,这种方式下,根本就不会发生shuffle操作,从而从根本上杜绝了数据倾斜
sample采样倾斜key进行两次join
示例代码
JavaPairRDD<Long, String> sampledRDD = userid2PartAggrInfoRDD.sample(false, 0.1, 9);
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> computedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = computedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
JavaPairRDD<Long, String> skewedRDD = userid2PartAggrInfoRDD.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
JavaPairRDD<Long, String> commonRDD = userid2PartAggrInfoRDD.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
JavaPairRDD<String, Row> skewedUserid2infoRDD = userid2InfoRDD.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
int prefix = random.nextInt(100);
list.add(new Tuple2<String, Row>(prefix + "_" + tuple._1, tuple._2));
}
return list;
}
});
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
}).join(skewedUserid2infoRDD).mapToPair(
new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long userid = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(userid, tuple._2);
}
});
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(userid2InfoRDD);
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
JavaPairRDD<String, String> sessionid2FullAggrInfoRDD = joinedRDD.mapToPair(
new PairFunction<Tuple2<Long,Tuple2<String,Row>>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(
Tuple2<Long, Tuple2<String, Row>> tuple)
throws Exception {
String partAggrInfo = tuple._2._1;
Row userInfoRow = tuple._2._2;
String sessionid = StringUtils.getFieldFromConcatString(
partAggrInfo, "\\|", Constants.FIELD_SESSION_ID);
int age = userInfoRow.getInt(3);
String professional = userInfoRow.getString(4);
String city = userInfoRow.getString(5);
String sex = userInfoRow.getString(6);
String fullAggrInfo = partAggrInfo + "|"
+ Constants.FIELD_AGE + "=" + age + "|"
+ Constants.FIELD_PROFESSIONAL + "=" + professional + "|"
+ Constants.FIELD_CITY + "=" + city + "|"
+ Constants.FIELD_SEX + "=" + sex;
return new Tuple2<String, String>(sessionid, fullAggrInfo);
}
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
这个方案的实现思路关键之处在于:
将发生数据倾斜的key单独拉出来,放到一个RDD中,然后用这个原本会产生数据倾斜的key RDD和其他RDD单独去join一下,这个时候,key对应的数据,可能就会分散到多个task中进行join操作
,如果该倾斜key与其他key混合在一起中,肯定会导致这个key对应的所有数据都聚合到一个task中,然后导致数据倾斜 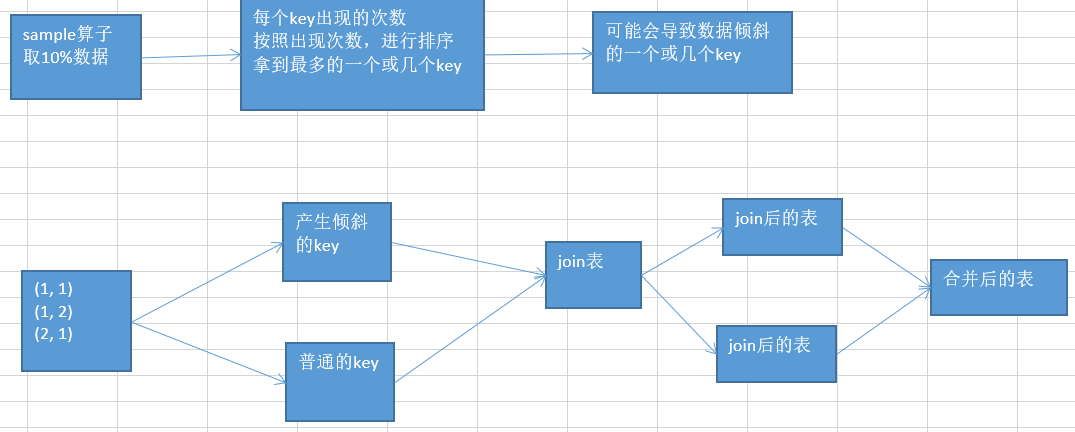
最后,当取出来这个倾斜key之后,还可以通过增加随机数前缀的方法进行优化,如上面代码中:
针对取出来的这个数据倾斜key,从它要join的另一个RDD中过滤出来此key对应的数据,有可能只有一条,那么就为该条数据的RDD使用flatmap算子,打上100个随机数,作为前缀,返回一百条数据,然后对该数据倾斜key的RDD,给每条数据也打上一个100以内的随机数作为前缀,再去join操作,性能会提升很多,join之后使用map操作去除前缀,然后再与非倾斜key join的结果进行union,即可得到预期结果
注意:当数据中产生数据倾斜的key很多时,就不适合使用这种方案了,需要考虑下一种方案
使用随机数以及扩容表近join
该方案其实对数据倾斜的一种缓解,而非解决,它的思路是:
选择一个RDD,使用flatmap进行扩容,将每条数据映射为多条数据,每个映射出来的数据,都带了一个n以内的随机数,通常是10以内的,对另外一个RDD,做普通的map映射操作,每条数据都打上10以内的随机数,然后将两个处理后的RDD,进行join操作
示例代码
JavaPairRDD<String, Row> expandedRDD = userid2InfoRDD.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 10; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
JavaPairRDD<String, String> mappedRDD = userid2PartAggrInfoRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
JavaPairRDD<String, String> finalRDD = joinedRDD.mapToPair(
new PairFunction<Tuple2<String,Tuple2<String,Row>>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
