Python之数据处理案例
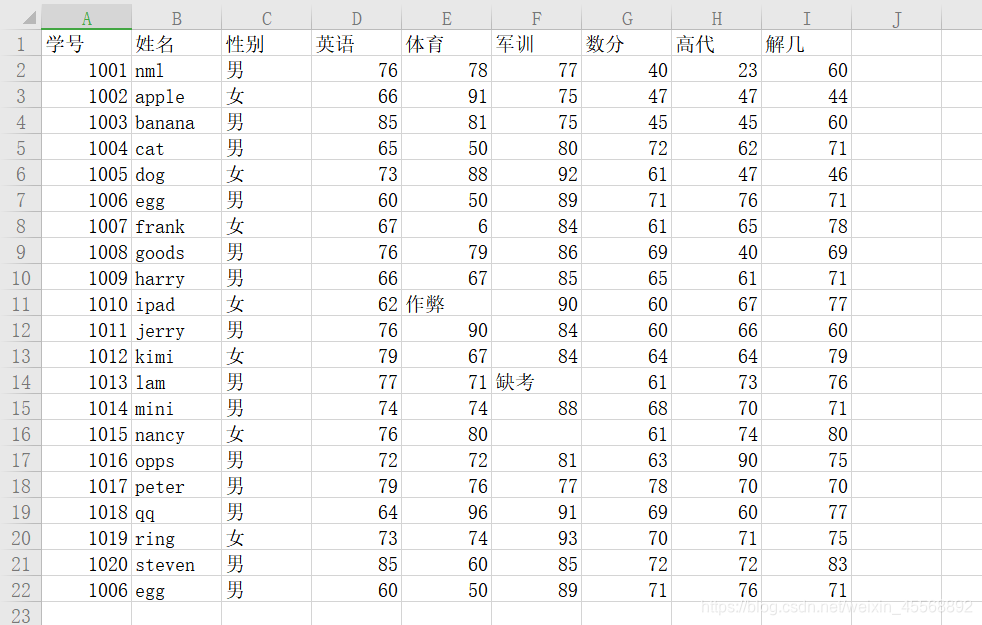
1 准备数据
2 要求
(1)将数据表添加两列:每位同学的各科成绩总分(score)和每位同学的整体情况(类别),类别按照[df.score.min()-1,400,450,df.score.max()+1]分为“一般” “较好” “优秀”三种情况。
(2)由于“军训 ”这门课的成绩与其他科目成绩差异较大,并且给分较为随意,为了避免给同学评定奖学金带来不公平,请将每位同学的各科成绩标准化,再汇总,并标出“一般” “较好” “优秀”三种类别。
3 代码实现
1、导入数据,并查看数据的“形状”
import pandas as pd
df=pd.read_excel(r'C:\Users\70464\Desktop\4.6带你飞-学习成绩.xls')
df.shape
(21, 9)2、对数据进行查找重复操作
df.duplicated().tail()
16 False
17 False
18 False
19 False
20 True
dtype: booldf[df.duplicated()]
学号 姓名 性别 英语 体育 军训 数分 高代 解几
20 1006 egg 男 60 50 89 71 76 71df1=df.drop_duplicates()
df1.shape
(20, 9)3、查看空数据
#查看空值返回的是逻辑真、假数据矩阵,为了方便,取后5行显示
df.isnull().tail() df1.isnull().any() #判断哪些列存在缺省值
学号 False
姓名 False
性别 False
英语 False
体育 False
军训 True
数分 False
高代 False
解几 False
dtype: booldf1[df1.isnull().values==True] #显示存在缺省值的行df2 = df1.fillna(0) # 将空数据填充为0
df2.tail(8) #查看后8行数据4、处理数据中的空格
空格会影响我们后续数据的统计和计算。去除空格的方法有三种:第一种是去除数据两边的空格(str.strip),第二种是单独去除左边的空格(str.lstrip),第三种是单独去除右边的空格(str.rstrip)。代码如下:
df0 = df2.copy() # 为了数据安全先复制一遍
df0['解几'] = df2['解几'].astype(str).map(str.strip)5、查看列数据类型
查看数据框各列中的数据类型,是否是int,若不是则需要处理。对于数据类型不一致的列抛出列名,以便进一步对此列数据进行处理。
for i in list(df0.columns):
if df0[i].dtype=='O': #若某列全部是int,则显示该列为int类型,否则为object
print(i)
姓名
性别
体育
军训
解几#查看“解几”列的数据类型为object
df0['解几'].dtype
dtype('O')df0['解几'] = df2['解几'].astype(int) #将“解几”列转换为int
df0['解几'].dtype #查看“解几”列的数据类型为int
dtype('int32')6、以0值填充非int型数据
以“体育”列为例,将“体育”列中的值进行遍历,若不是int格式,就替换为0,并显示其行号。
ty = list(df0.体育)
j=0