String partAggrInfo = tuple._2._1;
Row userInfoRow = tuple._2._2;
String sessionid = StringUtils.getFieldFromConcatString(
partAggrInfo, "\\|", Constants.FIELD_SESSION_ID);
int age = userInfoRow.getInt(3);
String professional = userInfoRow.getString(4);
String city = userInfoRow.getString(5);
String sex = userInfoRow.getString(6);
String fullAggrInfo = partAggrInfo + "|"
+ Constants.FIELD_AGE + "=" + age + "|"
+ Constants.FIELD_PROFESSIONAL + "=" + professional + "|"
+ Constants.FIELD_CITY + "=" + city + "|"
+ Constants.FIELD_SEX + "=" + sex;
return new Tuple2<String, String>(sessionid, fullAggrInfo);
}
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
该方案的缺点就是,因为我们本身的RDD数据量非常大,无法进行大量扩容,一般也就10倍,所以这个方案也仅仅对数据倾斜起到了缓解作用
troubleshooting
troubleshooting之控制shuffle reduce端缓冲大小以避免OOM
Map端的task是不断的输出数据的,数据量可能是很大的,但是Reduce端的task并不是等到map端task将属于自己的那份数据全部写入磁盘文件之后才去拉取的,实际是,map写一点数据,reduce端的task就会去拉取一点数据,然后立即进行后面的聚合,算子函数的应用
Reduce端task每次拉取多少数据是由buffer来决定的,因为拉取过来的数据都是先放在buffer的,然后才用后面的executor分配的堆内存占比
那么问题就出在这个buffer上面:
该buffer默认为48M,大部分情况下,reduce task不会拉取很多的数据,一般10M左右就计算处理了,所以大多数时候,不会出现什么问题,但是有的时候,map端数据量非常大,写出的速度特别快,reduce端的所有task拉取数据的时候,全部达到自己缓冲的极限值,也就是48M全部填满,这个时候,再加上聚合函数的代码,可能会创建大量的对象,可能一下子会把内存爆掉,导致程序直接崩溃
针对这个情况,就应该减少reduce端task缓冲的大小,宁愿多拉取几次,也不一下子拉取很多数据,牺牲性能换取执行
换言之,当集群资源充足,map端数据量又不是很大的情况下,就可以考虑调大此缓冲大小来提高性能
调节方式:
spark.reducer.maxSizeInFlight,48
spark.reducer.maxSizeInFlight,24- 1
- 2
troubleshooting之解决JVM的GC导致拉取文件失败
在Spark作业中,有一种错误非常普遍,即shuffle file not found......
解析:
executor的JVM进程,可能内存不够,那么此时就会执行GC,minorGC 和 FullGC,无论哪种,一旦发生了GC,就会导致executor内,所有的工作线程全部停止,比如BlockManager,基于netty的网络通信,而下一个stage的executor可能还没有停止掉,task想要去上一个stage的的task所在的executor去拉取属于自己的数据,结果由于对方在GC,就导致了拉取了半天的数据没有拉取到,就直接报出shuffle file not found...的错误,可能下一个stage又重新提交了stage或task之后,再执行就没有问题了
如何避免上述情况呢? 两个参数:
spark.shuffle.io.maxRetries 3
spark.shuffle.io.retryWait 5s- 1
- 2
第一个参数的意思是shuffle文件拉取的时候,如果没有拉取到或拉取失败,最多会重试几次,第二个参数的意思是每一次重新拉取文件的时间间隔是5s
所以说,当上一个stage的executor正在发生漫长的FullGC,导致第二个stage的executor尝试去拉取文件,而拉取不到,默认情况下,会反复重试3次,每次间隔是5秒钟,最多只会等待3*5=15秒,如果15秒没有拉取到数据,就会报出shuffle file not found... 错误
所以当程序频繁报该错误时,需要调节大这两个参数
troubleshooting之解决YARN队列资源不足导致的Application连接失败
当提交一个Spark程序时,如果没有足够的资源,一般会出现两种情况(根据集群的配置,hadoop的版本等情况不同):
一是Yarn发现资源不足时,不会Hang在那里,而是直接打印fail日志,直接fail
二是Yarn发现资源不足,会Hang在那里直到有足够的资源来执行
另外,当某个spark程序耗时比较长时,如果在同一个队列中再提交一个耗时短的spark程序,那么耗时短的会等很长时间,会很不合适,所以要考虑多个调度队列
在CDH集群中,可以设置多个调度队列,动态资源选项新建,然后在J2EE中,通过线程池的方法(一个线程池对应一个资源队列)来实现上述方案
ExecutorService threadPool = Executors.newFixedThreadPool(1);
threadPool.submit(new Runnable() {
@Override
public void run() {
}
});- 1
- 2
- 3
- 4
- 5
- 6
troubleshooting之解决各种序列化导致的报错
序列化报错的出现:当用client模式去提交spark作业,查看本地打印出来的log,如果出现了Serializable,Serialize等字眼,那么就是序列化导致的报错
处理方法:
1.算子函数里面如果使用到了外部自定义类型的变量,那么自定义的类型必须是可序列化的
2.如果要将自定义的类型作为RDD的元素类型,那么自定义的类型必须也是可序列化的
JavaPairRDD<Integer, Teacher> teacherRDD
JavaPairRDD<Integer, Student> studentRDD
studentRDD.join(teacherRDD)
public class Teacher implements Serializable {
}
public class Student implements Serializable {
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.不能在上述两种情况下,使用一些第三方的,不支持序列化的类型
比如Connection conn = ....