for i in ty:
if type(i) != int:
print('第'+str(ty.index(i))+'行有非int数据:',i)
ty[j]=0
j =j+1
第9行有非int数据: 作弊ty #查看index=9的行数据“作弊”是否替换成了0
[78, 91, 81, 50, 88, 50, 6, 79, 67, 0, 90, 67, 71, 74, 80, 72, 76, 96, 74, 60]df0['体育'] = ty #再将替换过的ty放回原df0列中jx = list(df0.军训)
k=0
for i in jx:
if type(i) != int:
print('第'+str(jx.index(i))+'行有非int数据:',i)
jx[k] = 0
k = k+1
df0['军训'] = jx
第12行有非int数据:缺考df07、对问题1的处理
下面可以对该数据框进行统计了。先计算每位同学的总分,再排出“一般” “较好” “优秀”三种类别。
df3 = df0.copy()
df3['score']=df3.英语+df3.体育+df3.军训+df3.数分+df3.高代+df3.解几
df3.score.describe()
count 20.000000
mean 410.500000
std 38.051904
min 354.000000
25% 370.750000
50% 416.000000
75% 446.250000
max 457.000000
Name: score, dtype: float64# 分组的区域划分
bins = [df3.score.min()-1,400,450,df3.score.max()+1]
label = ["一般","较好","优秀"]
df4 = pd.cut(df3.score,bins,right=False,labels=label)
df3['类别'] = df4
df38、对问题2的处理
基于问题1的方法,这一步主要是把清洗干净的数据df0的每列数据进行标准化,之后继续使用问题1的方法即可。
for i in list(df0.columns[3:]):
df0[i]=(df0[i]-df0[i].min())/(df0[i].max()-df0[i].min())
df0.tail()df0['score']=df0.英语+df0.体育+df0.军训+df0.数分+df0.高代+df0.解几
# 查看score的最大、最小值以及总记录数等信息
df0.score.describe()
count 20.000000
mean 3.863515
std 0.681950
min 2.536788
25% 3.487306
50% 3.773113
75% 4.431060
max 5.112427
Name: score, dtype: float64bins=[df0.score.min()-1,3,4,df0.score.max()+1]
label = ["一般","较好","优秀"]
df_0 = pd.cut(df0.score,bins,right=False,labels=label)
# 在df0中增加一列“类别”,用df_0赋值
df0['类别']=df_0
df0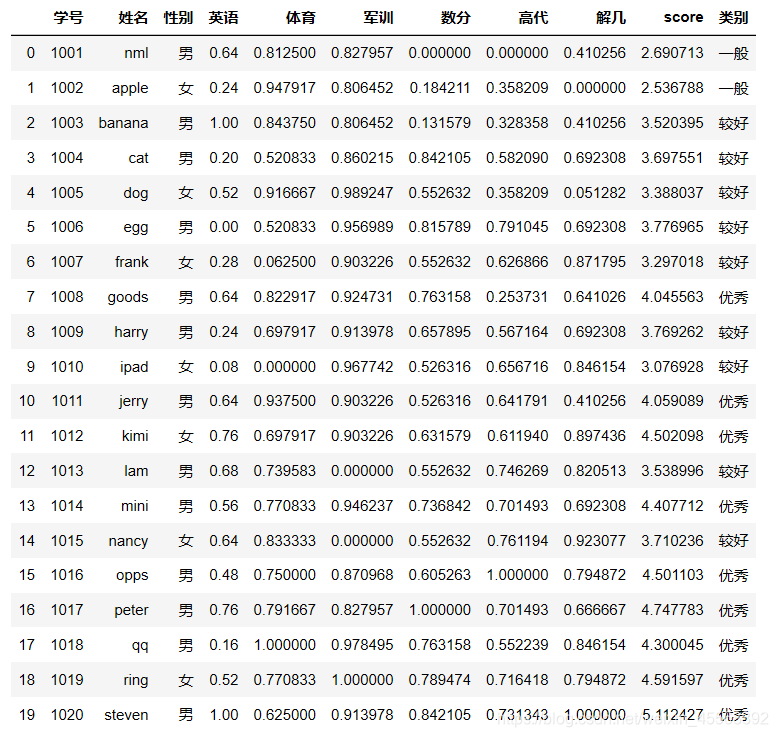
4 参考文献
《基于Python的大数据分析基础及实战》