troubleshooting之解决算子函数返回NULL导致的问题
在某些算子函数里面,是需要有一个返回值的,但是有时候我们不想有返回值,如果直接返回NULL的话,会报错的,遇到这种情况,在返回的时候,需要返回一些特殊值,比如”-999”,那么通过这个算子得到的RDD,再经过filter过滤操作,过滤掉就可以了
troubleshooting之解决yarn-client模式导致的网卡流量激增问题
当使用yarn-client模式提交spark程序时,driver是启动在本地机器的,而且driver是全权负责所有的任务的调度的,也就是说,要跟yarn集群上运行的多个executor进行频繁的通信,有可能导致网卡流量激增,那么解决办法就是使用yarn-cluster模式,这样就不是本地的机器的driver来进行task调度了
troubleshooting之解决yarn-cluster模式的JVM内存溢出无法执行问题
有的时候,运行一些包含了sparkSQL的spark作业,可能会碰到yarn-client模式下提交可以正常运行,但是yarn-cluster模式下可能无法运行,报出JVM的PermGen永久代的内存溢出,即OOM
出现这种情况的原因:
yarn-client模式下,driver是运行在本地机器上的,spark使用的JVM的PermGen的配置,是本地的spark-class文件(spark客户端默认是有配置的),JVM永久代的大小是128M,但是在yarn-cluster模式下,driver是运行在集群的某个节点上的,使用的是没有经过配置的默认值82M
sparkSQL,它的内部是要进行很复杂的SQL的语义解析,语法树的转换等等,特别复杂,在这种复杂的情况下,如果说sql本身特别复杂的话,很可能会导致性能的消耗,内存的消耗,对PermGen占用比较大,所以会出现这种情况
如何解决这种情况:
//yarn-cluster模式下
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"- 1
- 2
最后
sparkSQL,如果有大量的or语句,比如有成百上千的时候,此时可能就会出现一个driver端的jvm stack overflow,即JVM栈内存溢出的问题
JVM栈内存溢出,基本上就是由于调用的方法层级过多,因为产生了大量的,非常深的,超出了JVM栈深度限制的递归,所以这个时候可能要将sql语句拆分为多个sql子句来执行
troubleshooting之错误的持久化方式及checkpoint的使用
持久化方式
userRDD,如果想要对这个RDD做一个cache,希望能在后面多次使用这个RDD的时候,不用反复重新计算RDD,而是可以直接使用各个节点的executor的BlockManager管理的内存/磁盘上的数据
错误方式:
uesrRDD.cache()
userRDD.count()
userRDD.take()- 1
- 2
- 3
上面会持久化方式不会生效,反而会报file not found的错误
正确方式:
userRDD=userRDD.cache()
val cacheuserRDD=userRDD.cache()- 1
- 2
checkpoint使用
1.在代码中,用SparkContext设置一个checkpoint目录,可以是一个容错文件系统的目录,比如HDFS
2.在代码中,对需要进行checkpoint的RDD,执行RDD.checkpoint()
3.RDDCheckpointData(Spark内部的API),会接管该RDD,标记为marked for checkpoint,准备进行checkpoint
4.job运行完之后,会调用一个finalRDD.doCheckpoint()方法,会顺着RDD lineage,回溯扫描,发现有标记为待checkpoint的RDD,就会进行二次标记,inProgressCheckpoint,即正在接受checkpoint操作
5.job运行完后,会启动一个内部的新的job,去将标记为inProgressCheckpoint的RDD的数据,都写入hdfs文件中(如果rdd之前cache过,会直接从缓存中获取数据,写入hdfs中,如果没有cache过,那么就会重新计算一遍这个RDD,再checkpoint)
6.将checkpoint过的RDD之前的依赖RDD,改成一个CheckpointRDD*,强制改变RDD的lineage,后面如果RDD的cache数据获取失败,直接会通过它的上游CheckpointRDD,去容错的文件系统中,比如hdfs,获取Checkpoint数据
Checkpoint其实是cache的一个备胎